





文本大数据分析在社科学术研究中的应用方兴未艾。本文以搜集长沙市历年政府工作报告,并统计其中与环境规制相关的词汇出现频次这一问题为例,基于python3,介绍网络爬虫和文本分析的基本工作原理,算法设计和实践操作。
问题
- 笔者在研究环境规制对出口企业行为的影响时,在计量分析中需要为地区环境规制指标选取一个合适的工具变量,以解决内生性问题。
- 现有文献(Chen et al.(2016)、陈诗一和陈登科(2018)等)指出,省级政府工作报告中与环保相关的词汇出现的频次可以作为地区环境规制的工具变量。
- 我们采用这一方法,并作出改进:直接以地级市政府工作报告为分析样本,并扩充进行统计的与环保相关的词汇数量。
- 由于需要搜集和处理的数据信息较多,人工手动处理的花费较大,考虑利用python抓取数据并进行自动分析。
- 最后得到的数据应该是:①各年度地级市环境规制力度指标;②各年度政府工作报告(存档备查)

一、利用爬虫获取数据
1. 爬虫是什么?
当前,我们处在大数据时代,经济社会每天都要产生海量的数据。搜集并利用这些数据,挖掘其中有价值的信息作为决策的参考和依据,成为了现代企业运作的重要手段。
数据如此重要,那么我们通过哪些途径来获取数据呢?
- 企业产生的用户数据:百度指数、淘宝&京东数据、新浪微博数据等
- 数据平台购买数据:知网、wind(万得)、湖大数据中心等
- 政府部门统计数据:统计年鉴、工业企业数据库、海关数据库、世界银行数据库等
- 数据管理咨询公司:麦肯锡、埃森哲、中为咨询、艾瑞咨询等
- 搜集互联网数据:采取合适的技术手段,批量下载和处理互联网数据
不要小看爬虫和文本分析在社科研究中的作用2019年1月21日,麻省理工学院郑思齐副教授和上海财经大学孙聪博士合作在Nature子刊 Nature Human Behaviours杂志发表题为:Air pollution lowers Chinese urbanites’ expressed happiness on social media的论文。该研究使用腾讯公司的自然语言处理平台(NLP)分析来自144个中国城市的带有地理位置的2.1亿条新浪微博和当地的空气污染数据,来调查幸福感是如何随着日常室外空气污染浓度而变化。发现中国高水平的空气污染可能导致城市人群低水平的幸福感。
按照百度百科的定义:爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
简单地说,爬虫是我们在信息化社会中高效获取信息的一门工具
2. 爬虫的工作原理
以抓取网页数据为例:
网页具有以下三点特征:[1]
- 网页都有自己唯一的URL(统一资源命令符,如https://www.baidu.com/)来进行定位
- 网页都使用HTML(超文本标记语言)来描述页面信息
- 网页都使用HTTP/HTTPS(超文本传输协议)协议来传输HTML数据
我的理解:网页用HTML语言进行编写,并将其与一个URL链接。在浏览器中输入URL,将按照超文本传输协获取到这个网页的文本信息(HTML源代码),然后按照规则进行渲染,并呈现给用户最终网页内容。
爬虫的设计思路:
- 首先确定需要爬取的网页URL地址,即http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/
- 打开网页,查看网页源代码,查看其HTML文本信息,明确其中有用的信息以及所在的位置
- 利用合适的工具(Python、Go、R、Stata等),提取HTML页面中的信息
- 利用python包urllib的request命令打开URL,将网页的HTML信息读取到python中
- 利用正则表达式或者``BeautifulSoup``包中的命令,将指定位置中的信息提取出来
c. 清洗数据、分析数据、保存数据
下面将以一个简单的实例,介绍爬虫的工作原理、算法和在python3中的实践操作。
3. 爬虫实例:抓取历年长沙市政府工作报告
3.1 分析网页
打开目标链接
[http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/index.html]
可以在浏览器中看到如下内容:
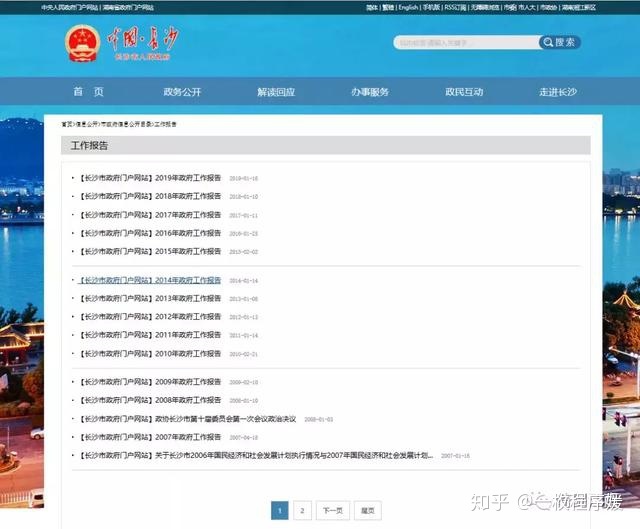
这是一个索引页面,查看网页源代码,可以看到如下内容:

各子条目的信息都写在标签“h4”中,里面有着链接地址和名称。
点开索引页面中的一个链接,如“2019年政府工作报告”,在浏览器中看到如下内容:

页面中政府工作报告的正文就是我们需要提取的内容
同样的,查看其网页源代码,可以看下以下内容:

从图中看到,政府工作报告的正文内容都写在了标签“p”中。
3.2 制定策略
从上文分析来看,这次要抓取的网页结构是比较简单的。索引页面给出了各年度政府工作报告的链接,内容写在了标签“h4”中;而政府工作报告的正文写在了标签“p”中。
因此,可以先读取索引页中的数据,提取”h4“中的内容,为了方便取用和命名,将提取的链接名称与链接地址以”键值对“的形式保存在一个字典中,格式大概如下:
dict = {2019年政府工作报告:链接地址2019,2018年政府工作报告:链接地址2018 ,key3: value3 ··· }
分别提取字典中的各组键值对,读取链接地址中的内容,提取所需要的信息,然后保存为文本文件,并将其命名为该链接地址的键名。
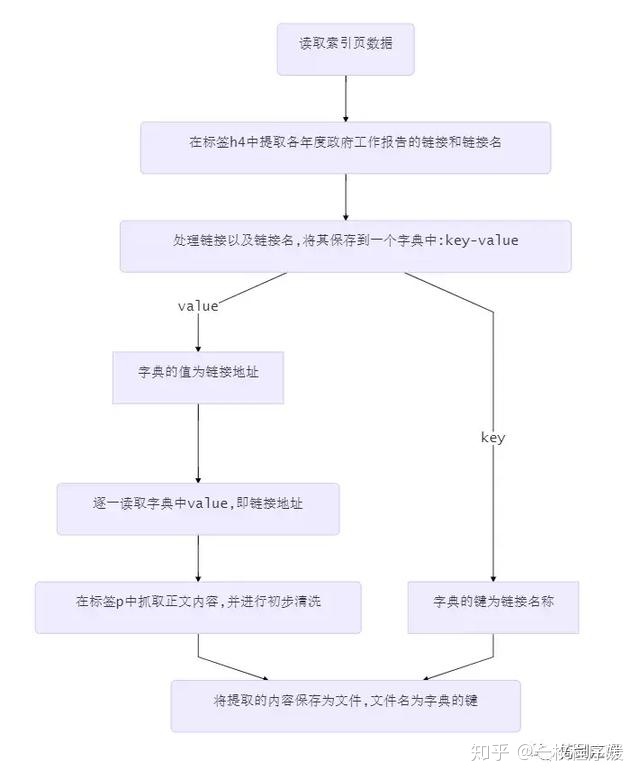
主要的操作的流程图如下所示:
3.3 代码实现
Step1: 用python登录索引页,读取其中的数据
# 载入所需程序包 import urllib import urllib.request mainsite = "http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/index.html" file = urllib.request.urlopen(mainsite) mainpagedata = file.read().decode("utf-8", "ignore") # 在python中查看读取的内容 print(mainpagedata) 执行命令后,python的控制台显示如下内容,这表示python已经成功读取整个索引页的数据内容了。
<!DOCTYPE html> <html lang="en"> <head> # ···(省略部分内容) <meta charset="UTF-8"> <!-- 网站标签 --> <title>长沙市政府首页</title> </head> <body> # ···(省略部分内容) <li> <h4> <a href="./201901/t20190116_3156774.html" target="_blank">【长沙市政府门户网站】2019年政府工作报告</a> <span class="date">2019-01-16</span></h4> </li> <li> <h4> <a href="./201801/t20180110_2162039.html" target="_blank">【长沙市政府门户网站】2018年政府工作报告</a> <span class="date">2018-01-10</span></h4> </li> </li> # ···(省略部分内容) <li> <h4> <a href="./200710/t20071023_118848.html" target="_blank">【长沙市政府门户网站】关于长沙市2006年国民经济和社会发展计划执行情况与2007年国民经济和社会发展计划...</a> <span class="date">2007-01-16</span></h4> </li> Step2: 读取标签”h4“中的内容,并进行处理
from bs4 import BeautifulSoup
# 用beautifulsoup包对网站数据进行解析
mainsoup = BeautifulSoup(mainpagedata, "html.parser")
# 有用信息都只保存在'h4'标签中,直接提取'h4'中的元素,保存在列表maintags中
maintags = mainsoup.find_all('h4')
# 查看maintags中的是怎样的数据
print(maintags)
从下图可以看到,maintags是一个列表,其中的元素是每一个h4标签的内容。我们需要的是其中的链接地址和链接名称,因此要对读取到的数据进行清洗。
[<h4> <a href="./201901/t20190116_3156774.html" target="_blank">【长沙市政府门户网站】2019年政府工作报告</a> <span class="date">2019-01-16</span></h4>, <h4> <a href="./201801/t20180110_2162039.html" target="_blank">【长沙市政府门户网站】2018年政府工作报告</a> <span class="date">2018-01-10</span></h4>, ··· , ···] # 省略了部分内容 提取h4标签中href子标签的内容以及h4标签中的文本信息:
# 生成两个空列表,备用
list_link = []
list_name = []
# 将h4中的信息解析出来,分别为链接和标签,存放在以上两个空列表中
# 循环,遍历maintags中的对象
for t in maintags:
# 提取标签中的文本信息
name = t.get_text().strip()
word = "政府工作报告"
# 条件判断,文本中出现“政府工作报告”的条目才被保存
if word in name:
name = "长沙" + re.sub(r"D","", name) # 提取数字
name = name[:6] # 字符截取
link = t.find().attrs['href'] # 提取'href'中信息
# 字符处理,形成有效的链接
flink = "http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg"
link = flink+link[1:]
# 将提取出来的信息存在两个列表中
list_link.append(link)
list_name.append(name)
dic_linkname = dict(zip(list_link,list_name)) # 将列表合并为字典
print(dic_linkname) # 打印查看
从打印出来的信息可以看到,构建的字典类型的对象dic_linkname已经符合我们进行下一步操作的需要了。其结构为一个个的链接地址—链接名称的键值对:
{'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201901/t20190116_3156774.html': '长沙2019',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201801/t20180110_2162039.html': '长沙2018',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201701/t20170111_1841616.html': '长沙2017',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201601/t20160125_876746.html': '长沙2016',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201503/t20150316_705351.html': '长沙2015',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201402/t20140219_536941.html': '长沙2014',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201301/t20130108_420325.html': '长沙2013',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201201/t20120113_301779.html': '长沙2012',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201101/t20110114_118855.html': '长沙2011',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/201002/t20100221_118854.html': '长沙2010',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/200902/t20090210_118853.html': '长沙2009',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/200801/t20080110_118852.html': '长沙2008',
'http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/200710/t20071019_118850.html': '长沙2007'}
Step3: 分别读取各链接中的数据,处理后保存
for l, n in dic_linkname.items(): # 遍历dic_linkname中的对象
link = l
name = n
# 提取网页信息
file = urllib.request.urlopen(link)
pagedata = file.read().decode("utf-8", "ignore")
# 利用BeautifulSoup解析网页信息
soup = BeautifulSoup(pagedata, "html.parser")
# 提取所有标签p中的内容,并将其保存并在content中
tags = soup.find_all('p')
content = []
for t in tags:
text = t.get_text().strip()
content.append(text)
content = "".join(content)
# 指定保存路径,将content中的内容写入到路径下的文档中,并链接对应的链接名称命名
path = 'C:Users木子三工Desktop长沙市政府工作报告'
storePath = path + name +".txt"
fhandle = open(storePath, "w", encoding='utf-8')
fhandle.write(content)
fhandle.close()
运行以上代码后,打开文件夹 C:Users木子三工Desktop长沙市政府工作报告后,我们就能看到程序提取的各年度长沙政府工作报告已经保存在了相应的文本文件里。
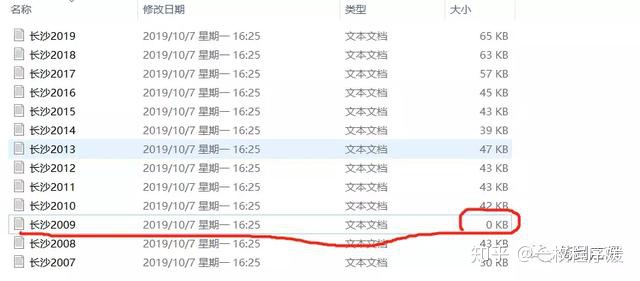
这里有一个小问题,长沙2009文档的大小为0,表示这一对应页面的信息没有被提取到。通过检查网页发现,2009年的链接中,正文内容不是写在“p”标签中的。对于这一问题,如果数量较少,如本文的情况,可以手工补齐;如果很多的话,可以写一个判断语句:当tags为空的时候,采用另外的策略进行抓取。在这里就不过多展开讨论了。
至此,我们通过分析和读取索引页中的信息,逐一抓取了各年度长沙政府工作报告的正文内容,可进行下一步分析。以上展示的代码是为了解决特定问题写的,组织上比较松散。在解决了所有技术性问题后,需要对零散的代码进行组织、测试和封装,增强代码的可读性。本文文末将给出完整版的代码。
二、文本分析
1 前言
随着计算机技术的普及,基于机器语言的文本处理方法开始应用到各个领域。从大量的文本中提取出有用的信息,并结合统计学、计量经济学等学科知识,将这些有用的信息进行进一步组织并挖掘其中的价值,逐渐成为各领域展开研究的一门利器。
文本大数据分析在工业界的应用和价值已经无需赘述,我们使用的搜索引擎、输入法、机器翻译等等都是基于文本大数据分析建立的。而近年来,文本分析在经济学研究中也得到了越来越多的应用[2]。在经济学研究领域,文本分析技术被用于描述经济政策不确定性(Baker et al., 2016)、度量地方政府环境规制力度(Chen et al., 2016;陈诗一和陈登科,2018)、度量和预测经济周期(Thorsrud, 2018)、度量城市居民幸福度(Zheng et al., 2019)等。文本分析为传统的经济学研究提供了新的视角,同时也有助于研究者发掘新的研究问题。
因此,对文本分析技术的了解和掌握是有必要的。本文以一个在学术研究中遇到的问题为操作实例,介绍如何使用python来做词频统计类的文本分析。
2 分析策略
当前拥有的语料资料为2007-2019年长沙市政府工作报告的全文内容(2009年已经手动补齐),我需要分别统计各年度政府工作报告中与环境规制相关的词汇的频数及其在全文中所占的比重,将分析结果保存在一个列表中,导出为excel格式的文件,方便在主力计量分析软件stata中进行读取和分析。
需要注意的问题:
- 原始语料读取后为一个字符串对象,需要对其按照一定的规则分词
- 分词列表中,剔除掉无具体意义词语,如连词“而且”、“但是”,序数词“第一”、“首先”等
因此操作步骤为:
- 读取原始语料
- 将原始语料进行分词
- 按照一定规则筛选分词
- 统计关键词词频及其比重
3 代码实现
以其中一个文件:长沙2019.txt 为例:
Step1: 读取原始语料
file=open(r'C:Users木子三工Desktop长沙市政府工作报告长沙2019.txt','r', encoding='UTF-8').read()
# 参数'r'表示只读,encoding='UTF-8'表示编码为UTF-8
print(type(file))
print(file)
执行print命令后,看到控制台显示出了file对象中的内容,同时显示其类型为字符串(str),表示读取成功了。
Step2: 进行分词
使用结巴中文分词程序包jieba对上文中的字符串file进行分词。
import jieba # 载入结巴中文分词程序包 # 读取之前搜集的中文停用词文档 stopfile=open(r'C:Users木子三工Desktop长沙市政府工作报告stop.txt', 'r', encoding='UTF-8').read() # 将中文停用词文档读取为python列表 stopfile = stopfile.replace(" ","") stoplist = stopfile.split('n') # 分词,并按照 if 后的条件对分词进行筛选 words = [x for x in jieba.cut(file) if len(x) >= 2 and x not in stoplist] # 统计出现频次最高的十个词 top10=Counter(words).most_common(10) print(json.dumps(top10, ensure_ascii=False)) # 画出柱状图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定字体 plt.rcParams['font.family']='sans-serif' name_list=[x[0] for x in c] #X轴的值 num_list=[x[1] for x in c] #Y轴的值 b=plt.bar(range(len(num_list)), num_list,tick_label=name_list)#画图 输出结果如下图所示:
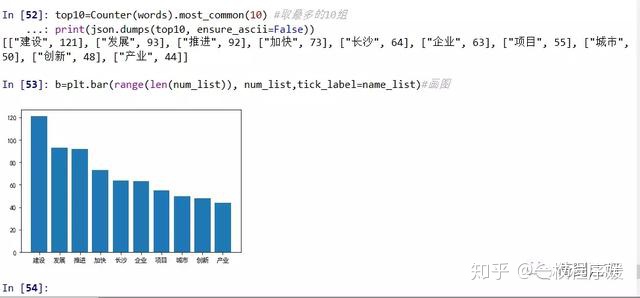
还有比较常用的词云:

Step3: 统计重点词汇的频次和在全文的比重
通过以上步骤,我得到了一个经过筛选后的分词列表words,列表中的元素为词语及其出现的频次。
接下来,在words中统计我关注的重点词汇的出现频次和比重。
首先,定义由重点词汇构成的词语列表,然后分别统计这些词语在words中的频次,结果保存在一个例表中:
# 以以下8个词为例 keywords = ['环境保护', '环保', '污染', '能耗', '绿色', '污水', '废气', 'pm2.5'] # 将列表words转为特定的计数格式 b = Counter(words) # 提取重点词汇的频次 wordsfreq = [b[x] for x in keywords] totalfreq = sum(wordsfreq) # 所有词语的总数 s = sum(b.values()) # 计算比重 weight = totalfreq/s # 打印结果 print(wordsfreq) print(totalfreq) print(weight) 执行以上命令,得到如下结果:

第一个方括号内为重点词汇
第二个方括号内为响应重点词汇出现的频次
数字24表示出现频次的综合
最后一个数字表示重点词汇占全文词汇量的比重
最后这两个指标就是我们所需要的
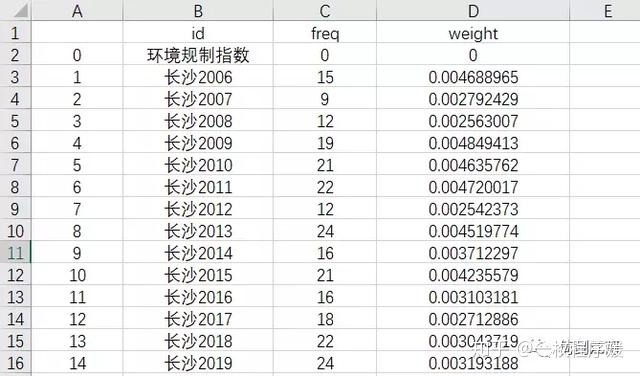
Step4: 将频数和比重指标写入csv文件并保存
本节只用了一个文本文件作为示例,保存为csv文件的代码和结果在此省略。完整的代码请参考附录部分。
最后得到的数据如下所示:
后记
在大数据时代,虽然身为与数据科学联系紧密的一名经济学研究生,我的统计基础和编程能力却是十分薄弱的。因此,本文仅仅上手了一个简单的网络爬虫和文本分析项目,目标是清晰、简洁地解决问题,而对涉及到的其他的技术问题以及其他的可能情况不作过多讨论。这篇文章一方面是为了加深自己对知识的理解,作为复习回顾的资料;另一方面,则是希望能促进感兴趣的朋友对相关知识的理解和实践,更多的细节问题,将在以后的文章中进一步讨论。当前能力有限,写得不清楚或者存在错误的地方,还请批评指正。谢谢!
附录
完整版代码:
- 爬取数据
- # -*- coding: utf-8 -*- """ Created on Sun Oct 6 15:23:49 2019 @author: 木子三工 """ import urllib import urllib.request from bs4 import BeautifulSoup import re def read_mainpage(mainsite): ''' 从mainsite中提取信息 参数 --- mainsite: str,网站地址 ''' # 读取网站内容并保存 file = urllib.request.urlopen(mainsite) mainpagedata = file.read().decode("utf-8", "ignore") # 用beautifulsoup包对网站数据进行解析 mainsoup = BeautifulSoup(mainpagedata, "html.parser") # 有用信息都只保存在'h4'标签中,直接提取'h4'中的元素,保存在列表maintags中 maintags = mainsoup.find_all('h4') # 生成两个空列表,备用 list_link = [] list_name = [] # 将h4中的信息解析出来,分别为链接和标签,存放在以上两个空列表中 for t in maintags: # 提取'href'中信息 link = t.find().attrs['href'] # 字符处理,形成有效的链接 link = "http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg"+link[1:] # 提取标签,处理,用作命名 name = t.get_text().strip() name = "长沙" + re.sub(r"D","", name) name = name[:6] # 将提取出来的信息存在两个列表中,并将两个列表合并为字典 list_link.append(link) list_name.append(name) dic_linkname = dict(zip(list_link,list_name)) # 函数的返回值为一个链接-名字组合的字典 return dic_linkname # 定义方法,抓取网页数据,并保存有用信息 def read_page(link): ''' 从link中提取信息 参数 --- link: str,网站地址 ''' file = urllib.request.urlopen(link) pagedata = file.read().decode("utf-8", "ignore") soup = BeautifulSoup(pagedata, "html.parser") # 提取网页中所有标签为'p'的内容,保存在列表tags中 tags = soup.find_all('p') content = [] for t in tags: text = t.get_text().strip() content.append(text) # 将列表content转为str content = "".join(content) return content # 定义方法,将content中信息写入txt文件 def store_page(storePath, content): ''' 将content中的内容写入到storePath中 参数 --- storePath: str, 保存路径 content: str, 写入的内容 ''' fhandle = open(storePath, "w", encoding='utf-8') fhandle.write(content) fhandle.close() def spider(mainsite): read_mainpage(mainsite) dic_linkname = read_mainpage(mainsite) # 遍历dic_linkname中的项目,分别读取和保存 for l, n in dic_linkname.items(): link = l name = n storePath = path + name +".txt" read_page(link) content = read_page(link) store_page(storePath, content) if __name__ == '__main__': mainsite = "http://video.changsha.gov.cn/xxgk/szfxxgkml/gzbg/index.html" path = 'C:Users木子三工Desktop长沙市政府工作报告' spider(mainsite) 文本分析
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 7 22:12:03 2019
@author: 木子三工
"""
# 载入程序包
import pandas as pd
import jieba
from collections import Counter
import os
# 指定工作路径
mainpath = 'C:Users木子三工Desktop长沙市政府工作报告'
os.chdir(mainpath)
# 定义方法,获取文件名列表
def getFileList(path):
'''
从path中读取文件列表
参数
---
path: str,文件夹路径
'''
path = str(path)
a = os.listdir(path)
filelist = [ x for x in a if os.path.isfile( path + x ) ]
return filelist
# 定义方法,批量处理文件,计算指标
def get_data(path):
filelist = getFileList(path)
# 获取停用词列表
stopfile=open(r'C:Users木子三工Desktop长沙市政府工作报告停用词stop.txt', 'r',
encoding='UTF-8').read()
stopfile = stopfile.replace(" ","")
stoplist = stopfile.split('n')
datalist = []
for file in filelist:
filename, extension = os.path.splitext(file)
file=open(file,'r', encoding='UTF-8').read()
words = [x for x in jieba.cut(file) if len(x) >= 2 and x not in stoplist]
keywords = ['环境保护', '环保', '污染', '能耗', '绿色', '污水', '废气', 'pm2.5']
# 将列表words转为特定的计数格式
b = Counter(words)
# 提取重点词汇的频次
wordsfreq = [b[x] for x in keywords]
totalfreq = sum(wordsfreq)
# 所有词语的总数
s = sum(b.values())
# 计算比重
weight = totalfreq/s
data = [filename] + [totalfreq] + [weight]
datalist.append(data)
return datalist
# 定义方法,将列表数据写入csv文件
def write_csv(path):
datalist = get_data(path)
# 指定列名
colname = ['id', 'freq', 'weight']
# 生成DataFrame格式数据
csvfile = pd.DataFrame(columns = colname, data = datalist)
# 写入csv文件,注意对中文乱码的处理
csvfile.to_csv('环境规制指数.csv', encoding="utf_8_sig")
if __name__ == '__main__':
path = 'C:Users木子三工Desktop长沙市政府工作报告'
write_csv(path)














 2768
2768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









