





文件拆分代码:
#-*-encoding:utf-8-*-
import os
import sys
import threading
def getFileSize(file):
file.seek(0, os.SEEK_END)
fileLength = file.tell()
file.seek(0, 0)
return fileLength
def divideFile():
fileFullPath = r"%s" % raw_input("File path: ").strip("\"")
divideTotalPartsCount = int(raw_input("How many parts do you like to divide?: "))
if os.path.exists(fileFullPath):
file = open(fileFullPath, 'rb')
fileSize = getFileSize(file)
file.close()
# send file content
for i in range(divideTotalPartsCount):
filePartSender = threading.Thread(target=seperateFilePart, args=(fileFullPath, divideTotalPartsCount, i+1, fileSize))
filePartSender.start()
for i in range(divideTotalPartsCount):
sem.acquire()
os.remove(fileFullPath)
else:
print "File doesn't exist"
def seperateFilePart(fileFullPath, divideTotalPartsCount, threadIndex, fileSize):
try:
# calculate start position and end position
filePartSize = fileSize / divideTotalPartsCount
startPosition = filePartSize * (threadIndex - 1)
#print "Thread : %d, startPosition: %d" % (threadIndex, startPosition)
endPosition = filePartSize * threadIndex - 1
if threadIndex == divideTotalPartsCount:
endPosition = fileSize - 1
filePartSize = fileSize - startPosition
file = open(fileFullPath, "rb")
file.seek(startPosition)
filePartName = fileFullPath + ".part" + str(threadIndex)
filePart = open(filePartName, "wb")
lengthWritten = 0
while lengthWritten < filePartSize:
bufLen = 1024
lengthLeft = filePartSize - lengthWritten
if lengthLeft < 1024:
bufLen = lengthLeft
buf = file.read(bufLen)
filePart.write(buf)
lengthWritten += len(buf)
filePart.close()
file.close()
sem.release()
print "Part %d finished, size %d" % (threadIndex, filePartSize)
except Exception, e:
print e
sem = threading.Semaphore(0)
while True:
divideFile()
文件重组代码:
#-*-encoding:utf-8-*-
import os
def getFileSize(file):
file.seek(0, os.SEEK_END)
fileLength = file.tell()
file.seek(0, 0)
return fileLength
def rebuildFile():
fileFullPath = r"%s" % raw_input("File base path: ").strip("\"")
divideTotalPartsCount = int(raw_input("How many parts have you divided?: "))
file = open(fileFullPath, "wb")
for i in range(divideTotalPartsCount):
filePartName = fileFullPath + ".part" + str(i+1)
filePart = open(filePartName, "rb")
filePartSize = getFileSize(filePart)
lengthWritten = 0
while lengthWritten < filePartSize:
bufLen = 1024
buf = filePart.read(bufLen)
file.write(buf)
lengthWritten += len(buf)
filePart.close()
os.remove(filePartName)
file.close()
while True:
rebuildFile()
拆分文件演示:
源文件:
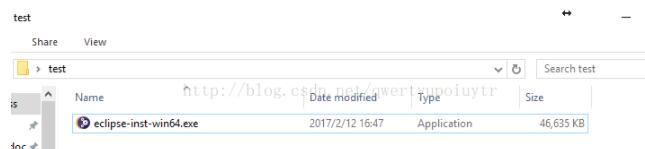
拆分:
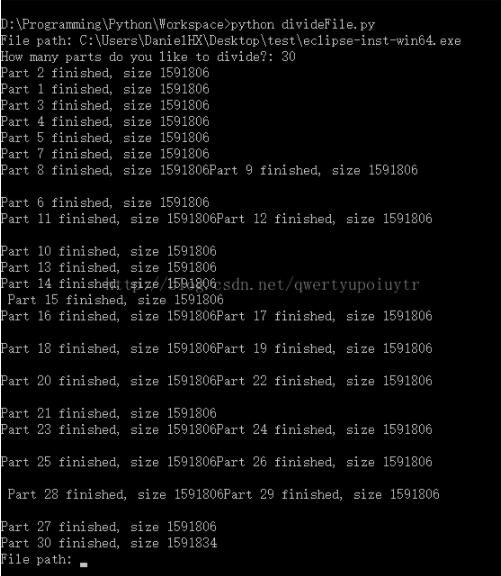
拆分后文件:
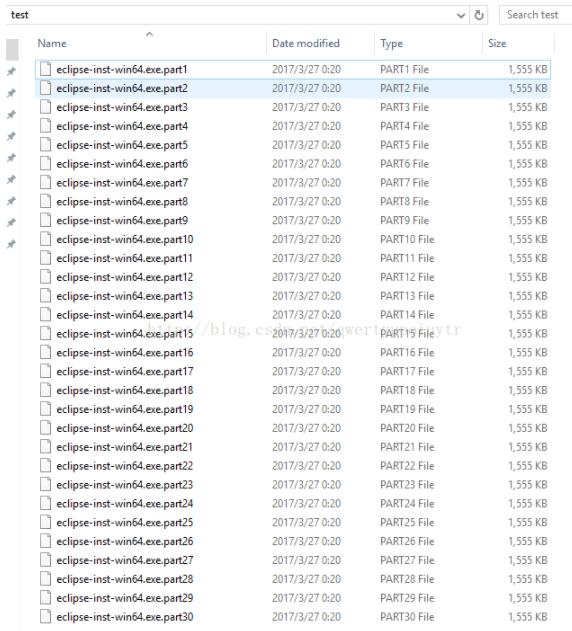
重组文件:
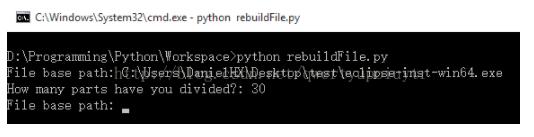
重组后文件:

以上这篇python文件拆分与重组实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









