





数据库
1. 查看现有数据库
SHOW DATABASES;
2. 新建数据库
CREATE DATABASE ;
3. 选择数据库
USE ;
4. 从.sql文件引入SQL语句
SOURCE <.sql>;
5. 删除数据库
DROP DATABASE ;
表
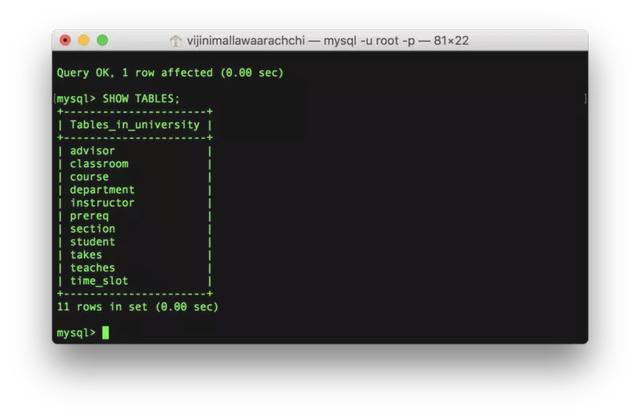
6. 查看当前数据库中的表
SHOW TABLES;
7. 创建新表
CREATE TABLE ( , , , PRIMARY KEY (), FOREIGN KEY () REFERENCES ());主键(PRIMARY KEY)用来标识一条记录(一行),所以每条记录的主键值必须是唯一的。主键可以定义在多列上,这称为联合主键(composite primary key)。
如果我们把表视作具有某种结构的数组(例如,C语言中的struct),那么外键(FOREIGN KEY)可以视作指针。
例子:
CREATE TABLE instructor ( ID CHAR(5), name VARCHAR(20) NOT NULL, dept_name VARCHAR(20), salary NUMERIC(8,2), PRIMARY KEY (ID), FOREIGN KEY (dept_name) REFERENCES department(dept_name));在上面的例子中,我们创建了一个教员(instructor)表,该表的主键是ID,外键是教员所在的部门名称(dept_name),关联部门(department)表。此外,教员表还包括姓名(name)、薪水(salary)。其中,姓名有约束NOT NULL,表示姓名这一项不能为空。
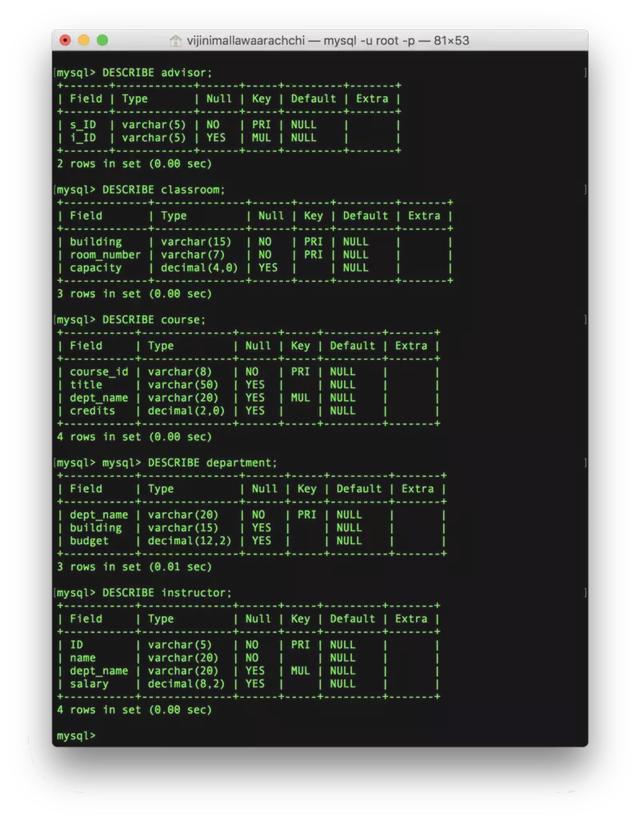
8. 概述表中的列
使用如下语句查看表中的列的基本信息:
DESCRIBE ;
下图显示了一些例子:
9. 在表中插入新纪录
INSERT INTO (, , , …)VALUES (, , , …);
也可以省略列名(依序在所有列上插入新值):
INSERT INTO VALUES (, , , …);
10. 在表中更新记录
UPDATE SET = , = , ... WHERE ;11. 清空表
DELETE FROM ;
12. 删除表
DROP TABLE ;
查询
13. SELECT
SELECT语句可以从表中选择数据:
SELECT , , … FROM ;以下语句选择所有内容:
SELECT * FROM ;
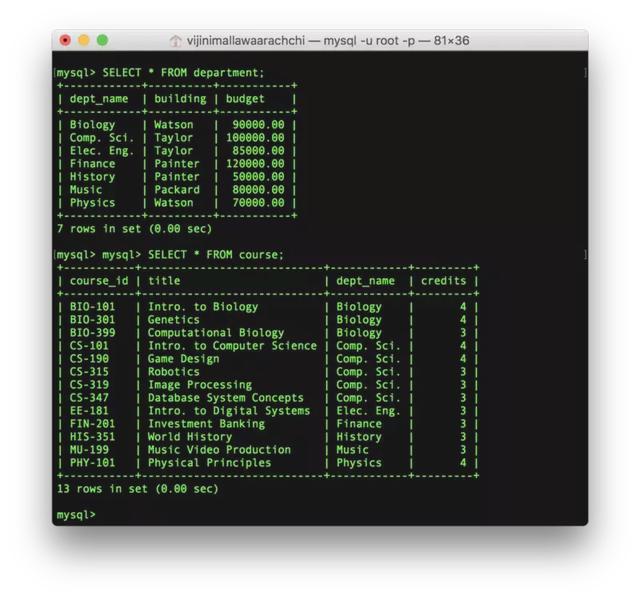
artment)表和课程(course)表中的所有内容14. SELECT DISTINCT
SELECT DISTINCT过滤掉了重复的值:
SELECT DISTINCT , , … FROM ;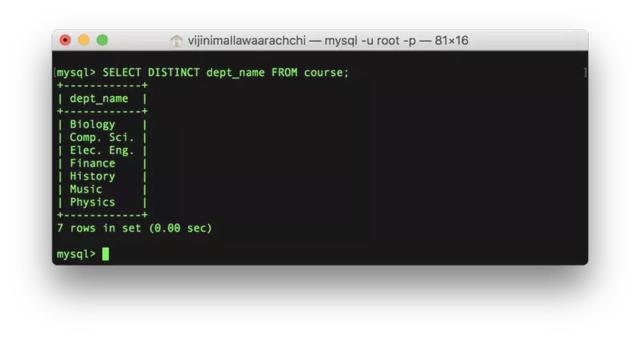
15. WHERE
我们之前在更新记录时已经用到了WHERE关键字,用来指明条件。这里我们稍微详细一点地介绍下WHERE。
WHERE的条件通常是:
- 比较文本(text)
- 比较数字(numbers)
- AND、OR、NOT等逻辑运算
让我们来看一些例子:
SELECT * FROM course WHERE dept_name='Comp. Sci.';SELECT * FROM course WHERE credits>3;SELECT * FROM course WHERE dept_name='Comp. Sci.' AND credits>3;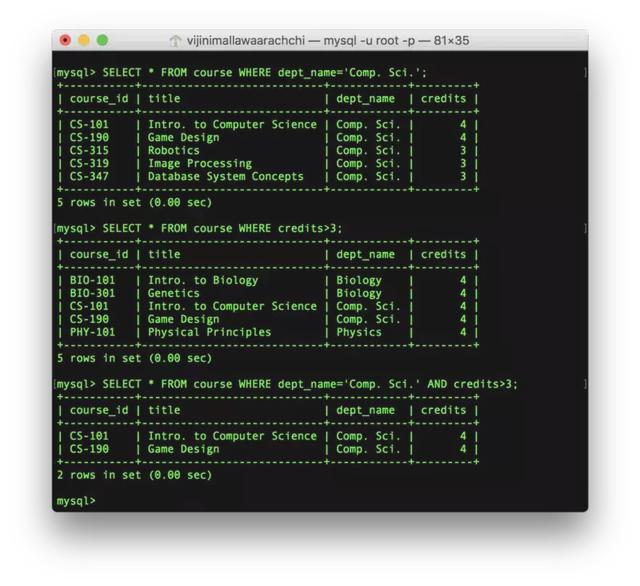
16. GROUP BY
GROUP BY语句可以分组结果,常用于COUNT、MAX、MIN、SUM、AVG等聚合函数(aggregate functions)。
SELECT , , … FROM GROUP BY ;让我们来看一个例子,列出每个部门的课程数量:
SELECT COUNT(course_id), dept_name FROM course GROUP BY dept_name;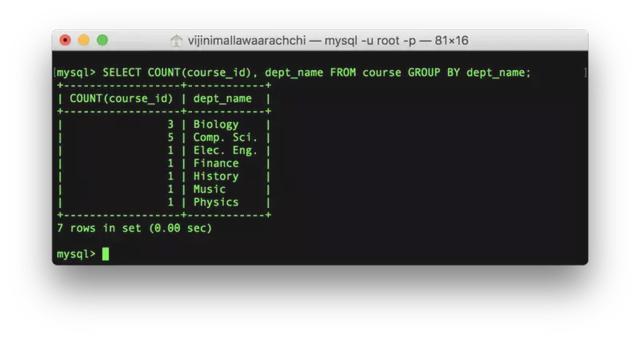
17. HAVING
乍看起来,HAVING和WHERE很像:
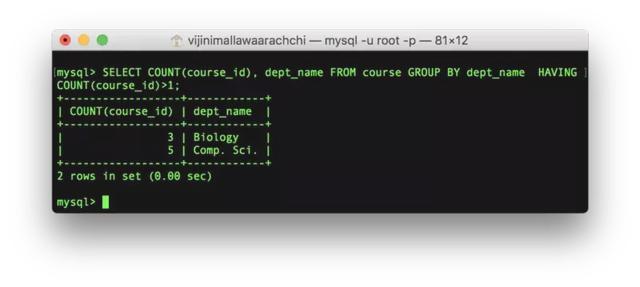
SELECT , , … FROM GROUP BY HAVING ;那么,HAVING和WHERE有什么不同呢?让我们先来看一个例子,列出开了不止一门课程的部门开设的课程数:
SELECT COUNT(course_id), dept_name FROM course GROUP BY dept_name HAVING COUNT(course_id)>1;这里HAVING不能换成WHERE,因为WHERE直接针对行操作,且在GROUP BY之前运行(即先通过WHERE筛选行,之后再将筛选出的行通过GROUP BY分组)。假设SQL中不存在HAVING语句,那么我们只能先新建一张表,将COUNT(course_id)作为新表的列,然后在新表上再通过WHERE进行筛选(当然,实际上SQL提供了派生表、CTE等机制,并不用真的手工建新表)。
18. ORDER BY
ORDER BY可以对结果进行排序,在没有明确指定ASC(升序)或DESC(降序)的情况下,默认按升序排列。
SELECT , , …FROM ORDER BY , , …, ASC|DESC;例子:
SELECT * FROM course ORDER BY credits;SELECT * FROM course ORDER BY credits DESC;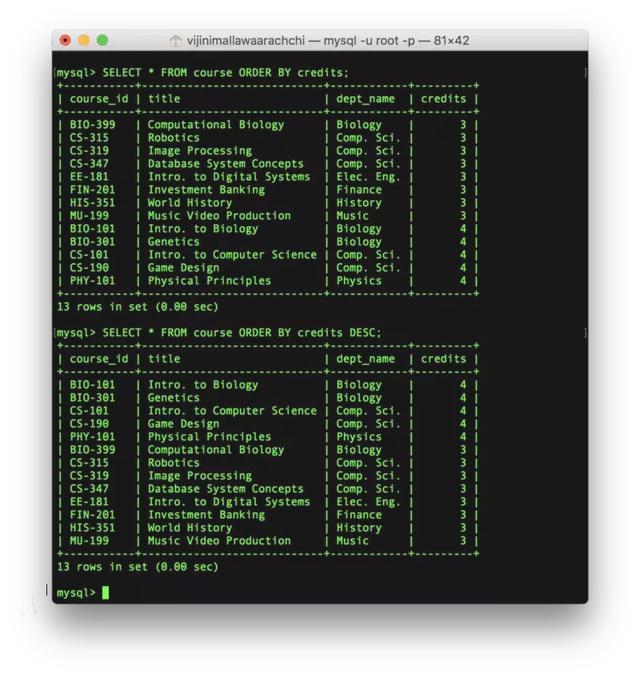
19. BETWEEN
BETWEEN语句用于指定区间。
SELECT , , … FROM WHERE BETWEEN AND ;其中“值”可能是数字,文本,乃至日期等。
例如,列出薪资在50000和100000之间的教员:
SELECT * FROM instructor WHERE salary BETWEEN 50000 AND 100000;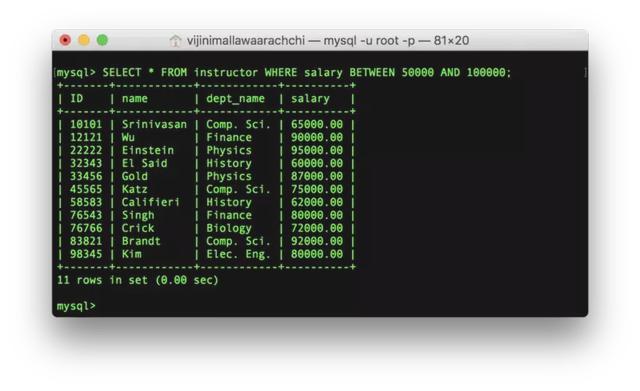
20. LIKE
LIKE用于匹配文本中的特定模式。
SELECT , , … FROM WHERE LIKE ;模式中可以使用以下两个通配符:
- % (零个、一个或多个字符)
- _ (单个字符)
例子:列出课程名中包含“to”的课程,以及课程ID以“CS-”开头的课程。
SELECT * FROM course WHERE title LIKE '%to%';SELECT * FROM course WHERE course_id LIKE 'CS-___';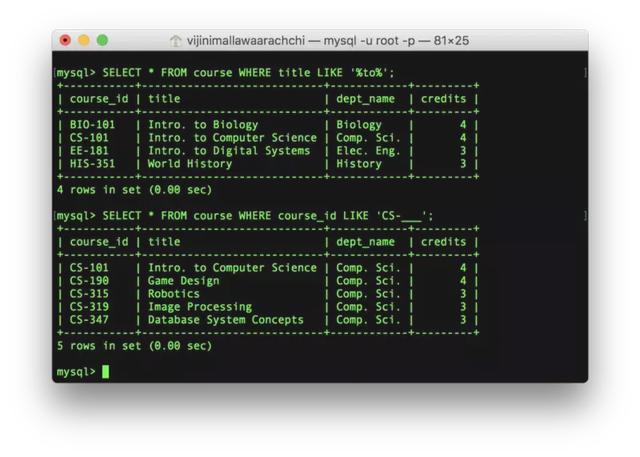
21. IN
IN语句表示值属于某个集合。
SELECT , , … FROM WHERE IN (, , …);例子:列出计算机科学、物理、电子工程部门的学生。
SELECT * FROM student WHERE dept_name IN ('Comp. Sci.', 'Physics', 'Elec. Eng.');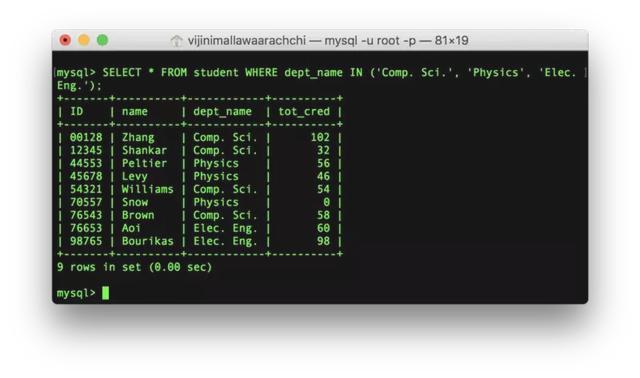
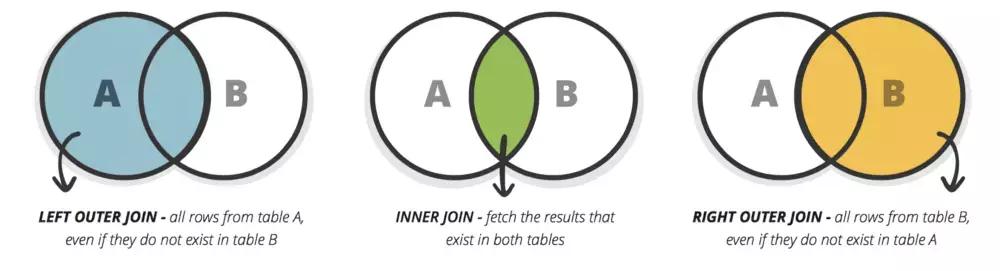
22. JOIN
JOIN用来组合两张以上表中的值。下图展示了JOIN的三种类型:















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









