





Python Multiprocessing Best Practice
Background Knowledge
- Python的线程由于存在全局解释器锁GIL,所以同一时刻无论启用了几个线程、计算机CPU有几个核心,一个Python程序只能有一个线程的指令在运行。这种线程的处理方式可以被看做“假线程”。Python的线程只有在I/O密集型的任务函数上会带来较大的速度提升,而对CPU运算密集型任务,则并无法提供足够的加速。而进程不存在这个问题,所以可能的情况下建议使用进程,以获得更高的效率。
- Java、C++等语言都不使用GIL,且Python本身也并不包含GIL。GIL是实现 Python 解析器(CPython)时所引入的一个概念,像JPython等其他解释器就没有GIL。但由于默认的解释器都是CPython,所以GIL经常被和Python放在一起。
- GIL的本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个“任务”所修改,进而保证数据安全。GIL的作用是保证线程与线程之间的安全,这里的安全是字节码级别的,而不是用户数据级别的,所以如果使用线程的时候不加mutex互斥锁,算出来的结果还是错的。
Points
- Python的进程库可以看做主要解决了如下问题:怎样定义进程(
Process),怎样管理进程(Pool),怎样同步进程(Lock),线程间如何交换数据(Queue,Pipe)(有存有取),进程间怎样共享数据(Value,Array,Manager)(自由修改,不限存取)。 Process实例被定义后需要先.start(),如需等待其完成,则使用.join()。Pipe类实例化时会同时返回管道两端:parent_conn, child_conn = Pipe()。两端都有着.send()和.recv()功能。管道的两端可以同时读或写,但如果管道的某一端被同时读写,将会产生数据问题。Queue类具有.put()和.get()功能。前者向队列尾部压入一个数据,后者从队列头部提取一个数据。这里的Queue在功能上和queue.Queue近似,但它是进程安全的。Lock类可以.acquire()和.release()。前者获取锁,后者释放锁。在进行I/O操作、打印输出时建议使用。但请不要寄希望于加锁的全局变量。共享变量请使用Value和Array类,更复杂的内容如字典等可以使用Manager类开启一个server进程集中控制。Manager类使用时请加with进入上下文管理模式,同样是因为在出现问题时可以对manager进程和其中变量进行清理。Manager类支持共享list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Barrier,Queue,ValueArray这些类,十分方便。但记住,它单独开启了一个监听进程,它是很重的。- 使用进程池
multiprocessing.Pool时,请使用with语句对其进行上下文管理。这是因为使用了with之后,无论其中的进程发生了什么,或是主进程发生了什么(比如被杀死),这些子进程都会被妥善的关闭处理掉。 - 单独提一下,如果希望在Pytorch中使用
multiprocessing进行多进程训练,Pytorch官网提供了专门的解决方案,以供CUDA张量共享。使用方法几乎和Python原生一致,只是改动import即可:import torch.multiprocessing as mp
Comparison
首先,当我们已经确定了要使用Pool来管理多进程后,Pool下的多个函数的区别就显得较为重要了。这些函数分别是:map, starmap, imap, map_async, imap_unordered, apply, apply_async.
核心功能对比
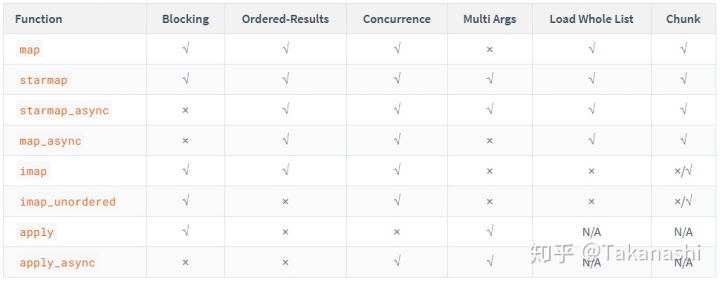
核心功能辨析
Pool自身:- 若想等待
Pool中的全部非阻塞式的方法结束,则应该使用.join()方法。但需要注意的是,调用.join()方法前一定要先执行.close()或.terminate()。 .close()或.terminate()的区别是,.close()只是阻止新的进程被提交到Pool中,但并不杀死已经存在的进程;而.terminate()则是既阻止新的提交,又立即杀死全部已经在Pool中的进程。imap系列:imap和imap_unordered默认情况下不做chunk,即不会把全部的Iterable切分成几大块送到不同的进程中去,而是一个个的把Iterable中的项目送到有空闲的进程中。这样会在每个进程任务结束很快的情况下导致严重的数据发送Overhead,所以可以通过指定一个合理的chunksize来减少这个Overhead。imap和imap_unordered并不会在分配语句完成后自动开始执行这些线程。它们一定是阻塞的,并且需要用一个循环来调用这些返回的result时才会被执行。这个循环等待相当于另外几个异步函数的callback函数。apply系列:apply和apply_async都是每次只提交一个任务。有多个任务时它们的使用可以通过循环或列表生成来做。async系列:- 当我们使用非阻塞型(异步)的方法(
map_async,starmap_async,apply_async)时,若想取得该进程的运算结果,需要使用.get()函数,该函数会阻塞式地等待,直到该进程执行完毕,返回结果。如果想设置最长等待时间,则可以设置如.get(timeout=3)一样的参数。 - 几个支持异步工作的方法都可以传入两个
callback函数,一个是callback,另一个是error_callback。这两个函数都分别只接收一个输入,即进程工作函数的返回值,前者会在进程正常结束并返回一个有效值的时候被调用,而后者则在进程发生错误未能正常结束退出时候被调用。它们可以避免不断调用.get()函数等待的问题。 - 支持多参数系列:
- 支持多个参数输入到进程工作函数的方法(
starmap,starmap_async,apply,apply_async)的参数项(即传入的第二项一定要是一个元组。即使只有一个量,也要在后面加,,即使没有参数传,也至少要加一个()。如:res = pool.apply_async(f, (20,)),res = pool.apply_async(os.getpid, ())
Pool各种小示例
from multiprocessing import Pool, TimeoutError
import time
import os
def f(x):
return x*x
if __name__ == '__main__':
# start 4 worker processes
with Pool(processes=4) as pool:
# print "[0, 1, 4,..., 81]"
print(pool.map(f, range(10)))
# print same numbers in arbitrary order
for i in pool.imap_unordered(f, range(10)):
print(i)
# evaluate "f(20)" asynchronously
res = pool.apply_async(f, (20,)) # runs in *only* one process
print(res.get(timeout=1)) # prints "400"
# evaluate "os.getpid()" asynchronously
res = pool.apply_async(os.getpid, ()) # runs in *only* one process
print(res.get(timeout=1)) # prints the PID of that process
# launching multiple evaluations asynchronously *may* use more processes
multiple_results = [pool.apply_async(os.getpid, ()) for i in range(4)]
print([res.get(timeout=1) for res in multiple_results])
# make a single worker sleep for 10 secs
res = pool.apply_async(time.sleep, (10,))
try:
print(res.get(timeout=1))
except TimeoutError:
print("We lacked patience and got a multiprocessing.TimeoutError")
print("For the moment, the pool remains available for more work")
# exiting the 'with'-block has stopped the pool
print("Now the pool is closed and no longer available")Examples
Pool
这里我们先定义好一个用于执行多线程工作的函数,它会随机sleep 1~10秒。
import time
import random
from multiprocessing import Pool
def sleep_func(n):
print(f"==> Process {n} is sleeping.")
second = random.randint(1,10)
for i in range(second):
time.sleep(1)
print(f"==> Process {n} has slept for {second} seconds.")
return n*n下面给定了两个较为常用的例子:
imap_unordered
if __name__ == "__main__":
with Pool() as pool:
workers = pool.imap_unordered(sleep_func, range(10))
results = []
for result in workers:
results.append(result)
print(f"Results: {results}")
# [Out]: Results: [25, 9, 4, 0, 16, 1, 36, 49, 81, 64]map
if __name__ == "__main__":
with Pool() as pool:
results = pool.map(sleep_func, range(10))
print(f"Results: {results}")
# [Out]: Results: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]以下实例来自Python多进程官方文档
Manager
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)Lock
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()Shared Memory: Value, Array
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])Pipe
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()Queue
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()Reference
- Official: multiprocessing — Process-based parallelism
- 深入理解GIL
- Python multiprocessing.Pool: Difference between map, apply, map_async, apply_async
- Python Multithreading and Multiprocessing Tutorial(讲的非常详细,包含线程进程底层原理)
- Python 多进程池进行并发处理
- Python多进程最佳实践(Process)
- Why your multiprocessing Pool is stuck (it’s full of sharks!)
- multiprocessing: map vs map_async
- Pytorch多进程最佳实践















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









