





ElasticSearch操作
分页查询中的deep paging问题
GET /lib3/user/_search?from=0&size=2
GET /lib3/user/_search
{
"from": 0,
"size": 2,
"query": {
"terms": {
"interests": [
"乐",
"舞"
]
}
}
}Deep paging有性能问题(尽量减少使用)
1.耗费网络带宽,因为搜索过深,各shard要把数据传递给coordinate node,这个过程是有大量数据传递。
2.消耗内存,各shard要把数据传送给coordinate node,这个传递回来的数据,是被coordinate node保存在内存中的,这样会大量消耗内存。
3.消耗cpu coordinate node要把传回来的数据进行排序,排序过程很消耗cpu.
query string查询及copy_to的使用
copy_to 可把其它属性的值连接在一起后进行搜索,必须自定义索引
同时搜索属性包含有“html“ 或 ”document”,其性能较差
GET /myindex/article/_search?q=html,document使用copy_to方式,把属性“title”和"content"值连接在一起
DELETE /myindex
PUT /myindex
PUT /myindex/article/_mapping
{
"properties": {
"post_date":{
"type":"date"
},
"title":{
"type":"text",
"copy_to": "fullcontents"
},
"content":{
"type":"text",
"copy_to": "fullcontents"
},
"author_id":{
"type":"integer"
}
}
}插入数据
PUT /myindex/article/1
{
"post_date": "2018-05-12",
"title": "html",
"content": "I like html",
"author_id": 120
}
PUT /myindex/article/2
{
"post_date": "2018-05-10",
"title": "java",
"content": "java is the best language",
"author_id": 119
}
PUT /myindex/article/3
{
"post_date": "2018-05-16",
"title": "es",
"content": "ES is distributed document store",
"author_id": 110
}mapping映射
GET /myindex/_mapping
{
"myindex": {
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "integer"
},
"content": {
"type": "text",
"copy_to": [
"fullcontents"
]
},
"fullcontents": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date"
},
"title": {
"type": "text",
"copy_to": [
"fullcontents"
]
}
}
}
}
}
}查询方式:
GET /myindex/article/_search?q=fullcontents:html,document字符串排序问题
对一个字符串类型的字段进行排序通常不准确,因为已经被分词成多个词条了 解决方式:对字段索引两次,一次索引分词(用于搜索),一次索引不分词(用于排序)
创建索引
Keyword不分词,text分词
DELETE /lib3
PUT /lib3
{
"settings": {
"number_of_shards": "5",
"number_of_replicas": "1"
},
"mappings": {
"user": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"birthday": {
"type": "date"
},
"interests": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
},
"fielddata": true
}
}
}
}
}interests 分词,interests.raw不分词,用于排序 fielddata:true 为正排索引
插入数据
PUT /lib3/user/1
{
"name": "晚秋明 WQM",
"address": "广州黄鹂大道西",
"age": 18,
"birthday": "2012-09-08",
"interests": "跑步,听音乐,唱歌"
}
PUT /lib3/user/2
{
"name": "明明 MM",
"address": "深圳市宝安大道",
"age": 35,
"birthday": "2014-09-08",
"interests": "听音乐,唱歌,跳舞"
}
PUT /lib3/user/3
{
"name": "小明 XM",
"address": "广州中山大道",
"age": 31,
"birthday": "2011-09-08",
"interests": "跑步,听音乐"
}
PUT /lib3/user/4
{
"name": "明亮 ML",
"address": "中山市中山大道",
"age": 28,
"birthday": "2013-09-08",
"interests": "跑步,听音乐,唱歌"
}实现字符串排序
GET /lib3/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"interests.raw": {
"order": "desc"
}
}
]
}--result:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": null,
"hits": [
{
"_index": "lib3",
"_type": "user",
"_id": "4",
"_score": null,
"_source": {
"name": "明亮 ML",
"address": "中山市中山大道",
"age": 28,
"birthday": "2013-09-08",
"interests": "跑步,听音乐,唱歌"
},
"sort": [
"跑步,听音乐,唱歌"
]
},
{
"_index": "lib3",
"_type": "user",
"_id": "1",
"_score": null,
"_source": {
"name": "晚秋明 WQM",
"address": "广州黄鹂大道西",
"age": 18,
"birthday": "2012-09-08",
"interests": "跑步,听音乐,唱歌"
},
"sort": [
"跑步,听音乐,唱歌"
]
},
{
"_index": "lib3",
"_type": "user",
"_id": "3",
"_score": null,
"_source": {
"name": "小明 XM",
"address": "广州中山大道",
"age": 31,
"birthday": "2011-09-08",
"interests": "跑步,听音乐"
},
"sort": [
"跑步,听音乐"
]
},
{
"_index": "lib3",
"_type": "user",
"_id": "2",
"_score": null,
"_source": {
"name": "明明 MM",
"address": "深圳市宝安大道",
"age": 35,
"birthday": "2014-09-08",
"interests": "听音乐,唱歌,跳舞"
},
"sort": [
"听音乐,唱歌,跳舞"
]
}
]
}
}如何计算相关度分数
使用TF/IDF算法(Term Frequency&Inverse Document Frequency)
1.Term Frequency:查询的文本中词条在document中出现次数越多,相关度越高
2.Inverse Document Frequency:查询的文本中的词条在索引的所有文档中出现次数越多,相关度越低
3.Field-length(字段长度归约)norm:field越长,相关度越低 --出现次数相近,而field越长,相关度越低
查看分数如何计算:
GET /lib3/user/_search?explain=true
{
"query": {
"match": {
"interests": "音乐"
}
}
}查看一个文档能否匹配上某个查询:
GET /lib3/user/1/_explain
{
"query": {
"match": {
"interests": "音乐"
}
}
}DocValues解析
对排序,分组和一些聚合操作能够提升性能。
非字符串类型除了会建立倒排索,还会建立引正排索引,有正排索引才能排序。
"doc_values":true 不分词处理 "doc_values":false 分词处理
使用方式:
PUT /lib3
{
"settings": {
"number_of_shards": "5",
"number_of_replicas": "1"
},
"mappings": {
"user": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "text"
},
"age": {
"type": "integer",
"doc_values":false
},
"birthday": {
"type": "date"
},
"interests": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
},
"fielddata": true
}
}
}
}
}dynamic mapping策略
dynamic
- dynamic:true 遇到陌生字段 dynamic mapping
- dynamic:false 遇到陌生字段就忽略
- dynamic:strict 遇到陌生字段就报错
例子
PUT /lib8
{
"settings": {
"number_of_replicas": 0,
"number_of_shards": 3
},
"mappings": {
"user": {
"dynamic": "strict",
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": true
}
}
}
}
}下面的“age”属性 与 "dynamic": "strict"设置不符会报错
PUT /lib8/user/1
{
"name":"lisi",
"age":20,
"address":{
"province":"beijing",
"city":"beijing"
}
}date_detection
- 默认会按照一定格式识别date,如 yyyy-MM-dd
- 可以手动关闭某个type的date_detection
- date_detection:false 必须非日期类型,默认为true
-
PUT /lib8
{
"settings": {
"number_of_replicas": 0,
"number_of_shards": 3
},
"mappings": {
"user": {
"date_detection":false,
"dynamic": "strict",
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": true
}
}
}
}
}定制dynamic mapping template(type)
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic_templates": [
{
"en": {
"match": "*_en",
"match_mapping_type": "string",
"mapping": {
"analyzer": "english",
"type": "text"
}
}
}
]
}
}
}使用模板
PUT /my_index/my_type/1
{
"title_en":"this is my dog"
}
GET /my_index/my_type/_search
{
"query": {
"match": {
"title_en": "is"
}
}
}由于与 "match": "*_en" 相匹配,所以使用 "analyzer": "english",导致 上面查询不到结果
没有使用模板
PUT /my_index/my_type/2
{
"title":"this is my dog"
}
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "is"
}
}
}由于与 "match": "*_en" 不匹配,所以不会使用 "analyzer": "english",上面能查询到结果
重建索引且保证应用程序不用重启
一个field的设置是不能修改的,如果要修改一个field,那么应该重新按照新的mapping, 建立一个index,然后将数据批量查询出来,重新用bulk api写入到index中。
批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来reindex数据,每次scroll就查询指定日期的一段数据,交给一个线程即可。
创建一个日期类型的索引
PUT /index1/type1/4
{
"content":"1990-12-21"
}
GET /index1/type1/_search
GET /index1/type1/_mapping放入其它类型的数据,报错
PUT /index1/type1/1
{
"content":"I am very happy."
}尝试修改类型
PUT /index1/_mapping/type1
{
"properties": {
"content":{
"type":"text"
}
}
}索引取别名
PUT /index1/_alias/index2如果新建一个索引,那么在应用程序中使用的是原有的索引,那么就会导致需要重新启动应用程序,为了不用重启应用,使用别名的方式
创建新的索引,把content的类型改为字符串
PUT /newindex
{
"mappings": {
"type1": {
"properties": {
"content": {
"type": "text"
}
}
}
}
}添加数据
把旧的索引中的数据再导入到新的索引中,有可能旧索引中的数据量非常大
使用scroll方式批量查询数据,然后使用bulk再批量添加到新的索引中
GET /index1/type1/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": [
"_doc"
],
"size": 20
}使用bulk再批量添加到新的索引中
POST /_bulk
{"index":{"_index":"newindex","_type":"type1","_id":1}}
{"content":"2000-12-12"}把新的索引和别名进行关联
POST /_aliases
{
"actions": [
{
"remove": {
"index": "index1",
"alias": "index2"
}
},
{
"add": {
"index": "newindex",
"alias": "index2"
}
}
]
}在Java应用中实现查询文档
配置
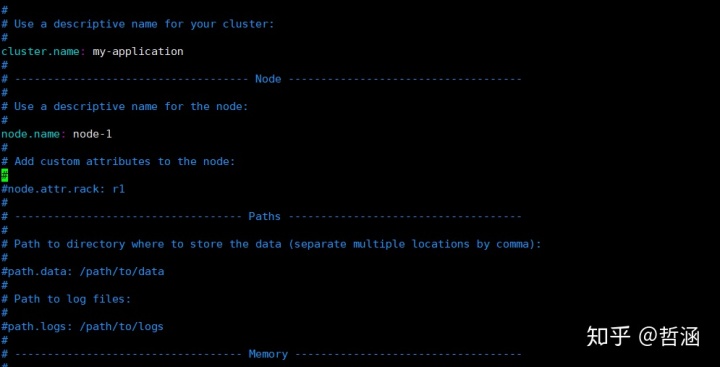
代码
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import java.net.InetAddress;
public class ElasticTest {
//从es中查询数据
@Test
public void test1() throws Exception {
//指定ES集群
Settings settings = Settings.builder().put("cluster.name","my-application").build();
//创建访问es服务器的客户端
TransportClient transportClient = new PreBuiltTransportClient(settings)
.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.1.200"),9300));
//数据查询
GetResponse getResponse = transportClient.prepareGet("lib3","user","1").execute().actionGet();
System.out.println(getResponse.getSourceAsString());
transportClient.close();
}
}














 4139
4139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









