







在大数据技术世界中迷路是非常容易的。他们太多了,似乎没有新的一天的到来,一天就过去了。尽管如此,如此快速的发展仅是麻烦的一半。真正的问题在于,很难理解现有技术的功能和预期用途。
为了找出适合他们需求的技术,IT经理经常对它们进行对比。我们还进行了一项学术研究,以明确区分Apache Hive和Apache HBase(这是hadoop项目中经常使用的两项重要技术)。
数据模型比较
Apache Hive的数据模型
要了解Apache Hive的数据模型,您应该熟悉其三个主要组件:表,分区和存储桶。
Hive的表与关系数据库表没有太大区别(主要区别是表之间没有关系)。Hive的表可以是托管表,也可以是外部表。为了了解这两种类型之间的区别,让我们看一下加载数据并删除表操作。当您将数据加载到 托管表中时,实际上是将数据从Hadoop分布式文件系统(HDFS)的内部数据结构移动到Hive目录(也位于HDFS中)。并且,当您删除此类表时,将从目录中删除其中包含的数据。在外部表的情况下,Hive不会将数据加载到Hive目录中,而是会创建一个“ ghost-table”,以指示实际数据在HDFS中的物理存储位置。因此,当您删除外部表时,数据不会受到影响。
托管表和外部表都可以进一步细分为分区。分区表示基于分区键将表的行分组在一起。每个分区都作为单独的文件夹存储在Hive目录中。例如,下表可以根据国家/地区进行分区,每个国家/地区的行将存储在一起。当然,此示例已简化。在现实生活中,您将处理三个以上的分区,每个分区中要处理的行数要多于四行,分区将帮助您显着减少分区键查询的执行时间。

您可以将数据进一步细分为存储桶,这些存储桶甚至更易于管理并可以更快地执行查询。让我们使用上一个示例中的美国数据进行分区,然后根据“客户ID”列将其群集到存储桶中。当您指定存储桶的数量时,Hive将哈希函数应用于所选的列,该函数将哈希值分配给分区中的每一行,然后将行“打包”到一定数量的存储桶中。因此,如果分区中有1000万个客户ID,并将存储桶数指定为50,则每个存储桶将包含约200,000行。因此,如果您需要查找有关特定客户的数据,Hive将直接转到相关存储段以查找信息。
Apache HBase的数据模型
HBase还将数据存储在表中。HBase表中的单元格由行键和列族组成。每个列族都有一组存储属性(例如,行键加密和数据压缩规则)。此外,还有 列限定符可以简化数据管理。行键和列限定符均未分配数据类型(它们始终被视为字节)。
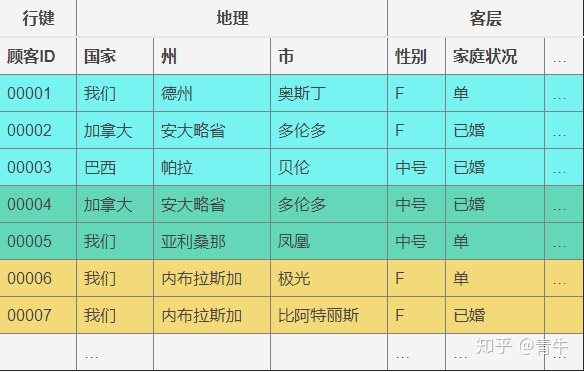
每个单元都有一个时间戳,或者换句话说,带有创建时间的标记。该信息在读取操作期间至关重要,因为它可以标识最新(因此更新)的数据版本。您可以在写操作期间指定时间戳,否则,HBase会自动为单元提供当前时间戳。
表中的数据是根据行键按字典顺序排序的,并且要将紧密相关的数据存储在一起,开发人员需要设计一种好的行键组合算法。
至于分区,HBase会根据行键自动进行分区。不过,您仍然可以通过更改每个分区的开始和结束行键来管理该过程。
数据模型的关键要点
- Hive和HBase都能够以一种能够快速访问所需数据并减少查询执行时间的方式组织数据(尽管它们的分区方法不同)。
- Hive和HBase均充当数据管理代理。当有人说Hive或HBase存储数据时,实际上意味着数据存储在数据存储中(通常在HDFS中)。这意味着您的Hadoo不仅取决于技术选择,而且还取决于其他重要因素,例如正确计算所需的集群大小以及无缝集成所有架构组件。
查询效果
Hive作为分析查询引擎
Hive是专门为启用数据分析而设计的。为了成功执行此任务,它使用了专用的Hive查询语言(HiveQL),该语言与分析优化的SQL非常相似。
最初,Hive将HiveQL查询转换为Hadoop MapReduce作业,从而简化了可以绕开更复杂的MapReduce代码的开发人员的生活。在Hive中运行查询通常要花费一些时间,因为Hive会扫描所有可用数据集(如果没有另外指定的话)。通过指定Hive必须处理的分区和存储桶,可以限制扫描数据的数量。无论如何,那是批处理。如今,Apache Hive还能够将查询转换为Apache Tez或Apache Spark作业。
Hive的最早版本不提供记录级的更新,插入和删除,这是Hive中最严重的限制之一。此功能仅在版本0.14.0中出现(尽管有一些限制:例如,表的文件格式应为ORC)。
HBase作为支持查询的数据管理器
作为数据管理器,仅HBase不能用于分析查询。它没有专用的查询语言。为了运行CRUD(创建,读取,更新和删除)和搜索查询,它具有基于JRuby的shell,该shell提供了简单的数据操作可能性,例如Get,Put和Scan。对于前两个操作,应指定行键,而扫描将遍历整个行范围。
HBase的主要目的是为HDFS提供随机数据输入/输出。同时,可以肯定地说HBase通过启用一致的读取来为快速分析做出了贡献。由于HBase仅将数据写入一台服务器,而无需比较来自不同节点的多个数据版本,因此这是可能的。此外,HBase 处理附加操作非常好。它还启用了更新和删除功能,但是对这两个功能的要求并不理想。
索引编制
在Hive 3.0.0中,删除了索引。在此之前,可以在列上创建索引,尽管应该将更快查询的优点与写操作期间的索引成本以及用于存储索引的额外空间进行权衡。无论如何,Hive的数据模型具有将数据分组到存储桶(可以为任何列创建的功能,不仅可以为键控的创建)的功能,提供了一种类似于索引提供的方法。
HBase支持多层索引。但同样,您必须考虑获得读取查询响应与写入速度较慢之间的权衡,以及与存储索引相关的成本。
有关查询性能的关键要点
- 运行分析查询正是Hive的任务。HBase的最初任务是摄取数据以及运行CRUD和搜索查询。
- 虽然HBase可以很好地处理行级更新,删除和插入,但Hive社区正在努力消除这一绊脚石。
把它们加起来
Hive和HBase之间有许多相似之处。两者都是数据管理代理,并且都与HDFS紧密互连。两者之间的主要区别在于,HBase是为执行CRUD和搜索查询而量身定制的,而Hive是分析性查询。这两种技术相互补充,并且经常在Hadoop咨询项目中一起使用,因此企业可以充分利用这两种应用程序的优势。















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









