






 XGBoost是一种强大的机器学习算法,其在正则化、工程优化和与GBDT的比较上有独特之处。本文深入探讨了XGBoost的目标函数、基于树的正则化、节点分裂准则,特别是近似算法和加权分位数策略。此外,还介绍了列采样、学习率和稀疏感知等优化手段,以及并行列块设计和核外块计算等工程优化方法。
XGBoost是一种强大的机器学习算法,其在正则化、工程优化和与GBDT的比较上有独特之处。本文深入探讨了XGBoost的目标函数、基于树的正则化、节点分裂准则,特别是近似算法和加权分位数策略。此外,还介绍了列采样、学习率和稀疏感知等优化手段,以及并行列块设计和核外块计算等工程优化方法。

XGBoost(eXtreme Gradient Boosting)是基于Boosting框架的一个算法工具包(包括工程实现),在并行计算效率、缺失值处理、预测性能上都非常强大。本文参考其原始论文[1],将主要从算法原理和工程实现方面介绍这一算法。
框架如下(终于发现了思维导图的用处...)
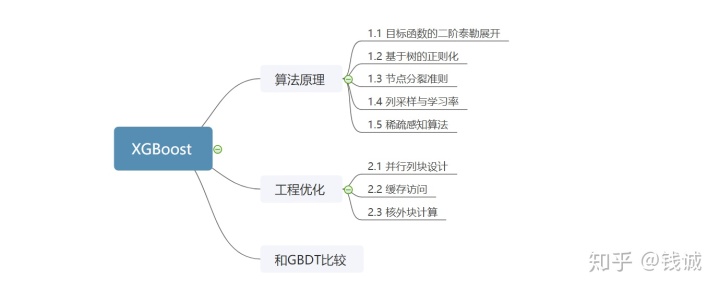
1.算法原理
1.1 目标函数的二阶泰勒展开
和GBDT一样,XGBoost是一个加法模型,在每一步迭代中只优化当前步中的子模型。 在第
目标函数为经验风险+结构风险(正则项):
其中,正则项
泰勒公式是将一个在
式(1)中,将
前
其中
这里的
1.2 基于树的正则化
XGBoost支持的基分类器包括决策树和线性模型,我们这里只讨论更常见的基于树的情况。为防止过拟合,XGBoost设置了基于树的复杂度作为正则项:
由(2)(3),目标函数如下:
接下来通过一个数学处理,可以使得正则项和经验风险项合并到一起。经验风险项是在样本层面上求和,我们将其转换为叶节点层面上的求和。
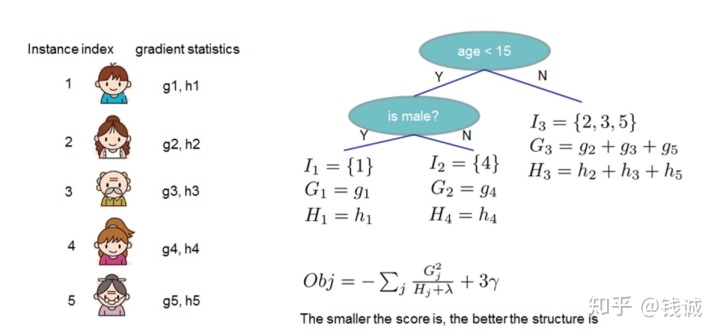
定义节点
进一步简化表达,令
此时,若一棵树的结构已经确定,则各个节点内的样本
按此规则输出回归值后,目标函数值也就是树的评分如下,越小代表树的结构越好。观察下式,树的评分也可以理解成所有叶节点的评分之和:
1.3 节点分裂准则
XGBoost的子模型树和决策树模型一样,要依赖节点递归分裂的贪心准则来实现树的生成。除此外,XGBoost还支持近似算法,解决数据量过大超过内存、或有并行计算需求的情况。
1.3.1 贪心准则
基本思路和CART一样,对特征值排序后遍历划分点,将其中最优的分裂收益作为该特征的分裂收益,选取具有最优分裂收益的特征作为当前节点的划分特征,按其最优划分点进行二叉划分,得到左右子树。
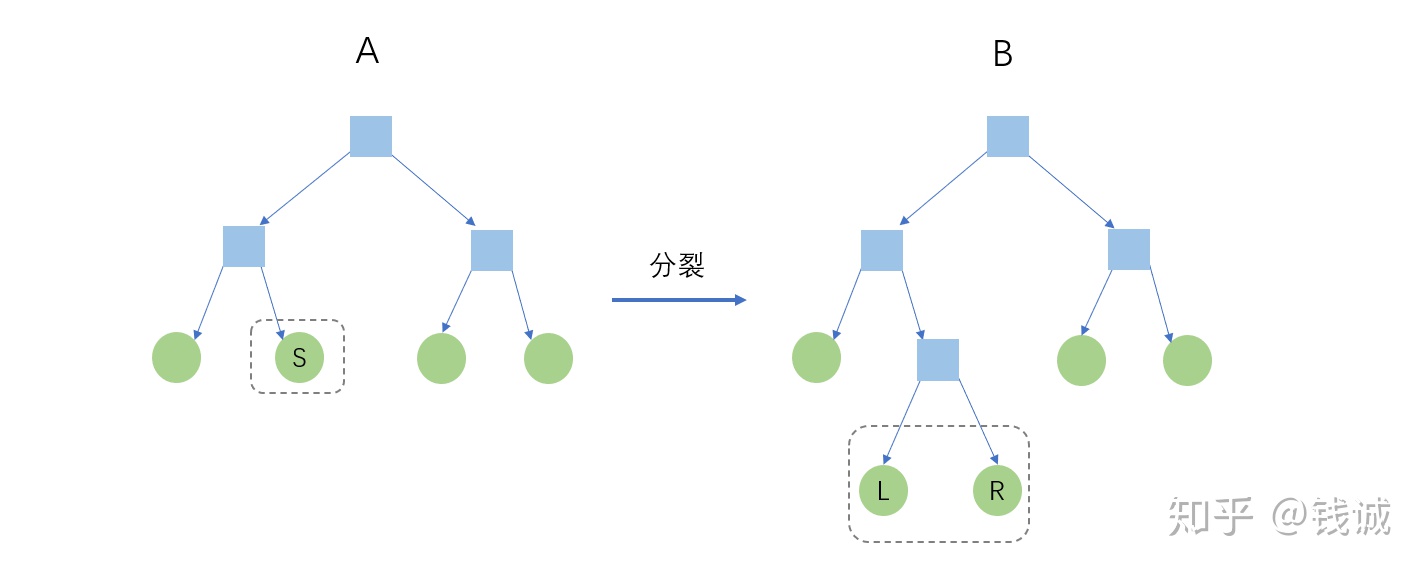
上图是一次节点分裂过程,很自然地,分裂收益是树A的评分减去树B的评分。由(4),虚线框外的叶节点,即非分裂节点的评分均被抵消,只留下分裂后的LR节点和分裂前的S节点进行比较,因此分裂收益的表达式为:
1.3.2 近似算法
XGBoost还提供了上述贪心准则的近似版本,简言之,将特征分位数作为划分候选点。 这样将划分候选点集合由全样本间的遍历缩减到了几个分位数之间的遍历。
具体而言,特征分位数的选取有global和local两种可选策略:global在全体样本上的特征值中选取,在根节点分裂之前进行一次即可;local则是在待分裂节点包含的样本特征值上选取,每个节点分裂前都要进行。通常,global由于只能划分一次,其划分粒度需要更细。
在XGB原始论文中,作者在Higgs Boson数据集上比较了精确贪心准则、global近似和local近似三类配置的测试集AUC,用eps代表取分位点的粒度,如eps=0.25代表将数据集划分为1/0.25=4个buckets,发现global(eps=0.05)和local(eps=0.3)均能达到和精确贪心准则几乎相同的性能。
这三类配置在XGBoost包均有支持。
1.3.3 加权分位数
查看(2)式表示的目标函数,令偏导为0易得
因此,在近似算法取分位数时,实际上XGBoost会取以二阶导
1.4 列采样和学习率
XGBoost还引入了两项特性:列采样和学习率。
列采样,即随机森林中的做法,每次节点分裂的待选特征集合不是剩下的全部特征,而是剩下特征的一个子集。是为了更好地对抗过拟合(我不是很清楚GBDT中列采样降低过拟合的理论依据。原文这里提到的动机是某GBDT的软件用户反馈列采样比行采样更能对抗过拟合),还能减少计算开销。
学习率,或者叫步长、shrinkage,是在每个子模型前(即在每个叶节点的回归值上)乘上该系数,削弱每颗树的影响,使得迭代更稳定。可以类比梯度下降中的学习率。XGBoost默认设定为0.3。
1.5 稀疏感知
缺失值应对策略是算法需要考虑的。特征稀疏问题也同样需要考虑,如部分特征中出现大量的0或干脆是one-hot encoding这种情况。XGBoost用稀疏感知策略来同时处理这两个问题:概括地说,将缺失值和稀疏0值等同视作缺失值,再将这些缺失值“绑定”在一起,分裂节点的遍历会跳过缺失值的整体。这样大大提高了运算效率。
0值在XGB中被处理为数值意义上的0还是NA,不同平台上的默认设置不同, 可参考本处。总的来说需要结合具体平台的设置,预处理区分开作为数值的0(不应该被处理为NA)和作为稀疏值的0(应该被处理为NA)。
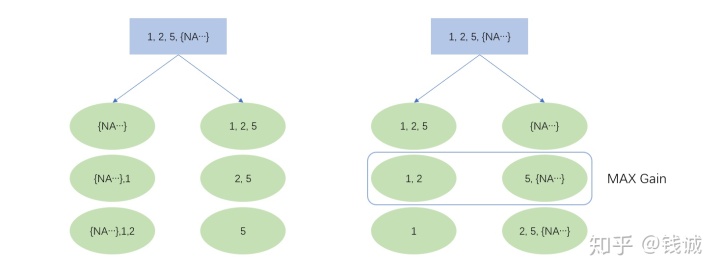
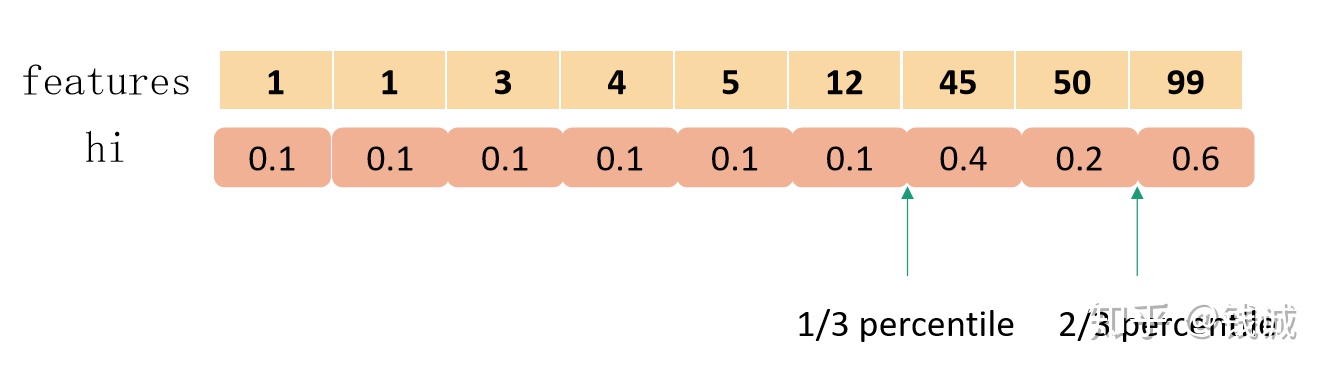
分裂节点依然通过遍历得到,NA的方向有两种情况,在此基础上对非缺失值进行切分遍历。或者可以理解NA被分到一个固定方向,非缺失值在升序和降序两种情况下进行切分遍历。
如上图所示,若某个特征值取值为1,2,5和大量的NA,XGBoost会遍历以上6种情况(3个非缺失值的切分点 × 缺失值的两个方向),最大的分裂收益就是本特征上的分裂收益,同时,NA将被分到右节点。
2.工程优化
2.1 并行列块设计
XGBoost将每一列特征提前进行排序,以块(Block)的形式储存在缓存中,并以索引将特征值和梯度统计量
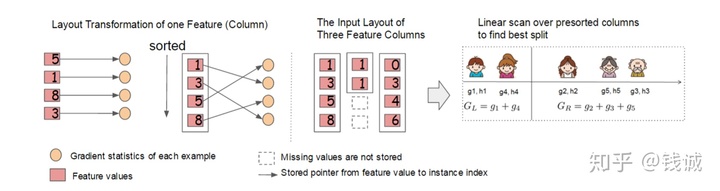
2.2 缓存访问
特征值排序后通过索引来取梯度
2.3 核外块计算
数据量过大时,不能同时全部载入内存。XGBoost将数据分为多个blocks并储存在硬盘中,使用一个独立的线程专门从磁盘中读取数据到内存中,实现计算和读取数据的同时进行。为了进一步提高磁盘读取数据性能,XGBoost还使用了两种方法:一是通过压缩block,用解压缩的开销换取磁盘读取的开销;二是将block分散储存在多个磁盘中,有助于提高磁盘吞吐量。
3.和GBDT的比较
- 性质:GBDT是机器学习算法,XGBoost除了算法内容还包括一些工程实现方面的优化。
- 基于二阶导:GBDT使用的是损失函数一阶导数,相当于函数空间中的梯度下降;而XGBoost还使用了损失函数二阶导数,相当于函数空间中的牛顿法。[2]
- 正则化:XGBoost显式地加入了正则项来控制模型的复杂度,能有效防止过拟合。
- 列采样:XGBoost采用了随机森林中的做法,每次节点分裂前进行列随机采样。
- 缺失值处理:XGBoost运用稀疏感知策略处理缺失值,而GBDT没有设计缺失策略。
- 并行高效:XGBoost的列块设计能有效支持并行运算,提高效率。
参考资料
[1] XGBoost: A Scalable Tree Boosting System: https://arxiv.org/pdf/1603.02754.pdf
[2] wepon GBDT PPT: http://wepon.me/files/gbdt.pdf
[3] 阿泽:【机器学习】决策树(下)——XGBoost、LightGBM(非常详细)

















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









