







很多时候,我们的智能体是在一个持续无限连续的环境中进行互动学习的。比如类人机器人,他们就是和人类一样在一个社会空间中不断的自我学习更新。MC控制法在这种情况下就不适用了。
dboyaoao:MC--蒙特卡洛方法zhuanlan.zhihu.com
MC的Evaluation如下,是对于所有阶段任务中特定状态的平均(不太明白的朋友可以参考上面的MC链接)

但是在连续性环境中,是无法获取所有的Gt的,这时候我们改变下Evaluation。
TD(0)-V(一步时间差分法状态函数评估)
根据贝尔曼预期方程,贝尔曼(使用后续状态的值潜在的表示前一个状态的值),我么可以将状态函数写成以下形式。
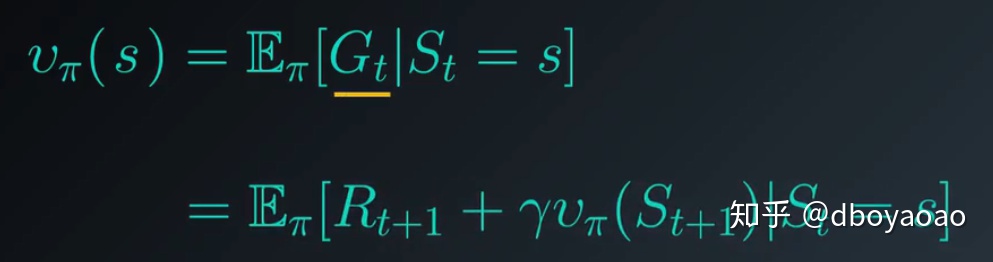
用这个方程对MC的Evaluation方程进行修改
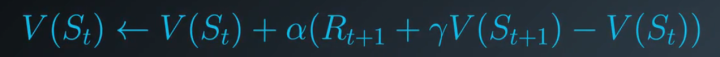
可以发现这样就不需要计算所有阶段任务的和了,也就可以在连续性环境中使用了。这个修改可以使我们在每个时间步之后进行状态值得更新。
如下图所示,在时间t,我们在状态St 执行At,获取到reward Rt+1 以及下一个状态St+1,这是后我们其实就是在这一个很小的时间窗口(t+1 --> t),对St进行更新。获取在时间t是的心得状态估算值。
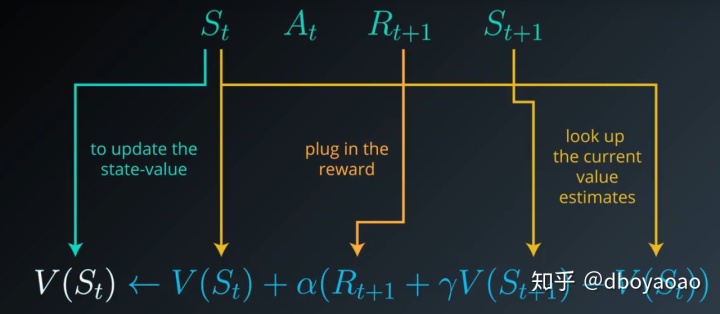
现在就可以发现我们不需要等到阶段结束就可以更新状态值了。good!!!!

我们称这个公式为TD-Target,我们进一步改进下这个公式
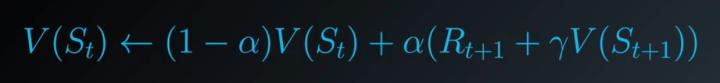
可以发现更新的值其实就是取决于对估算值和之前的状态值,你更看重哪个。
这个算法就叫做TD(0),一步差分。一步就是没执行一个时间步长就进行状态更新。
评估算法:

TD算法也很容易适用于阶段性任务,只要在判断阶段是否结束即可,这里就不多说了。个人感觉TD是比MC更泛化的算法,所以用的也相对比较多了。
TD(0)-Q(一步时间差分法状态动作对评估)
同理,很easy的得出这个结论。
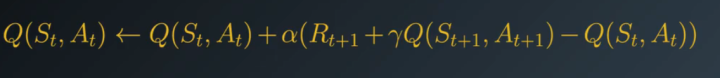
TD控制(Sarsa(0))
sarsa(0)借鉴了MC的方法,在每一个时间步长进行更新后,都会通过


QLearning(SarsaMax)
Qlearning我们从公式上能看出,其实就是在每一次通过下一个状态更新当前状态值得时候,选取最大的动作对的状态值。
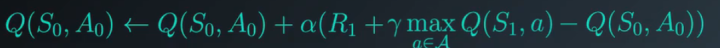
可以看出与TD(0)的区别在于,TD(0)是在当前策略下状态下,通过

Qlearning可以在更新值得过程中就趋向于选取最优策略。
预期Sarsa
还有一种不同于Q学习,它在更新时使用的是下个状态每一个动作的期望值。
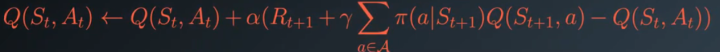

这些算法之间的区别总结如下:
- Sarsa 和预期 Sarsa 都是异同策略 TD 控制算法。在这种情况下,我们会根据要评估和改进的相同(epsilonϵ 贪婪策略)策略选择动作。
- Sarsamax 是离线策略方法,我们会评估和改进(epsilonϵ 贪婪)策略,并根据另一个策略选择动作。
- 既定策略 TD 控制方法(例如预期 Sarsa 和 Sarsa)的在线效果比新策略 TD 控制方法(例如 Sarsamax)的要好。
- 预期 Sarsa 通常效果比 Sarsa 的要好。














 2015
2015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









