






本文讲述GBDT算法应用层面的大杀器:XGBOOST算法。作为GBDT的最广泛的应用算法之一,XGBOOST是建立在GBDT的梯度提升树思路上的,但它在GBDT的基础上又进行了改进,从损失函数到计算方式,都做了些改变。
一、XGBOOST的特征和主要优点
- XGBOOST可以处理稀疏性数据
- 通过分布式加权直方图的方式去近似学习树
- 提供了基于缓存的加速模式、数据压缩、分片功能
二、XGBOOST的GB框架
1. XGBOOST的正则化目标
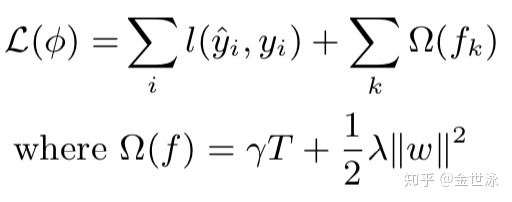
由此可以看到,xgboost的标准正则化目标项:损失函数+正则项,其中损失函数L衡量预测值与真实值的差异,
XGBOOST的目标函数是可以自定义设计的,常用的话分类用对数损失函数,回归用平方损失函数。
2. 计算中近似求解目标项
在boosting的思想下,应该通过t次迭代更新
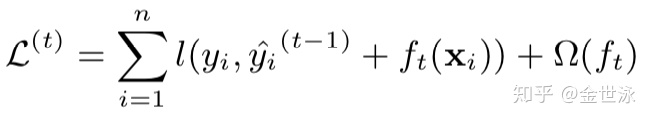
将损失项进行二阶泰勒展开:
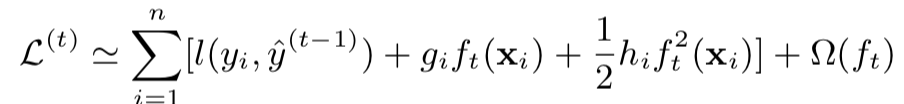
去除常数后我们可以得到第t步的目标函数:
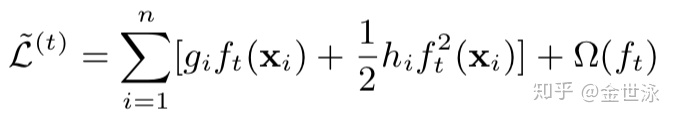
将所有样本点根据叶子结点拆分成样本集
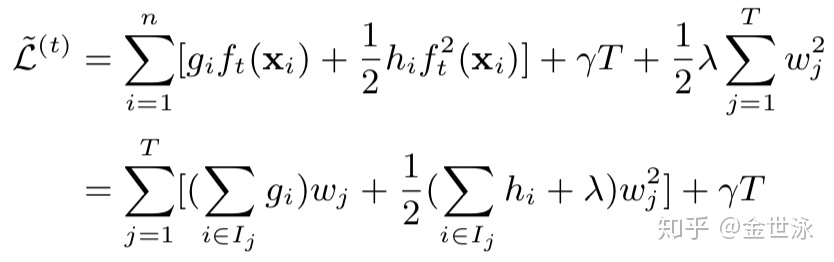
假定树的结构已固定,在此目标函数仅与叶子结点权重
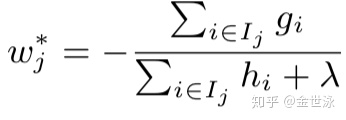
因而求得第t棵树的目标函数,可用来最为第t棵树的得分函数来衡量树的结构q的质量,这个指标类似决策树中的纯度,可用来描述特征选取的优劣:
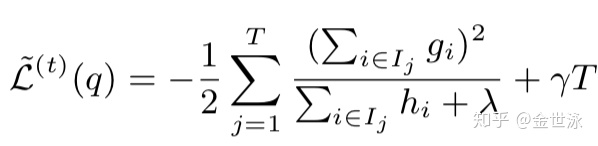
在实际计算中,遍历所有树结构计算量太大,在此使用贪心算法在初始叶子结点迭代添加分支,损失函数改变成如下:
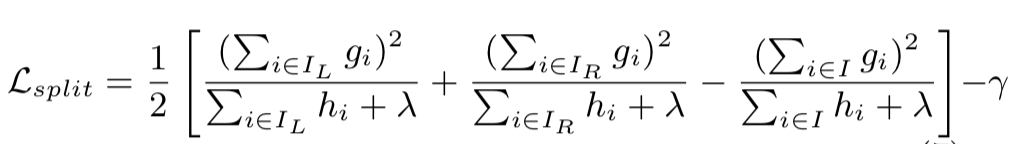
3. XGBOOST系统防止过拟合
- 如上所说,在损失函数上增加正则项;
- 在每一步树的boosting中添加shrinkage,即权重:类似RF中的学习率,该方法减少了每棵单独树的影响,也为将形成的树预留了空间(可供修改的空间);
- 特征列抽样:类似RF中的方法找到近似最优的分割点,还有一个好处是加速并行化;
三、分割算法
1. 在树的生成中,叶子结点的分裂的关键问题是找到合适的分割。在此有来年各种功能方法,一是精确的贪心算法(常用于单机计算),二是近似算法(常用于分布式计算)
2. 基础精确的贪心算法
通过列举所有特征的可能划分找到最优划分解来生成树,该方法需要排序以形成连续的特征,之后计算每个可能的梯度统计值;
该算法时间复杂度为:
其中n * m表示遍历每个样本的每个特征,mlog(m)表示特征排序的时间复杂度。

3. 近似算法
精确算法需要一次计算所有特征的二阶导,同时需要排序来获取当前供选特征,相当消耗算力;同时将所有样本遍历也相当消耗内存,因而出现了近似算法。
在精确算法中,我们需要尽可能逐一遍历样本点以找到最好的划分界限,这相当费时费力。在近似算法中,我们通过区间划分的方式将样本集划分为设定多个buckets所构成的样本子集,(即特征的离散化)只在buckets的边界点中筛选最好的分裂结点,这大大简化了计算。

3.1 特征离散化方法分为两种:全局选择和局部选择;
- 全局选择:在建立第k棵树的时候利用样本的二阶梯度对样本进行离散化,每一维的特征都建立buckets。在建树的过程中,我们就重复利用这些buckets去做。
- 局部选择:每次进行分支时,我们都重新计算每个样本的二阶梯度并重新构建buckets,再进行分支判断。
- 局部选择的编码复杂度更高,但在实验当中效果极其的好,甚至与Exact Greedy Algorithm一样。
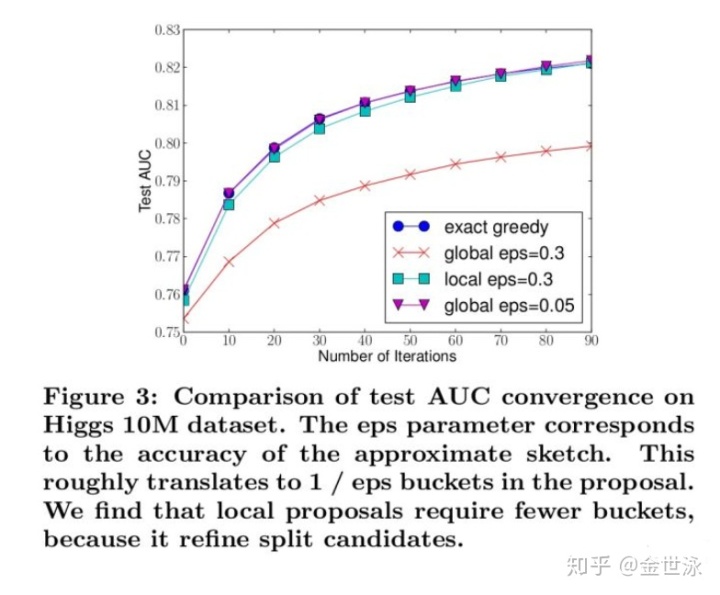
3.2 连续型特征离散化
- 特征离散化就存在两个问题:特征排序和间隔划分;
- 对于特征排序我们使用如下公式:rank的计算是对某一个特征上,样本特征值小于z的二阶梯度除以所有的二阶梯度总和。其实就是对样本的二阶梯度进行累加求和,那二阶梯度在这里就是代表样本在特征k上的权值。
对于数据集
该方法被称为:分布式加权直方图(Weighted Quantile Sketch)
- 所谓设定间隔划分就是找到具体的buckets边缘:我们就对样本重新组合成为
分裂点,
是指每个buckets的边界点。
关于二阶导数可作为权重的理论支持如下:
对于第t步的目标函数:
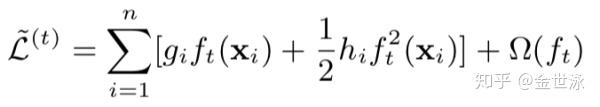
提取hi可得:
由此可以看出二阶导数正好是样本均方误差的权重
6. 稀疏自适应分割策略
当样本的第i个特征值缺失时,无法利用该特征进行划分时,XGBoost的想法是将该样本分别划分到左结点和右结点,然后计算其增益,哪个大就划分到哪边。

7. 并行化处理
XGBOOST算法属于boosting算法,故对于树是没办法进行并行计算的,XGBOOST的并行是在特征粒度上的。主要并行作用在两个方面,第一个时特征的排序(),第二个是结点分裂时增益的计算(用分布式加权直方图确定buckets的分割点)。
- 对于决策树算法来说,算力消耗的大头是将数据按照特征的顺序进行排序。为了降低排序成本,xgboost将数据存储在内存单元中,称之为块(block)。每个块中的数据以压缩列(CSC)格式存储,每列按相应的特征值排序。此输入数据布局仅需要在训练之前计算一次,并且可以在以后的迭代中重复使用,大大的减少了计算量。这个block结构使得并行变成了可能。在进行结点的分裂时,需要计算每个特征的增益,最终选择增益最大的那个特征去做分裂,那么各个特征的增益计算就可以多进程进行。
- 树结点进行分裂时,需要计算每个特征对每个分割点的增益,分布式加权直方图使得特征的增益可以并行计算。
四、使用XGBOOST对特征重要性进行排序
https://blog.csdn.net/waitingzby/article/details/81610495blog.csdn.net五、几个链接
- 大佬总结帖:
- 调参:
















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









