







背景:做数据分析,最苦恼的就是没有数据,而在网上最快的获取自己想要信息的方式就是爬虫,研究了两天爬虫,写了个简易的爬虫代码,虽没有专门搞爬虫人员写的那么专业,也基本上满足了自己的需求。代码写的很简陋,欢迎各位提出简易。
一、用到的python库
1、requests库:发送get请求,访问页面;
2、bs4:使用该模块中的BeautifulSoup函数,对相应的链接源代码进行html解析。
import requests
from bs4 import BeautifulSoup
二、构造爬虫链接
本次以爬取链家西安二手房为例,如下图所示
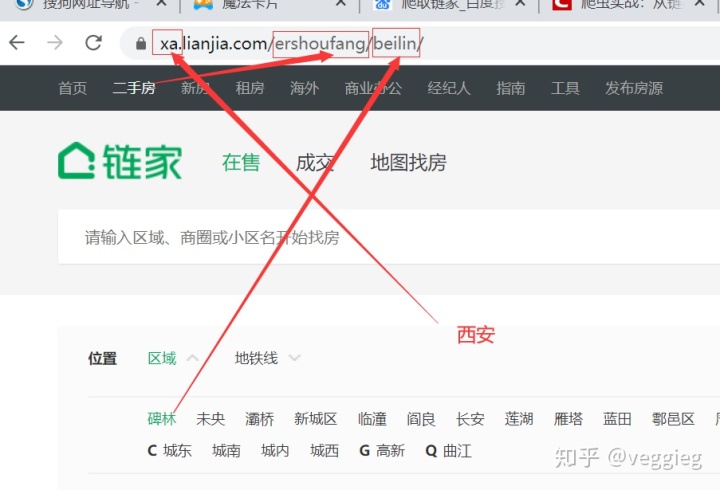
https://xa.lianjia.com/ershoufang/beilin/ ,依此链接为例,“
1、“xa”就是指的西安,如果是其他地区,比如,北京就是bj,上海就是sh,皆是地区名拼音首字母。
2、“lianjia”就是指的链家
3、“ershoufang”就是指的,链家网站中关于二手房的信息
4、“beilin”就是指的西安的碑林区,如果是其他区域,列如,未央区,就是weiyang,雁塔区就是yanta,长安区就是changan4,皆是区域名字汉语拼音。
5、如果是爬取西安地铁线的数据,可以看到四条地铁线的链接分别是,如下:
https://xa.lianjia.com/ditiefang/li110460700/
https://xa.lianjia.com/ditiefang/li110460701/
https://xa.lianjia.com/ditiefang/li3810270424182971/
https://xa.lianjia.com/ditiefang/li3810274779705771/
由上可知,地铁线不同,后面的数字不同。
按照地区不同,可以将,可以将爬虫链接拼接成如下:
url = 'http://xa.lianjia.com/ershoufang/%s/' % i
其中“s%”是格式化字符串,将所有的区域组成列表,regions = ["beilin、yanta、changan4、weiyang、baqiao、xinche
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1488
1488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









