







论文:https://arxiv.org/pdf/1609.03605.pdf
Tensorflow实现:eragonruan/text-detection-ctpn
一、网络结构
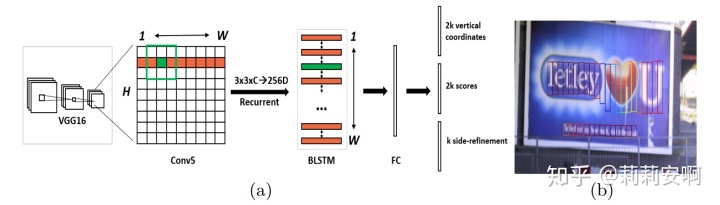
- 首先,使用VGG16作为base net提取特征,将conv5_3作为输出,大小是B×H×W×C;
- 在conv5_3上做3x3滑窗(这里的滑窗在tensorflow中的代码实现就是卷积操作),经过滑窗后得到的feature map大小仍为B×H×W×C,但此时的每个像素点融合了3*3*C的信息。(论文作者使用caffe中的im2col实现的滑窗操作,将B×C×H×W大小的feature map转换为B×9C×H×W,本文只讨论tensorflow版本的代码实现);
- B×H×W×C大小的feature map经过BLSTM得到[B*H,W,256]大小的feature map;
- [B*H,W,256]大小的feature map接一个卷积层(FC代表卷积),输出[B*H,W,512];
- [B*H,W,512]分成三个预测支路(实际上就是使用矩阵乘法强行将输出转换为想要的形状);
[B,H,W,K*2],2K个vertical coordinate,对某个像素点的某个anchor预测;
[B,H,W,K*2],2K个score,记为s=[text,non-text];
[B,H,W,K],K个side-refinement,对某个像素点的某个anchor预测;
K代表每个像素点设置的Anchor的个数,文中K=10;这里的及 s 是网络预测输出,下文提到的
及
是真值标签;
- 根据上面的输出结果,可以得到密集的text proposal,使用NMS算法抑制掉多余的box,抑制后的效果如图一中的(b);
- 使用文本线构造方法将上述得到的一个一个的文本段合并成文本行。
通过上述网络,在步骤5可以得到网络预测输出。先通过训练使得网络预测值准确率足够高,训练完成后直接使用预测值进行nms及文本线构造(后处理)得到最终的文本检测结果。接下来,我将从如何训练网络及如何进行后处理两部分进行说明。
二、如何训练网络?
- 数据预处理
- 网络:
前向网络:网络inference
后向网络:如何计算loss 及最小化loss(优化器的选择) - 训练:加载预训练好的权重+保存权重及运行日志(代码见main/train.py,可以参考这里)
补充说明:CTPN中的Anchor
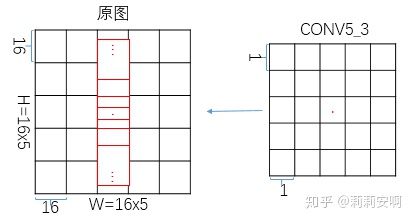
Anchor概念源于Faster R-CNN(要想彻底理解CTPN,建议首先掌握Faster R-CNN中的RPN),简单来说,Anchor就是在feature map上每个像素点中心设置K个针对原图尺寸的框。
CTPN在conv5_3 feature map的每个像素点中心设置K=10个针对原图尺寸的Anchor。这10个Anchor的宽度固定为16,高度设置为[11,16,23,33,48,68,97,139,198,283](依次除以0.7),如图二所示(仅画四种高度进行示意)。
为什么这样设置Anchor?
(1)文本长度变化剧烈,直接预测十分困难。相较于宽度,文本高度变化相对小一些。因此作者固定宽度,先在竖直方向进行预测,再通过文本线构造方法得到文本行。
(2)CTPN采用VGG16模型提取特征,conv5_3 feature map的大小是原图的1/16。因为设置的Anchor针对原图尺寸,所以将宽度固定为16,这样可以确保无重叠的覆盖原图水平方向每个像素点。
(3)Anchor高度的设置原则是尽可能涵盖样本集的文本高度。
1.数据预处理(代码见util/prepare/split_label.py)
(1)处理图像尺寸
保持图片比例不变且短边
img = cv.imread(img_path)#读取图像
img_size = img.shape#获取图像的[h,w,c]
im_size_min = np.min(img_size[0:2])#获取h,w中较小的
im_size_max = np.max(img_size[0:2])#获取h,w中较大的
#保持宽高比不变,且短边不大于600,长边不大于1200
im_scale = float(600) / float(im_size_min)
if np.round(im_scale * im_size_max) > 1200:
im_scale = float(1200) / float(im_size_max)
new_h = int(img_size[0] * im_scale)
new_w = int(img_size[1] * im_scale)
#使得图像的w,h都是16的整数倍
new_h = new_h if new_h // 16 == 0 else (new_h // 16 + 1) * 16
new_w = new_w if new_w // 16 == 0 else (new_w // 16 + 1) * 16(2)处理ground truth
一般数据库给的都是整个文本行或者单词级别的标注,如图三所示。我们需要对人为设置的Anchor进行Bounding box regression,回归的范围是有限的,因此需要将ground truth处理成一系列固定宽度的box,如图四所示。


处理ground truth的大致流程如下:
- 得到在resize后的图像上的gt尺寸
- 使gt坐标为顺时针,即:左上角=[x1,y1],右上角=[x2,y2],右下角=[x3,y3],左下角=[x4,y4]
- 将原始标注划分为宽度16的四边形(首尾四边形宽度不一定为16)
- 取四边形坐标中的x_min, y_min, x_max, y_max,构成划分后宽度为16的矩形坐标
2.网络
2.1 前向网络(代码见nets/model_train.py)
conv5_3 = vgg.vgg_16(image)#VGG16作为base net提取特征,将conv5_3作为输出
rpn_conv = slim.conv2d(conv5_3, 512, 3)#在conv5_3上做3x3滑窗
#B×H×W×C大小的feature map经过BLSTM得到[B*H,W,256]大小的feature map
lstm_output = Bilstm(rpn_conv, 512, 128, 512, scope_name='BiLSTM')
#本代码做了调整:1.[B*H,W,256]大小的feature map没有接卷积层(FC代表卷积) 2.[B*H,W,256]大小的feature map直接预测的四个回归量
bbox_pred = lstm_fc(lstm_output, 512, 10 * 4, scope_name="bbox_pred")#网络预测回归输出
cls_pred = lstm_fc(lstm_output, 512, 10 * 2, scope_name="cls_pred")#网络预测分类输出B×H×W×C大小的feature map如何通过BLSTM得到[B*H,W,256]大小的feature map?
BLSTM在tensorflow中可以通过如下方式实现:
(outputs, output_states) = tf.nn.bidirectional_dynamic_rnn(
cell_fw, # 前向RNN
cell_bw, # 后向RNN
inputs, # 输入向量
sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度)
initial_state_fw=None, # 前向的初始化状态(可选)
initial_state_bw=None, # 后向的初始化状态(可选)
dtype=None, # 初始化和输出的数据类型(可选)
parallel_iterations=None,
swap_memory=False,
time_major=False,
# time_major=true, 参数inputs及outputs的形状必须为 `[max_time, batch_size, depth]`.
# time_major=false, 参数inputs及outputs的形状必须为`[batch_size, max_time, depth]`.
scope=None
)其中的参数inputs就是大小为B×H×W×C的feature map。由于inputs要求的形状为[batch_size, max_time, depth],那么两者如何对应呢?
对一张输入图片而言,BLSTM提取的只是文本水平方向的关联性,行与行之间相互独立,batch之间自然也相互独立,因此BH可以当做输入BLSTM的batch_size;将feature map的每一行作为一个时间序列 max_time输入BLSTM,如图一所示,BLSTM中时间序列 max_time对应W;每个时间序列的维度depth对应feature map通道数C(注意论文作者使用caffe中的im2col实现的滑窗操作,每个时间序列的维度depth对应feature map通道数为3*3*C);因此[batch_size, max_time, depth]=[B*H,W,C]。
outputs为(output_fw, output_bw),包含前向cell输出和后向cell输出组成的二元组。通常使用tf.concat(outputs,-1)将其拼接。拼接后outputs的形状为[B*H,W,2 * hidden_unit_num]。代码中LSTM有128个隐层单元数,故BLSTM有256个隐层单元数,故outputs=[B*H,W,256]。
2.2 后向网络(下面给出原文的损失函数,tensorflow的代码直接回归
损失函数
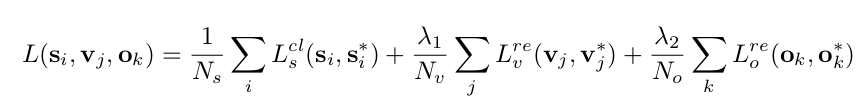
loss由三部分组成:
分类损失:
anchor竖直方向的回归损失:
anchor水平偏移量回归损失:
如何计算
(1)Anchor(下标带a的)与ground truth间的中心坐标平移量
(2)分类的真值标签通过计算Anchor与ground truth的IoU来确定。IoU是指Anchor与ground truth面积的交并比。
- Anchor与ground truth IoU大于0.7的anchor定义为正样本(
);
- Anchor与ground truth IoU小于0.3的anchor定义为负样本(
);
- 按照上面的做法,会出现一个问题,可能有些真值框找不到心仪的Anchor,那这些训练数据就没法利用了。因此我们用一个折中的办法来保证每个真值框至少有一个Anchor与之对应:与ground truth IoU最大的那个anchor也定义为正样本,这个时候不考虑IoU大小有没有大于0.7。
为什么不直接回归
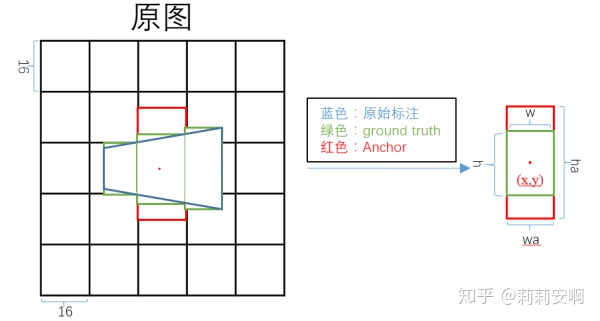
根据上述介绍的数据预处理及anchor设置原则,我们可以得到图五(这里只画了一种高度的anchor示意)。
由图五可以看出:
- 中间的ground truth的真值
,
均为常数,故只需要预测
。对某个像素点的k=10个anchor来说,每个anchor都要预测
,因此网络的预测输出为[B,H,W,K*2];
- 对于两侧的ground truth,
不再是常数,因此文中单独对两侧的anchor加了水平偏移量
的回归(不是很清楚为什么不把
一起回归了),因此网络的预测输出为[B,H,W,K]
三、后处理
1.nms:参考NMS原理,使用nms后可以得到图六所示的text proposals。
2.文本线构造
获得了图六所示的一串或多串text proposal,接下来就要采用文本线构造办法,把这些text proposal连接成文本行。
文本行是由一系列大于
-
是距离
水平距离最近的text proposals;
-
和
的水平距离小于
个像素值;
-
和
的竖直方向的重合率大于
。
其中














 5823
5823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









