







1.背景
人脸识别是计算机视觉中的基础问题,也是一项非常庞大而又复杂的问题,如何做到真实场景下的商用很长时间都是学术和工程上的难题。发展至今,人脸识别算法在国内长期被百度、Face++、虹软等大厂所垄断。
政通人脸识别算法(ZTFace)的落地,摆脱了第三方算法在调用频次和算法能力上的限制,可以更加灵活、高效的适配各种复杂场景,并且依托公司自有的大量项目实战积累,识别精度和效率不断提升。
2 技术总览
"人脸识别"这个词其实包含了许多子模块,对于一个人脸识别系统而言,往往包含以下几个模块:- 人脸检测(Face Detection):即从各种不同的场景中检测出人脸的存在并确定其位置。
- 人脸对齐(Face Alignment):校正人脸在尺度、光照和旋转等方面的变化。
- 人脸特征表征(Feature Embedding):通常将人脸映射到一个高维特征空间用于后续的人脸检验,例如将人脸表征为128维或者512维向量,然后通过计算不通人脸向量的欧式距离或者余弦距离用于人脸校验。
- 人脸校验(Face Verification ):采取某种方式表示检测出人脸和数据库中的已知人脸,确认两张脸是否是同一个人。
- 人脸识别(Face Recognition):将待识别的人脸与数据库中的已知人脸比较,得出给你的脸是库里的谁。
- 活体检测(Anti-Spoofing):判断捕捉到的人脸是真实人脸,还是伪造的人脸攻击(如:彩色纸张打印人脸图,电子设备屏幕中的人脸数字图像 以及 面具 等)。
- 人脸属性识别(Attribute Recognition):性别、年龄、种族、表情、戴口罩等属性识别。
3 基础知识介绍
3.1 深度学习(Deep Learning)
深度学习是人工智能中研究最火热的领域之一,那么何为深度学习?
在深度学习中,卷积神经网络通常用于图像处理相关的问题。从2013年卷积神经网络获得当年ImageNet(一个图像识别的比赛,包含了数百万的图片,1000个类别)冠军开始,并且随着计算力的提升,深度学习获得突破性进展,人们可以使用GPU或者FPGA加速训练海量的数据用于特定的任务。 那么深度学习到底有多深? 目前常见的神经网络从十几层到一百多层不等,最深的可达上千层。 构建如此复杂的神经网络是非常困难的,幸好有许多开源的深度学习框架,例如谷歌的TensorFlow,Facebook的PyTorch等等,使得研究者可以逐层构建自己的网络并且利用丰富的优化器(各种梯度下降算法)训练自己的网络模型。深度学习背后的主要原理是从大脑中汲取灵感。这种观点产生了“神经网络”术语,大脑包含数十亿个神经元,它们之间有无数个连接。在许多情况下,深度学习算法类似于大脑,因为大脑和深度学习模型都涉及大量的计算单元(神经元),深度学习模仿人脑,通过构造深层的神经网络,然后通过大量标注或者未标注的样本去学习,从而能够处理相应的实际问题。
例如对于一个猫和狗的识别问题,可以构造一个卷积神经网络(Convolutional Neural Network,CNN),然后用一些标注好猫和狗的图片去训练这个网络,那么这样一个网络就可以很好的区分猫和狗这两种动物,整个过程,就像父母拿着猫和狗的画册一张张教一个幼儿去识别这两种动物。
4 算法原理
4.1人脸检测
基于目标检测网络RetinaNet网络优化,通常的目标检测算法需要识别的目标的尺度大小和长宽比例的分布是非常宽泛的,人脸具有一般目标的尺度多样性,但是比例相对比较固定,一般长宽比例接近1:1,因此我们的Anchor设计可以使用更多的变化的尺度,而比例固定为1。 完整的人脸检测模型设计思路如下图: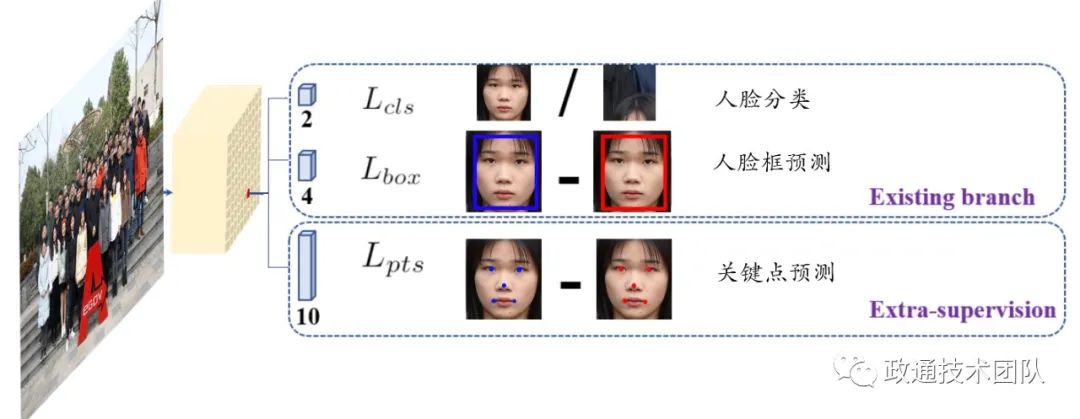
第一个分支是一个二分类问题,用于判断当前Anchor是否是一张人脸。
第二个分支用于预测人脸的具体位置,这里只需要回归出人脸框的中心坐标(x,y)和宽高(w,h)四个数值(x,y,w,h)相对于Anchor的偏移量。
第三个分支用于预测人脸关键点,方法同分支二一样,只需要回归出关键点(x1,y1),(x2,y2)...相对于Anchor的偏移量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









