







当作是这三周实习学到的一点小成果吧。还有很多不会的,要继续加油!
写了一个初级爬虫,简单了解了一下,结合一下学到的整理数据的方法。任务就是爬取国务院的最新政策:
代码:
import requests
import re
from bs4 import BeautifulSoup
from pandas import DataFrame
url = 'http://www.gov.cn/zhengce/zuixin.htm'
UA = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
headers = {'User_Agent': UA}
r = requests.get(url, headers = headers)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
attrs = {'class': 'date'}
links = soup.find_all(href = re.compile('content'))
dates = soup.find_all(name = 'span', attrs = attrs)
# Get titles and links
titles = []
urls = []
for link in links:
titles.append(str(link.string))
url = link.get('href')
urls.append(str(url))
#Get days
days = []
pattern = re.compile('(\d+)\-(\d+)\-(\d+)')
for date in dates:
s = date.string
day = re.search(pattern, s)
days.append(str(day.group()))
data = {'date': days,
'title': titles,
'url': urls}
frame = DataFrame(data)
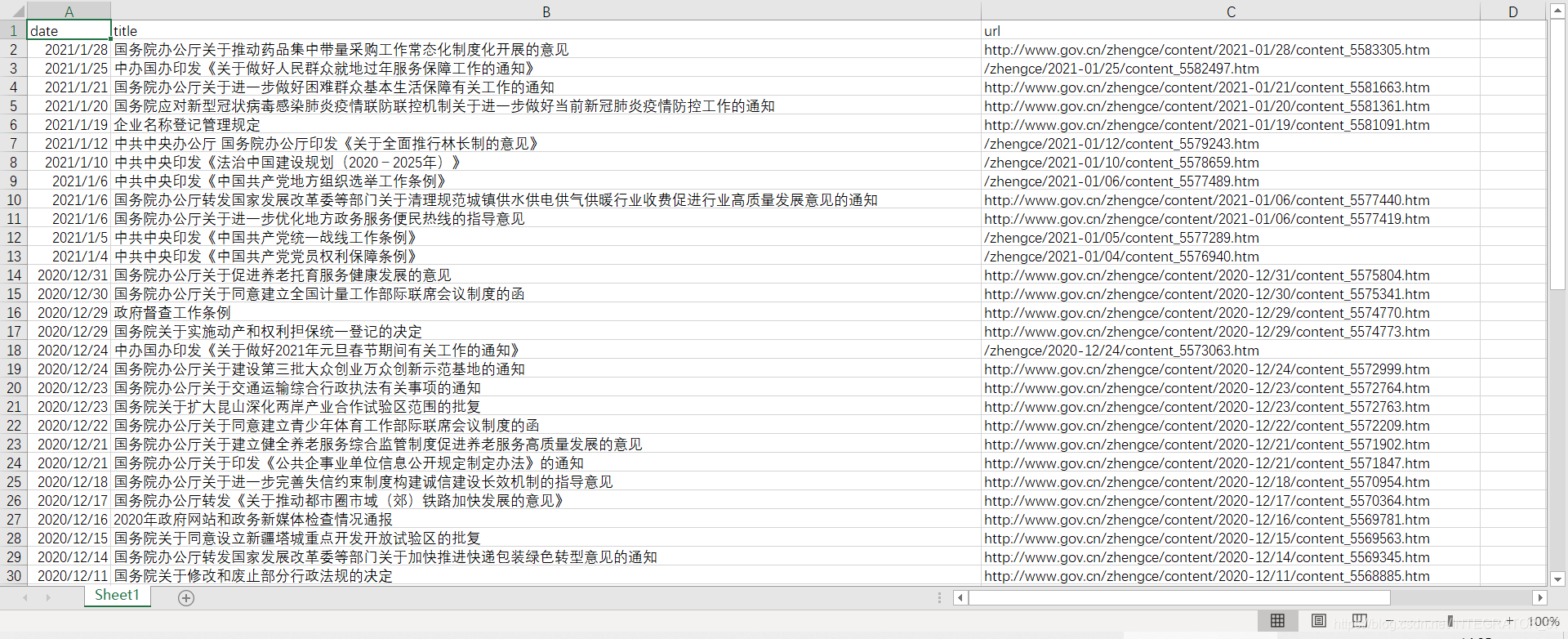
frame.to_csv('test.csv', index = False)成果:

















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









