







 本文介绍如何使用Python爬虫获取链家网上二手房信息,包括房源名称和价格。通过分析网页结构,利用requests和BeautifulSoup库抓取数据,并存储为CSV文件。需要注意CSV文件在Excel中可能显示乱码,需转换编码后再用Excel打开。
本文介绍如何使用Python爬虫获取链家网上二手房信息,包括房源名称和价格。通过分析网页结构,利用requests和BeautifulSoup库抓取数据,并存储为CSV文件。需要注意CSV文件在Excel中可能显示乱码,需转换编码后再用Excel打开。
房子问题近些年来越来越受到大家的关注,要了解近些年的房价,首先就要获取网上的房价信息,我们以链家网上出售的房价信息为例,将数据爬取下来并存储起来。
这次信息的爬取我们依然采取requests-Beautiful Soup的线路来爬取链家网上的出售房的信息。需要安装好anaconda,并保证系统中已经有requests库,Beautiful Soup4库和csv库已经安装。
网页分析
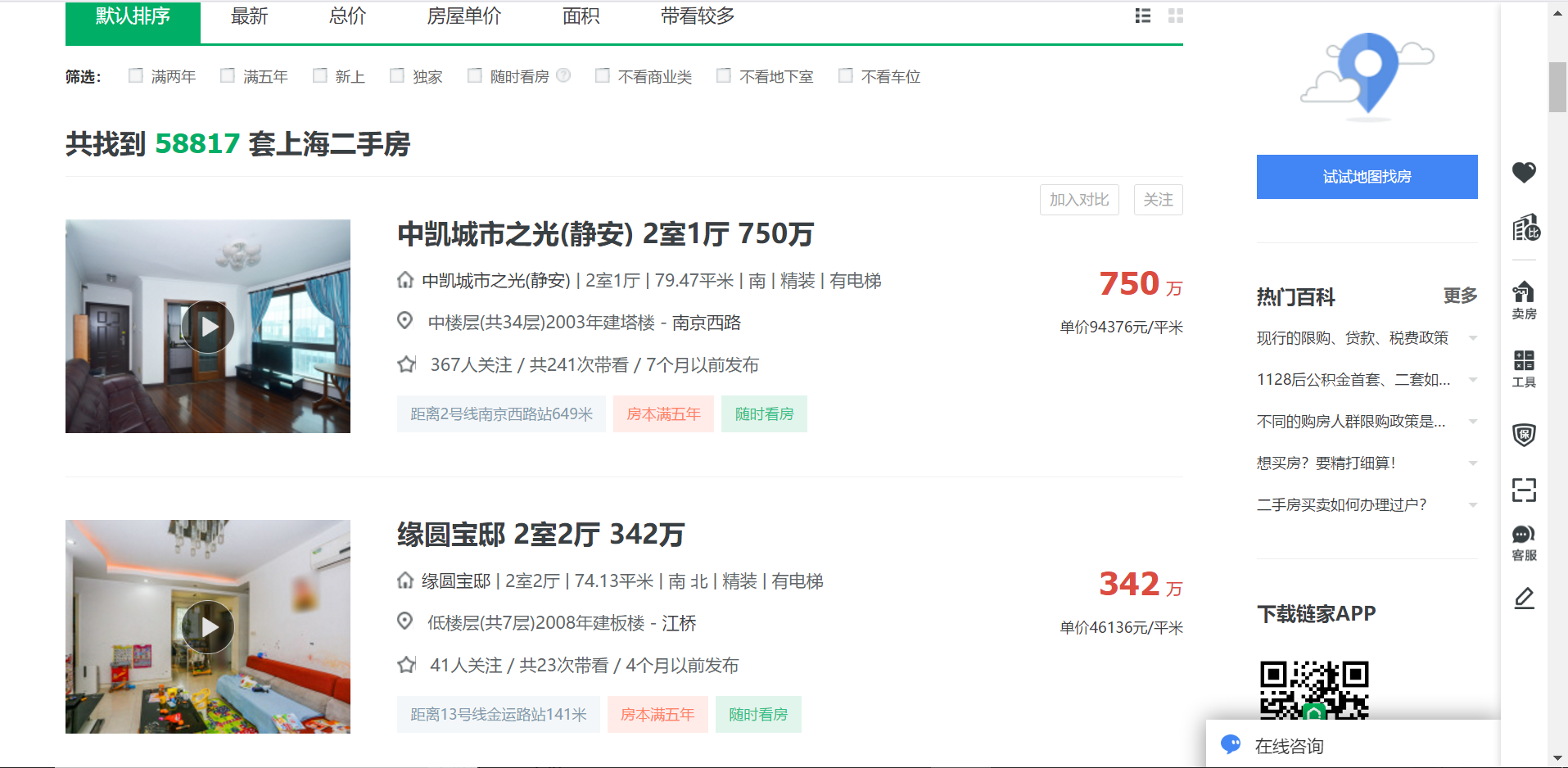
我们要爬取的网页如下,我们需要的信息有房子的名称和价格
https://sh.lianjia.com/ershoufang/
如下图:
下面我们来分析我们所要提取的信息的位置,打开开发者模式查找元素,我们找到房子的名称和价格;如下图:
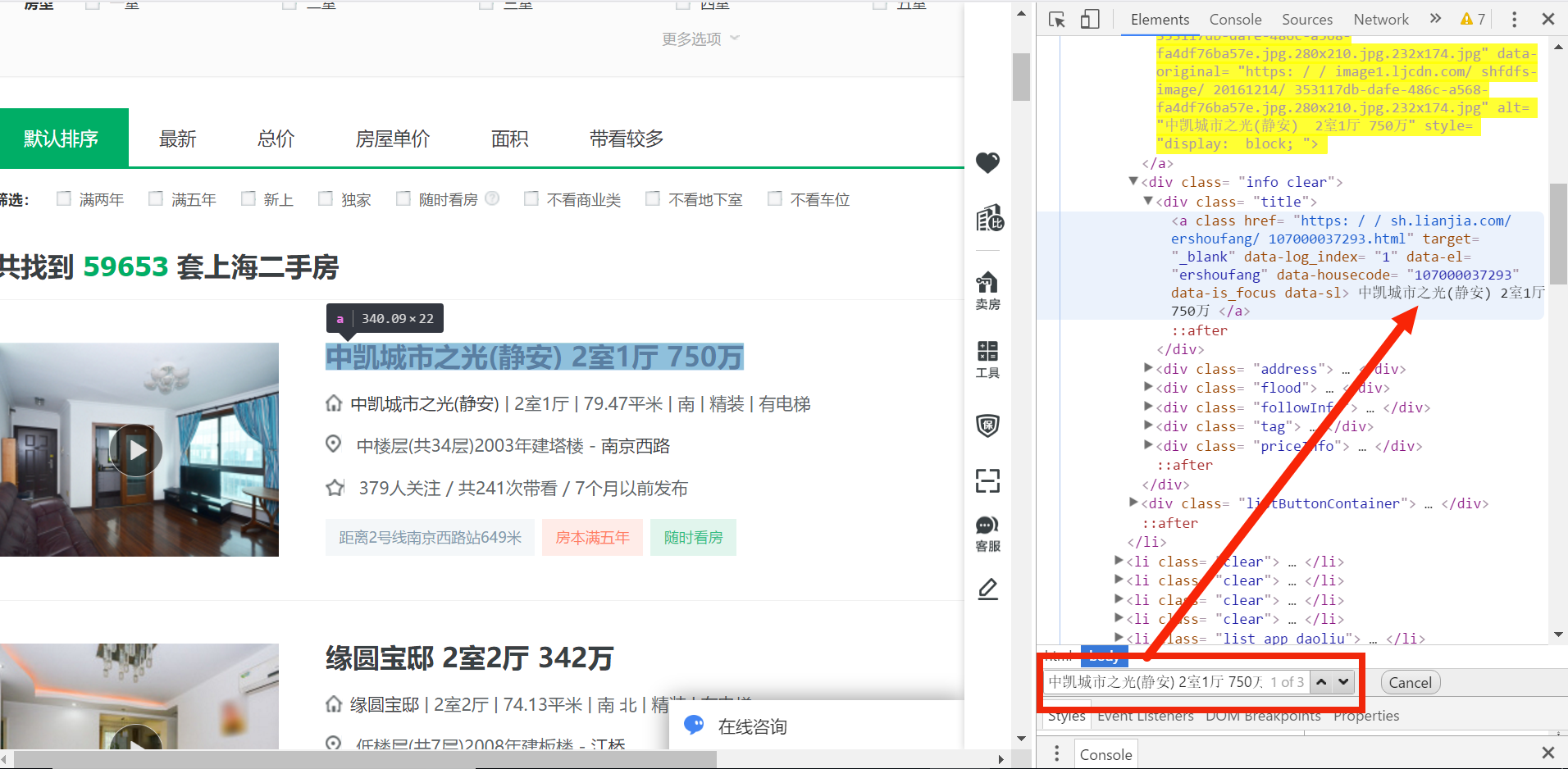
我们可以看到我们所需要的房子名称的信息在{div class="title"}里面,价格信息在{div class="totalPrice"}里面,所有的信息都封装在li标签里面。
我们分析了一个网页里面的网页结构,要爬取其他网页的信息还要看到更多的结构;
第一个网页链接:https://sh.lianjia.com/ershouf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









