



 本文介绍如何在遇到pd.merge操作后产生的重复数据时,利用Excel数组公式计算不重复数据的个数。通过一个需要按CTRL+SHIFT+回车键确认的公式,先计算每个值的出现次数,再取倒数并求和,从而得到不重复数据的数量。此外,还预告了如何在特定条件下计算不重复个数。
本文介绍如何在遇到pd.merge操作后产生的重复数据时,利用Excel数组公式计算不重复数据的个数。通过一个需要按CTRL+SHIFT+回车键确认的公式,先计算每个值的出现次数,再取倒数并求和,从而得到不重复数据的数量。此外,还预告了如何在特定条件下计算不重复个数。
日常工作中,我们常常会遇到一些带有重复值的数据列。
例如下面表格中的姓名列,标红色的是重复数据,那么问题来了——如何统计表格中不重复数据的个数呢?

当然,我们可以用透视表或者用删除重复值的功能,然后再用COUNT函数统。
今天,给大家两个公式,来计算不重复数据的个数以及在指定条件下的不重复个数的计算。
01
不重复个数的计算公式
首先来看如何计算C列的不重复姓名个数,直接上公式:

这是一个数组公式,输入完后需要按CTRL+SHIFT+回车键,自动加上大括号。
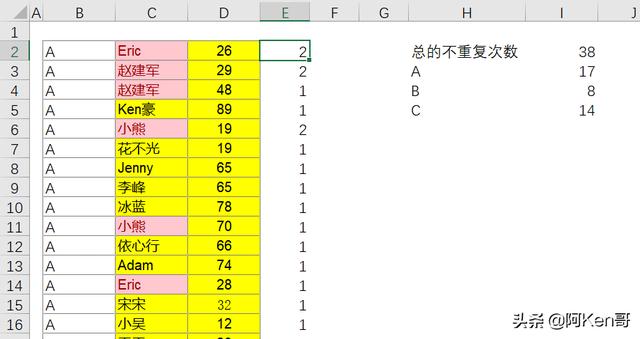
COUNTIF(C2:C45,C2:C45)是计算C列每个名字依次出现的次数,如“花不光”出现了1次,则计算的数组结果中返回1,而“赵建军”出现了两次,则计算的结果中有两个2,如下图E列所示。
再对COUNTIF计算的结果求倒数,如一个名字出现2次,则倒数的对应结果中会出现两个0.5,如只出现1次,则对应的倒数也为1,如下图F列所示:
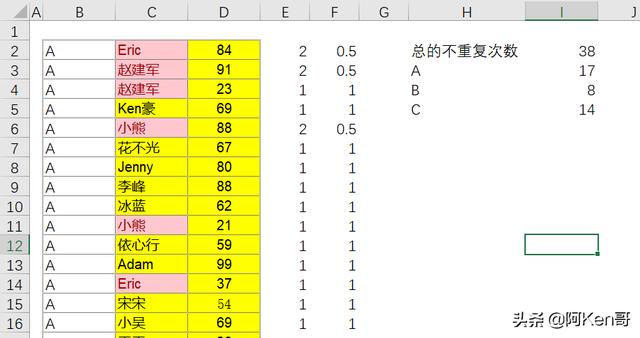
最后,将倒数的结果数组进行SUM求和,得到的其实就是不重复姓名的个数。因为对于重复的名字而言,重复N次,就会产生N个1/N,加起来也是1。
到这里,你应该能理解这串数组公式的含义了吧?
明天 ,继续介绍指定条件下不重复个数的计算。
如果要系统学习函数,可以私信我

















 9593
9593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









