







往期链接:
Spark基础:Spark SQL入门 Spark基础:数据读写 Spark基础:读写Parquet Spark基础:读写Hive Spark基础:读写JDBC Spark基础:Spark SQL优化 Spark基础:分布式SQL查询引擎 Spark基础:Hive特性兼容 Spark基础:集群运行 Spark基础:应用提交 Spark基础:Spark on Yarn(上) Spark基础:Spark on Yarn(下) Spark基础:参数配置与内存模型 Spark基础:参数配置(中) Spark基础:参数配置与推测执行 Spark基础:动态资源分配 Spark实战:动态资源分配Spark基础:性能调优
Spark有两层的调度概念,第一层是集群级别,即每个应用在集群中以独立的一组进程的运行;第二种是应用级别,在executor内部多个任务并行的在不同的线程之间运行。本篇先来聊聊集群级别的应用调度,为了满足应用在集群中运行,就需要为这个应用分配专属的资源,如内存和CPU。常见的分配方式有两种:静态资源分配和动态资源分配。
静态资源分配
静态资源分配即最常用的基于指定配置申请固定数量的资源,这些资源专门为这个应用自己所使用。多个应用之间的资源互不影响。在应用运行期间,应用会一直占有这些资源。这种方法适合在standalone、yarn以及粗粒度的mesos模式中使用。资源分配可以根据集群模式的不同如下进行分配:
在standalone模式中,默认应用提交按照先进先出的顺序,每个应用尝试获取可用的节点。可以通过 spark.cores.max 限制每个应用可以使用的核数,或在应用中配置 spark.deploy.defaultCores 。最后,不仅可以控制核数,还可以通过 spark.executor.memory 配置使用的内存。
在mesos中,通过配置 spark.mesos.coarse=true 允许开启粗粒度的资源调度,配置 spark.cores.max 限制每个应用可以申请的核数,spark.executor.memory 控制内存
在yarn中,在客户端启动时配置 --num-executors 用于控制executor的数量,也可以使用 spark.executor.instances 在程序中配置。使用 --executor-memory 或 spark.executor.memory 控制内存,使用 --executor-cores 或 spark.executor.cores 控制核数。
另一种方式是在mesos中使用动态共享CPU,在这种模式下,每个Spark应用都有独立的内存分配,但是当应用在某台节点上没有运行任务时,其他的任务可以使用这些CPU运行其他的任务。这种模式在需要启动非常多应用且占用的资源比较多时,比如为不同的用户启动spark shell会话。当然这也会使应用运行带来一定的延迟,因为应用释放后再重新获取资源时,需要重新请求集群申请资源。为了使用这种模式,可以配置master为mesos://并配置 spark.mesos.coarse为false。注意目前内存暂时没有这种共享机制,如果你希望用这种方式来分享数据,推荐在一个应用中多次访问相同的RDD即可。
动态资源分配
spark提供了一种基于负载动态申请资源的机制,也就是说应用可以在空闲时归还申请的资源,这个特性对于有多个应用程序共享集群资源的场景非常有用。比如常用的大数据笔记本zeppelin,最大的劣势就是启动了一个统一的spark,多个用户共享这个spark,当一个人运行了一个超大的任务,其他人都需要排队执行。如果可以动态申请资源,那完全可以为每个用户申请一个spark,而无需担心申请了太多的资源,浪费集群资源,因为不执行代码的时候,executor会被自动释放掉。不过由于这个特性需要开启其他的服务,因此默认是关闭的。
配置和启动
想要使用动态资源分配需要两个前提,首先需要在应用中配置 spark.dynamicAllocation.enabled 为true;其次需要在调度框架如yarn中开启外部shuffle服务并配置 spark.shuffle.service.enabled 为true。开启外部shuffle服务是为了当executor移除的时候不会删除shuffle的文件。在不同的资源调度框架中,配置的方法不同。在standalone模式中,只需要配置 spark.shuffle.service.enabled 为true即可;在mesos粗粒度模式中,在使用 $SPARK_HOME/sbin/start-mesos-shuffle-service.sh 在每个slave节点启动,并配置 spark.shuffle.service.enabled 为true。你可以使用Marathon来做这个工作。在yarn中,可以参考之前的分享。所有相关的配置都以 spark.dynamicAllocation. 和 spark.shuffle.service. 命名开头。
资源申请策略
通过动态资源申请,spark会释放不再使用的executor,当需要的时候再申请。由于没有明确的方法判断executor是否真的空闲或者紧缺,因此可以通过下面的方式来初步的判断:
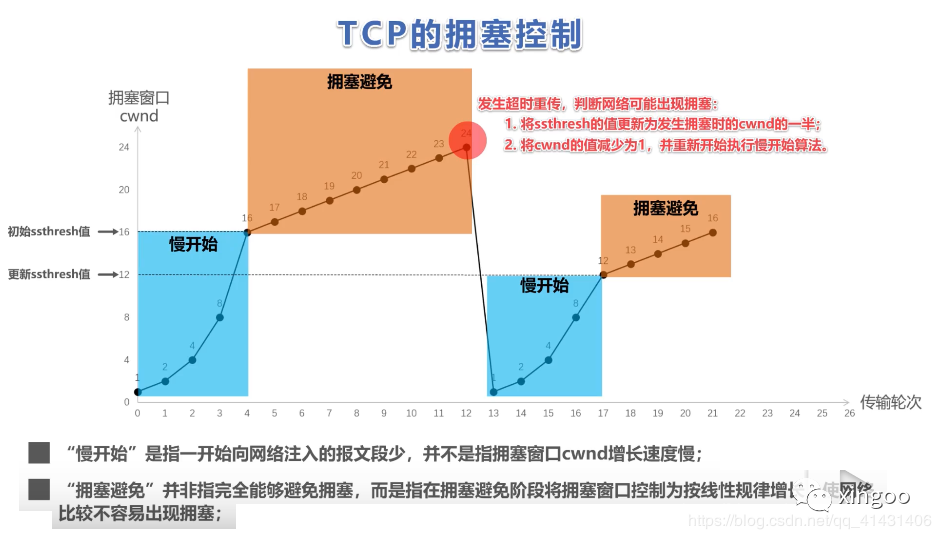
请求策略:一般当任务在调度时被阻塞,就说明目前的executor资源不足,无法满足任务的正常运行。Spark会在任务阻塞一段时间后申请资源,阻塞时间为 spark.dynamicAllocations.schedulerBacklogTimeout 秒,然后每隔 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 触发一次,执行申请操作。申请的机制模仿TCP拥塞控制的机制,慢开始快增长,即第一次发现资源不足时申请1个excutor,之后申请2个,再申请4个...。
删除策略:删除策略更简单,只要executor在 spark.dynamicAllocation.executorIdleTimeout 时间内空闲,就会被移除。
优雅的executor释放
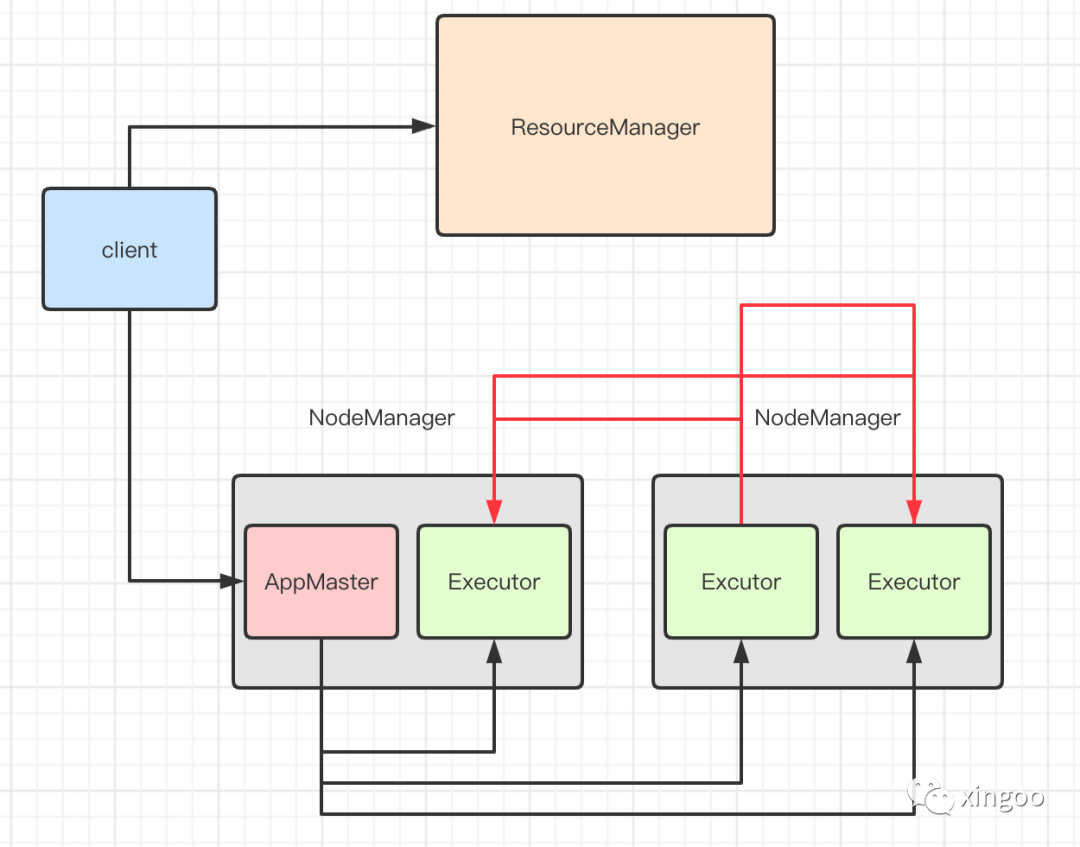
在使用动态分配之前,spark的executor会在失败或关联的应用退出时退出。在这两种场景里,executor相关的状态信息也会被删除。在使用动态分配时,当exector被移除时,应用还在正常运行,此时如果应用尝试读取存储在executor中的数据时,会触发数据的重新计算。因此spark需要有一种机制能让executor优雅的退出而不删除相关的数据。这个需求对于shuffle的场景非常重要,在shuffle中,executor会把map输出的内容保存到本地内存或者磁盘,并作为服务器提供其他的executor访问这些数据。在数据倾斜场景中经常会遇到,某个executor的任务可能运行时间比其他的任务长很多,当长时间的任务执行完毕时,最开始计算出结果的那批数据很有可能已经被移除,此时就会导致其他的executor计算出的结果需要再次重新计算。
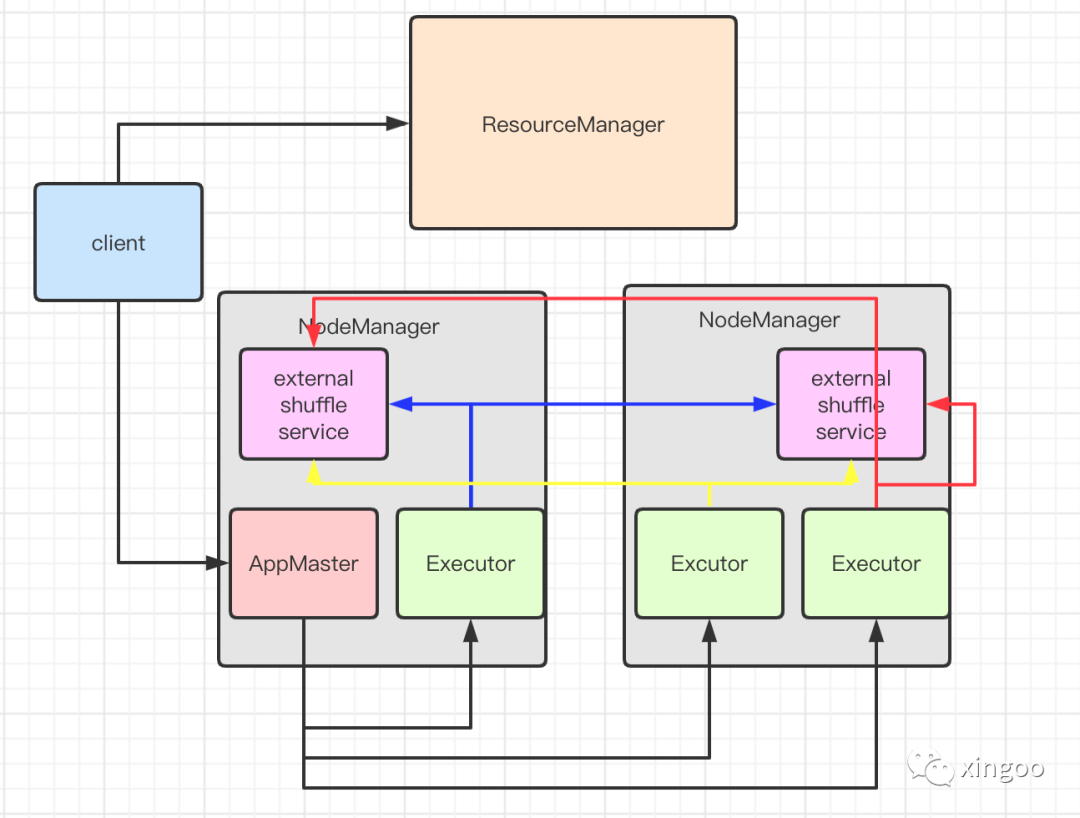
目前比较好的解决方案是引入外部的shuffle服务,在每个节点上启动一个独立的长期运行的进程。spark会通过这个服务来请求shuffle的结果数据,这样shuffle的数据就可以在应用整个生命周期任意访问了,而无需关心对应的executor是否存活。由于shuffle的时候数据既可以保存在内存中也可以保存在磁盘中,当executor退出时,内存中的数据也需要保留,可以通过配置 spark.dynamicAllocation.cachedExecutorIdleTimeout 控制缓存的时间。在未来的版本中,缓存的数据也可以通过外部shuffle服务使用堆外内存来存储。















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









