





 点击图片上方蓝色字体“慧天地”即可订阅
点击图片上方蓝色字体“慧天地”即可订阅

本文转载自微信公众号地理信息世界GeomaticsWorld,版权归原作者及刊载媒体所有。

作者信息:
陈凯:西南交通大学 地球科学与环境工程学院,四川 成都 611756;
曹云刚:西南交通大学 地球科学与环境工程学院,四川 成都 611756; 西南交通大学 高速铁路运营安全空间信息技术国家地方联合工程实验室,四川 成都 611756
杨秀春:中国农业科学院 农业资源与农业区划研究所,北京 100081
潘梦:西南交通大学 地球科学与环境工程学院,四川 成都 611756
张敏:西南交通大学 地球科学与环境工程学院,四川 成都 611756
【摘要】现有的遥感数据时空融合算法复杂,计算时间长,获取海量时序的高时空分辨率遥感影像非常困难。因此,通过分析GPU并行运算模式与遥感数据时空融合算法的实现步骤,合理地设计了一种基于CPUGPU异构混合编程的遥感数据时空融合并行处理算法流程,将融合算法中的数据密集型计算部分由CPU移植到GPU中执行。遥感数据时空融合算法种类繁多,不同算法的可并行程度与算法复杂度有着很大的差异,选取3种不同类型的遥感数据时空融合算法STDFA、STARFM、CDSTARFM进行GPU并行设计,并使用CUDA架构实现。实验结果表明,基于CPU-GPU异构混合编程技术可大幅度缩减遥感数据时空融合时间,提升计算效率,最高加速比可达到195.6,从而可为海量时空遥感数据的深度应用提供技术支撑。
【关键词】遥感数据时空融合;GPU;CUDA;混合编程;并行计算
【中图分类号】TP302
【文献标识码】A
【文章编号】1672-1586(2019)06-0006-08
引文格式:陈凯,曹云刚,杨秀春等. 基于CPU-GPU异构混合编程的遥感数据时空融合[J].地理信息世界,2019,26(6):6-13.
正文
0 引 言
高时间、高空间分辨率遥感影像在地球系统科学研究中有着非常重要的作用。但是由于技术与资金的限制,在轨同一传感器很难同时获取既具有高空间分辨率,又具有高时间分辨率的影像。因此,研究人员提出了遥感数据时空融合算法来获取高时空分辨率的遥感影像,从而为深入认知地球表层变化提供有效的数据源。遥感影像数据量大,遥感数据时空融合算法复杂度高,使用CPU串行计算效率低、耗时长。因此,通过遥感数据时空融合算法获取海量时序的高时空分辨率遥感影像非常困难。
为解决上述问题,本文设计了一种基于CPU-GPU异构混合编程的遥感数据时空融合并行处理算法流程来大幅度地提高其计算效率。GPU(Graphics Process Unit)有着高质量、高性能的图形处理与图形计算能力,非常适用于数据密集型计算。随着近几年来GPU的快速发展,GPU的计算能力有着巨大的提升,特别是2006年NVIDIA推出CUDA(Compute Unified Device Architecture)架构后,大幅度降低了GPU编程的难度,使得普通用户也能使用GPU处理复杂的计算问题,充分发挥出GPU的高并行计算能力。从而,GPU在高性能计算领域得到了广泛的使用。GPU有着远高于CPU的数值运算能力,现有研究证明在浮点运算、并行计算等方面,GPU相比CPU来说可以提高几十倍乃至于上百倍的性能。使用GPU处理海量遥感数据能够充分发挥CUDA大量处理器核心的高并行计算能力,是一种非常有效的处理方法。
遥感数据时空融合算法中存在大量的数据密集型计算和易于并行计算的步骤。关庆锋团队利用了GPU的高并行计算能力开发了STARFM、ESTARFM和STNLFFM3个遥感数据时空融合模型的并行算法,并使用了自适应数据分解、自适应线程设置、自适应寄存器优化和循环任务分配等策略减少了冗余计算和内存消耗,提高了灵活性和可移植性。但需要对输入的Landsat和MODIS影像进行预处理,限制了模型在实际应用中流程化处理的可行性。
因此,本文结合遥感数据时空融合算法和CUDA架构,基于CPU-GPU异构混合编程设计了一种合理的遥感数据时空融合并行处理算法流程,验证了STDFA、STARFM、CDSTARFM3种模型并行化的可行性,并详细论述了每一个时空融合模型中各个不同组件的并行处理算法与加速效果。本文程序要求输入MODGQ09标准数据集和解压缩后Landsat原始数据集,不需要额外的预处理操作,支持流程化处理(源代码参考网址:https://github.com/bcrx/chenkai)。其中,CPU负责执行复杂的逻辑处理、事务处理与数据读写,GPU负责遥感数据时空融合算法中的数据密集型计算和易于并行部分的计算。充分发挥CPU和GPU各自的优势,大幅度地降低高时空分辨率影像的融合时间。
1 实验数据与方法
1.1 实验数据
本文选取两幅L a n d s a t 8 O L I影像(影像尺寸为7 864×7 767,空间分辨率为30 m),4幅MODGQ09影像作为实验数据,各数据的获取时间和用途等信息见表1。该地区大部分为植被覆盖,有少部分居民区等其他地物,满足遥感数据时空融合算法的要求。其中,Landsat8 OLI数据来源于地理空间数据云,MODIS反射率产品来源于NASA土地数据中心。

表1 Landsat8 OLI数据与MODIS数据
Tab.1 Landsat8 OLI and MODIS dataset
本文实验计算机配置如下:CPU型号i7-6700,内存8 G,基准速度2.60 GHz;显卡型号NVIDIA GTX960M,显卡内存2 G,CUDA处理器核心数量640,核心频率1 096 MHz。
1.2 实验方法
1.2.1 CPU-GPU异构混合编程
现有主要的CPU-GPU异构混合编程架构有两个,分别是CUDA和OpenCL。CUDA为NVIDIA推出的一个异构并行编程架构,相比OpenCL、CUDA拥有良好的开发环境、丰富的函数库和更加优秀的性能。本文采用CUDA架构,其中CPU作为主机负责执行复杂的逻辑与事件处理,加载GPU所需要的数据。GPU作为设备,负责大规模密集型数据的并行计算。
1.2.2 遥感数据时空融合算法
本文选取了3种具有代表性的遥感数据时空融合算法:
1)像元分解降尺度算法(the Spatial Temporal Data Fusion Approach,STDFA)。
2)自适应遥感影像时空融合方法(the Spatial and Temporal Adaptive Reflectance Fusion Model,STRAFM)。
3)混合模型融合方法(Combining STARFM and Downscaling Mixed Pixel Algorithm,CDSTARFM)。
现有的这3种算法适用于CPU串行计算,不能直接移植到GPU中执行。因此,通过分析这3种算法的结构,结合GPU并行运算的模式与特点,将其中可并行计算部分分为多个独立组件,移植到GPU中执行。基于CPU-GPU异构混合编程的时空数据融合算法流程如图1所示,粗斜体部分使用GPU并行处理,其他步骤使用CPU处理。
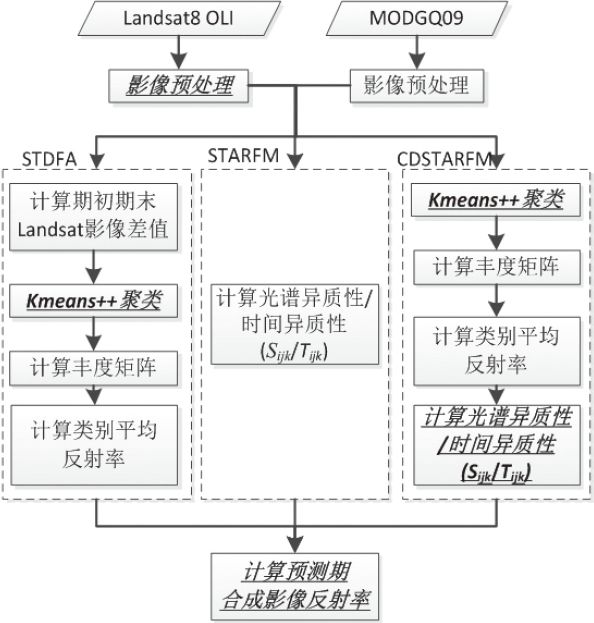
图1 基于CPU-GPU异构混合编程的时空数据融合算法流程(粗斜体部分为GPU运算)
Fig.1 Temporal and spatial fusion algorithm flow based on CPU-GPU heterogeneous mixed programming (the bold italic part is GPU operation)
每个并行计算的CUDA核函数通用逻辑及其各设备间的数据通信如图2所示,其中每个并行计算组件的计算单元Grid 、Block 、Thread 之间数据通信过程一致,若输入数据大小为M ×N ,每个block 的thread 数量有限,不能设置过大,每个block 分配256个thread ,则总共block数量计算公式为:
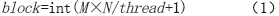
不同的核函数主机内存与显存、显存与计算单元之间的数据通信有细微的差异,同一个核函数这两者之间的数据通信内容一致。下面将对GPU并行设计细节做详细阐述。
1)Landsat影像预处理
Landsat影像预处理分为以下两个步骤:
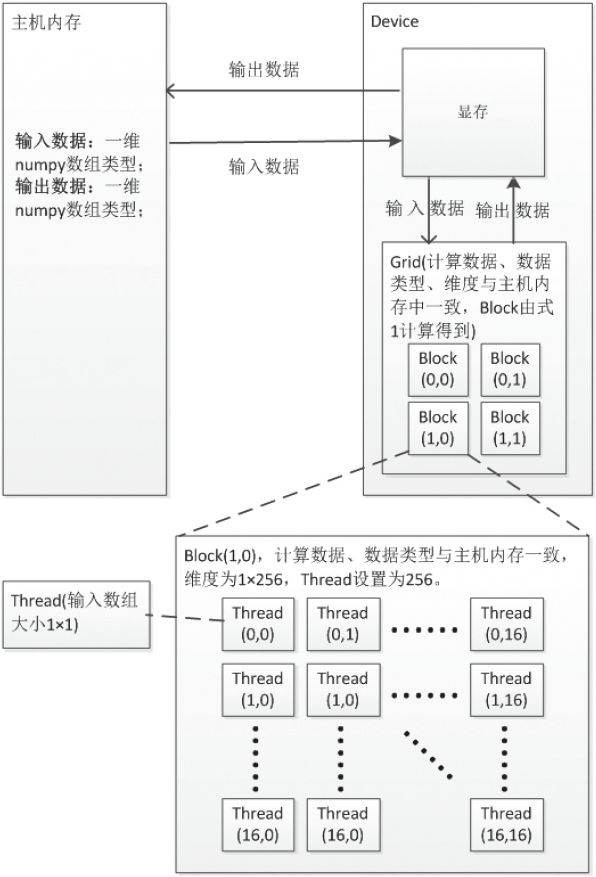
图2 CUDA核函数逻辑图
Fig.2 Logic diagram of CUDA kernel function
①辐射定标。本文使用Landsat8 OLI影像数据计算大气顶部光谱辐射值,计算每一个像素点大气顶部光谱辐射值时均为独立计算,适合使用GPU并行处理;
②大气校正。其中,大气校正可使用6S模型或者FLAASH模型,不做GPU并行处理。辐射定标并行处理流程如下:
① 读取L a n d s a t 影像与元数据得到亮度值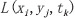 与波段λ的调整因子
与波段λ的调整因子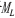 、波段λ的调整参数
、波段λ的调整参数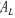 存入到主机内存中。
存入到主机内存中。
②编写CUDA核函数。计算得到大气顶部光谱辐射值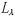 。
。
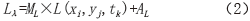
③核函数调用。数据通信过程如图2所示,详细内容见表2,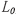 为初始化空数组用于保存辐射定标后结果并假设原始Landsat影像维度为m×n。
为初始化空数组用于保存辐射定标后结果并假设原始Landsat影像维度为m×n。

表2 辐射定标主机内存与显存、显存与计算单元之间的数据通信
Tab.2 Data communication between host memory and graphics memory, graphics memory and computing unit in radiation calibration
2)Kmeans++聚类
本文结合CPU与GPU,实现了基于三角不等式原理的Kmeans++算法的并行处理。其中,最耗时的距离计算移植到GPU中执行,其他部分在CPU端执行。
Kmeans++算法并行处理流程如下:
①读取Landsat红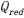 与近红外
与近红外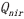 波段或者差值影像
波段或者差值影像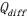 。
。
②从输入影像中随机选择一个点作为第一个聚类中心。
③编写CUDA核函数并调用。计算每个像素与已有聚类中心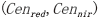 的距离,并得到其中最近聚类中心的距离Dis 。数据通信过程如图2所示,详细内容见表3,
的距离,并得到其中最近聚类中心的距离Dis 。数据通信过程如图2所示,详细内容见表3,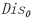 为初始化空数组用于保存Dis。
为初始化空数组用于保存Dis。

表3 初始化聚类中心主机内存与显存、显存与计算单元之间的数据通信
Tab.3 Data communication between host memory and graphics memory, graphics memory and computing unit in cluster center initialization
④选择一个新的数据点作为新的聚类中心,选择的原则是:D(x )较大的点,被选取作为聚类中心的概率较大。
⑤重复③和④直到K个聚类中心被选出来。
⑥影像分块。由于计算机显存的限制,需要对原始遥感影像进行分块处理,不同的计算机硬件配置适宜的分块大小不一样。分块太多容易导致显存溢出,分块太小会增加CUDA启动次数和显存与内存之间的数据传输次数,降低计算效率。经测试在本计算机硬件配置下,分块大小为512×512比较合适,不重叠。
⑦编写CUDA核函数并调用。计算每个像素点到聚类中心的距离,根据三角不等式原理将每个像素点重新分配到对应的类别Class 。为了提高计算效率,每一个类别对应的像素值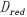 ,
,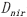 也储存到显存中,用于下一步聚类中心的重新计算。最后将聚类结果,每一个类别对应的像素值传入到内存中。数据通信过程如图2所示,详细内容见表4,
也储存到显存中,用于下一步聚类中心的重新计算。最后将聚类结果,每一个类别对应的像素值传入到内存中。数据通信过程如图2所示,详细内容见表4,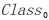 、
、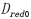 、
、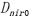 为初始化空数组。
为初始化空数组。
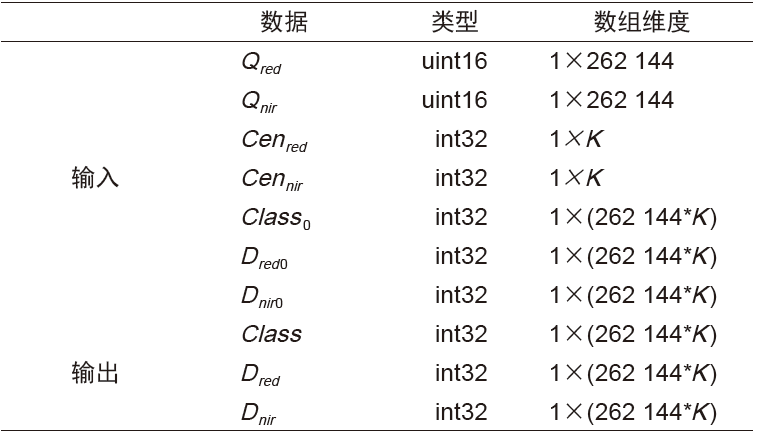
表4 距离计算主机内存与显存、显存与计算单元之间的数据通信
Tab.4 Data communication between host memory and graphics memory, graphics memory and computing unit in distance calculation
⑧所有分块后影像计算完成后重新计算新的聚类中心,如果所有的聚类中心未发生变化或达到最大迭代次数,拼接分块后聚类影像并保存,否则转到⑦。
其中,STDFA使用期初与期末Landsat的差值影像进行聚类,CDSTARFM使用期初Landsat影像红与近红外波段进行聚类,两者数据通信过程一致。
3)光谱/时间异质性权重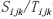 计算
计算
总权重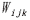 由以下3个部分组成,MODIS影像和Landsat影像的光谱异质性
由以下3个部分组成,MODIS影像和Landsat影像的光谱异质性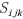 ,初期
,初期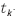 与预测
与预测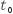 时期MODIS影像的时间异质性
时期MODIS影像的时间异质性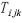 以及中心像元与相似像元的相对距离
以及中心像元与相似像元的相对距离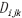 。
。
为避免权重的冗余运算,先对与进行计算。其中,STARFM使用CPU端计算与,其与计算简单,使用CPU端计算效率高于GPU。CDSTARFM中与计算较为复杂,耗时较多,因此使用GPU并行处理,处理流程如下:
①编写CUDA核函数,计算每一个像素点的,计算公式如式(3)、式(4)所示。数据通信过程如图2所示,详细内容见表5,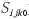 为初始化空数组。
为初始化空数组。
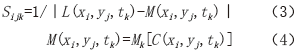

表5 Sijk计算主机内存与显存、显存与计算单元之间的数据通信
Tab.5 Data communication between host memory and graphics memory, graphics memory and computing unit in Sijk calculation
②编写CUDA核函数,计算每个像素点的类别平均反射率之差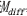 ,计算公式如式(5),用于下一步计算和后续预测期合成影像反射率计算,减少冗余计算。数据通信过程如图2所示,详细内容见表6,
,计算公式如式(5),用于下一步计算和后续预测期合成影像反射率计算,减少冗余计算。数据通信过程如图2所示,详细内容见表6,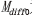 为初始化空数组。
为初始化空数组。
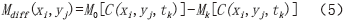

表6 计算主机内存与显存、显存与计算单元之间的数据通信
Tab.6 Data communication between host memory and graphics memory, graphics memory and computing unit in calculation
③编写CUDA核函数,计算每个像素点的,计算公式如式(6)。数据通信过程如图2所示,详细内容见表7,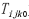 为初始化空数组。
为初始化空数组。
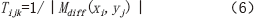

表7 计算主机内存与显存、显存与计算单元之间的数据通信
Tab.7 Data communication between host memory and graphics memory, graphics memory and computing unit in calculation
计算公式中,L 为Landsat反射率影像,M 为降尺度影像,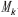 与
与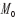 为预测期和初期的类别平均反射率数组(1组类别数K ), C 为分类影像。
为预测期和初期的类别平均反射率数组(1组类别数K ), C 为分类影像。
4)预测期合成影像反射率计算
STDFA不需要计算权重,算法复杂度较低,可直接使用GPU计算预测期合成影像反射率。STARFM与CDSTARFM计算预测期合成影像反射率需要权重参与,上一步已经单独计算了光谱异质性与时间异质性,因此,本部分还需要筛选相似像元、计算中心像元与相似像元的相对距离权重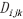 以及相似像元的总权重
以及相似像元的总权重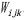 。
。
STARFM与CDSTARFM计算预测期合成影像反射率分为了以下几个步骤,其中,②~⑤在CUDA核函数中执行,每个block分配256个thread,每个thread对应一个窗口进行计算,窗口大小为w×w。
①在CPU端对初期Landsat影像分块,经测试分块大小设置为512×512比较合适,重叠w -1个像元。
②选取窗口内的相似像元。
③计算相似像元的相对距离
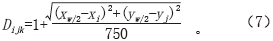
④计算相似像元权重
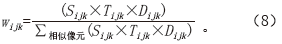
⑤计算中心像元反射率
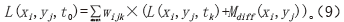
⑥计算每一块预测期合成影像反射率,每一块计算完成后将显存中所有窗口的中心像元反射率传回主机内存,在CPU端进行拼接与保存。数据通信过程如图2所示,详细内容见表8, 为初始化空数组。
为初始化空数组。

表8 预测期合成影像反射率计算主机内存与显存、显存与计算单元之间的数据通信
Tab.8 Data communication between host memory and graphics memory, graphics memory and computing unit in predictive synthetic image reflectance
2 实验结果与分析
本文选取了3种遥感数据时空融合算法STDFA、STARFM与CDSTARFM,实验结果见表9与图3所示。实验结果表明不同的遥感数据时空融合算法加速比不同,表9中STARFM与CDSTARFM总加速比相差很小,总体加速效果一致。STDFA总加速比远小于STARFM与CDSTARFM,总加速效果相对较差。
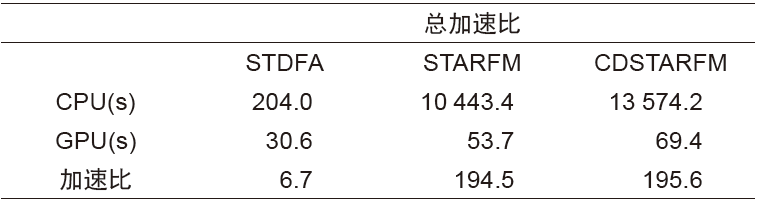
表9 3种遥感数据时空融合算法加速比
Tab.9 Speeded-up ratio of three different temporal and spatial fusion algorithm for remote sensing data
因为聚类算法选择的多样性,本文聚类计算时间没有加入到总的计算时间中,后面单独讨论聚类的加速效果。不同的算法CPU串行部分的计算时间占总的计算时间比重不一致。CPU串行部分的计算时间占总的计算时间比重越小,对总加速比的影响越小。STDFA算法CPU串行运算时间占STDFA算法总计算时间的91.2%,GPU并行处理部分仅占总计算时间的8.8%,导致其总加速比较低。同样,尽管STARFM的算法复杂度要低于CDSTARFM,并且单独的GPU并行处理部分的计算加速比STARFM也要低于CDSTARFM,但两者的总体加速比一致。
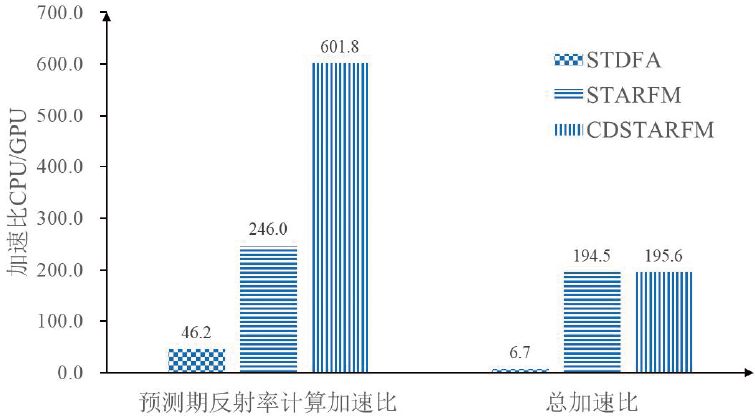
图3 3种遥感数据时空融合算法预测期合成影像反射率计算部分加速比与总加速比
Fig.3 The speeded-up ratio of predictive synthetic image reflectance calculation part and total speeded-up ratio for three different remote sensing data temporal and spatial fusion algorithm
遥感数据时空融合算法总加速比还会受到GPU并行处理部分加速比的影响,本文将遥感数据时空融合算法中适合GPU并行处理的部分拆解为4个部分来做并行处理,每一个部分的具体加速比与加速效果有着非常大的差异。(本文电脑配置下,Python整型四则运算速度比C/C++慢大约30倍,浮点型四则运算速度比C/C++慢大约92倍。本文所有程序由Python编写完成,因此计算时间较长。)
2.1 Landsat影像预处理
表10表明了Landsat影像大气顶部光谱辐射值串并行计算时间开销情况,其平均加速比为114.0。CUDA中仅有简单的几种数值计算函数,在进行复杂的数值计算时,需要导入math库。Python中CUDA核函数导入math库需要花费一定的时间成本,大约5.8 s,而在CUDA核函数中自定义所需的数值计算函数所需时间为秒级以下。因此,使用内置函数或自定义函数可提高计算效率。

表10 Landsat影像大气顶部光谱辐射值串并行计算时间开销对比
Tab.10 The serial and parallel computing time cost comparison for Landsat image atmospheric top spectral radiance
2.2 Kmeans++聚类
本文将Landsat影像分为10类,因此,需要初始化10个种子点,见表11,其加速比为38.1。基于三角不等式原理的Kmeans++算法一次迭代平均加速比为14.0,但随着迭代的进行,加速比会逐渐降低。

表11 Kmeans++算法串并行计算时间开销对比
Tab.11 The time cost comparison of serial and parallel computing for Kmeans++ algorithm
因为Kmeans++算法并行处理中只有距离计算适用于GPU并行计算,其他计算部分适合使用CPU串行计算。除此之外,还需要进行多次的CUDA核函数的启动以及内存与显存频繁的数据交换。因此,本部分的加速比要远低于Landsat影像大气顶部反光谱辐射值计算的加速比。
2.3 光谱/时间异质性权重计算
表12表明了CDSTARFM中与的串并行计算时间开销对比。其中,GPU并行计算显著提高了其计算速度。计算加速比远高于,这是因为主要为四则运算,主要为数组索引取值运算,CPU数组索引取值计算效率要高于四则运算,因此,在两者时间复杂度接近的情况下,CPU计算效率高于,从而的加速比高于的加速比。
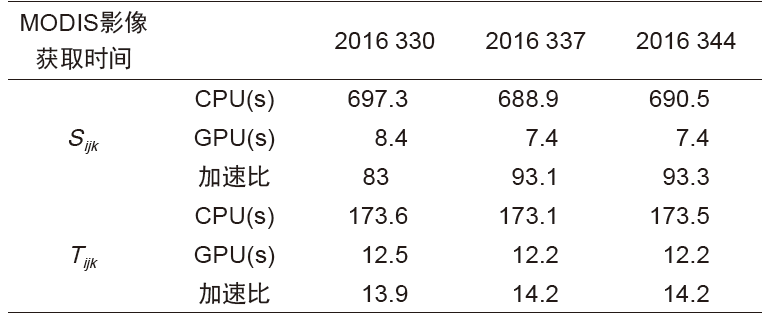
表12 CDSTARFM算法串并行计算时间开销对比
Tab.12 The serial and parallel computing time cost comparison of for CDSTARFM algorithm
2.4 预测期合成影像反射率计算
预测期合成影像反射率计算为遥感数据时空融合算法的核心步骤,图3和表13表明了预测期合成影像反射率计算的GPU并行计算的加速效果,其中,CDSTARFM加速比最高,为601.8,加速效果最为显著;STARFM加速比246.0;STDFA最低,为46.2。STDFA算法复杂度最低,因此,其加速比最小,CDSTARFM与STARFM需要进行窗口内相似像元筛选、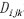 和
和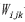 计算。其中,CDSTARFM与STARFM获取相似像元方法不一样,在同样的窗口大小下,CDSTARFM获取的相似像元要比STARFM多,因此CDSTARFM的算法复杂度最高,加速效果最为显著。每种算法计算了3个预测期合成影像,表13表明不同预测期的影像加速效果差异很小,不受预测期影像成像时间的影响。
计算。其中,CDSTARFM与STARFM获取相似像元方法不一样,在同样的窗口大小下,CDSTARFM获取的相似像元要比STARFM多,因此CDSTARFM的算法复杂度最高,加速效果最为显著。每种算法计算了3个预测期合成影像,表13表明不同预测期的影像加速效果差异很小,不受预测期影像成像时间的影响。
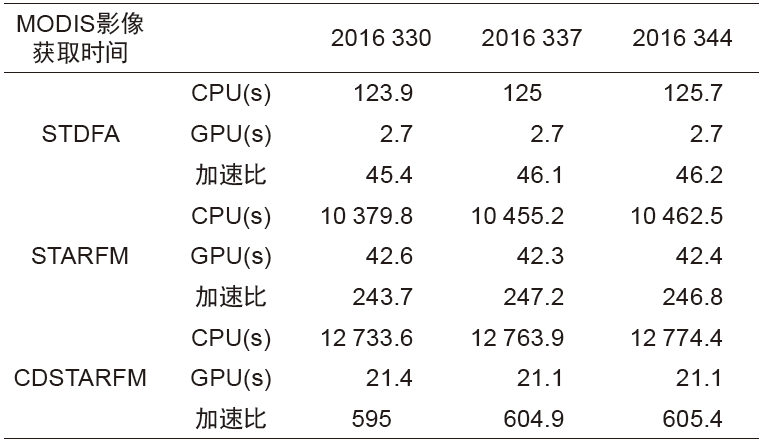
表13 预测期合成影像反射率串并行计算时间开销对比
Tab.13 The serial and parallel computing time cost comparison for predictive synthetic image reflectance
3 结束语
本文基于CPU-GPU异构混合编程设计了一种合理遥感数据时空融合的并行处理算法流程,消除了大部分的冗余计算,优化了算法流程,显著提高了遥感数据时空融合算法的计算速度,加速效果非常显著。不同的遥感数据时空融合算法加速效果不同,CDSTARFM与STARFM加速效果最好,加速比分别约为195.6和194.5,STDFA加速比相对较低,为6.7。时空融合模型中的不同的组件加速比也有显著的差异,辐射定标加速比约为114.0、生成聚类图加速比约为19.2、光谱异质性权重计算加速比约为89.7,时间异质性权重计算加速比约为14.1,STDFA合成影像反射率计算加速比约为45.9,STARFM约为245.9,CDSTARFM约为601.8。与CPU串行计算相比,本文的并行设计获得了显著的加速效果,可节省大量的计算时间,使得时序的高时空间分辨率遥感影像的获取变得更加方便快捷。因此GPU并行计算在遥感数据时空融合领域内具有良好的应用前景。
每一种时空融合模型GPU并行处理方式都有差异,但其核心步骤的并行处理方式基本一致,本文验证了其中3种模型的可行性,其他时空融合模型利用GPU做并行处理也是可行的,比如增强时空融合模型(ESTARFM),ESTARFM中输入影像预处理,加权计算等步骤基本与本文一致,均可并行化处理。
本文仍有一些不足,如本文验证了GPU并行计算可以显著提高遥感数据时空融合的计算效率,但没有讨论在时空融合算法并行计算过程中GPU内部硬件单元对其计算效率有何具体影响。首先本文没有为CUDA核函数分配最优的线程数,一些运算单元处于闲置状态,设置合适的线程数可以让显卡的运算单元得到充分的利用,提高CUDA程序计算效率。理论上核函数最优的线程数量与CUDA处理器核心数量一致,但实际性能会受到其他因素的影响,如访存带宽,线程调度,核心频率等。其次因为显存与主机内存的限制,本文对遥感影像进行了分块处理,分块影像大小为512×512。而CUDA程序在分配显存,启动内核,数据传输都有着一定的延迟,因此根据显存和内存计算最优的分块数,尽量减少CUDA程序的运行次数。
(点击图片即可查看详细信息)



内容转载、商务活动、投稿等合作请联系
微信号:huitiandi321
邮箱:geomaticshtd@163.com
欢迎关注慧天地同名新浪微博:
ID:慧天地_geomaticser
往期精彩推荐 卫星遥感技术助力自然资源督察 高分卫星如何真正用于高分定量遥感 快速精确的多模态遥感影像自动配准 使用PIE遥感软件发表论文的奖励办法
《慧天地》敬告
《慧天地》公众号聚焦国内外时空信息科技前沿、行业发展动态、跨界融合趋势,探索企业核心竞争力,传播测绘地理信息文化,为测绘、地信、遥感等相关专业的同学提供日常学习、考研就业一站式服务,旨在打造政产学研用精准对接的平台。《慧天地》高度重视版权,对于原创、委托发布的稿件,会烦请作者、委托方亲自审核通过后才正式推发;对于来自网站、期刊、书籍、微博、微信公众号等媒介的稿件,会在作者栏或者文章开头显著标明出处,以表达对作者和推文引用平台版权的充分尊重和感谢;对于来源于网络作者不明的优质作品,转载时如出现侵权,请后台留言,我们会及时删除。感谢大家一直以来对《慧天地》的关注和支持!——《慧天地》运营团队

















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









