





1.引言
a、什么是混响
混响主要用于唱卡拉OK,增加话筒声音的延时,产生适量的回声,使唱歌的声音更圆润更优美,歌声不那么“干”。
什么是回声
回声:在一个方向的延迟反射
混响:在多个方向的多次延迟反射
b、混响算法的发展史
硬件混响设备
一般原理就是现场采集ir(impulse response) 如练声房,录音棚,音乐厅等

软件混响
发展到后期,因为数字信号处理的发展,和可编程门阵列芯片产生,就习惯将提前采集好的ir通过算法做卷积运算。
算法混响就此产生,后期又通过很多人员的努力产生了房间声学的模拟算法。
所以在软件混响里面,基本有两种一种是ir,另一种房间声学的模拟算法。
我们能看到的像freeverb3这两种都有,而sox等其他一般只看到后面一种。目前能看到的如下:
回声类:echo ,echos
ir类:model1 model2 model3
schroeder类: 简易schroeder,复杂schroeder,schroeder优化版moorer
2、混响算法及推导
a、观察房间声音的模型
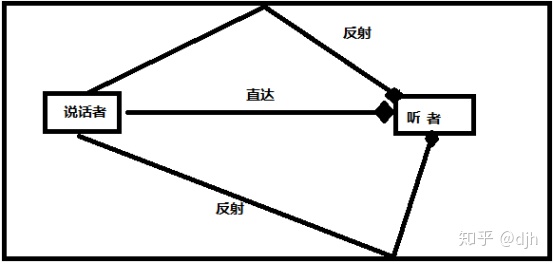
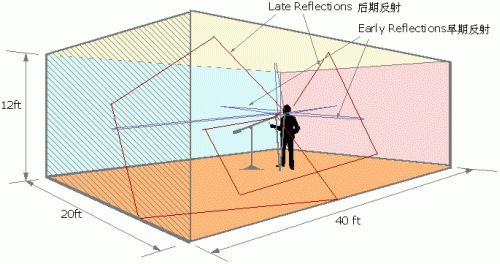
我们看下上面的图,假设我们在一个房间里,说话者和听者所在的空间声音应该是这个样子的如图。听者听到的包括直达的信号外还有很多反射声音。这里我们关注两点一个是房间的大小,另外一个是反射强度。
当如果这个房间非常大,那么基本上听不到反射。
同样的道理,一个房子的材质会影响反射强度,如金属和木质两种不同材质做的房子,反射效果显然是不一样的。
b、建立初步数学模型。
假设说话者说出的信号是x[n]
听者某时刻接收到的信号是y[n],那么y[n]包含那些内容呢?
y[n] 应该是 x[n] + 反射1 + 反射2 .......
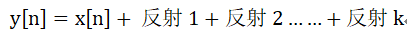
反射怎么表示,它应该是x[n] 的延时我们假设延时m ,难么反射1 应该是 x[n -m] ,但是我们还应该考虑反射时的衰减,就是上面所说的房子的反射效果,假设是a,则反射1 应该表示成 x[n -m]*a;
所以,y[n] = x[n] + a*x[n -m] + a^2*x[n - 2m] + a^3*x[n - 3m]......
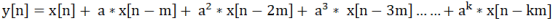
求和我们简化下,利用差分或者z变化得到差分方程:
y[n] = ay[n - m] + x[n];
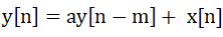
这是个梳妆滤波器
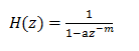
它的频谱特性
由此我们就可以根据这个公式写出自己的算法。按道理这样应该就可以了,
但是这个算法存在,回声密度比较低的问题会出现金属质感,听起来不舒服,不自然。
c、对初步数学模型的优化-----全通
怎么办呢?怎么去解决这种梳状滤波器带来的频谱不平坦,和回声密度不够,一些做信号处理的专家立马想到了,使用全通系统去改善它。
因为我们知道全通系统,有很好的群延时,所以可以增加回声的密度。全通表达式如下:
y[n] = -gx[n] + x[n-m] +gy[n-m];
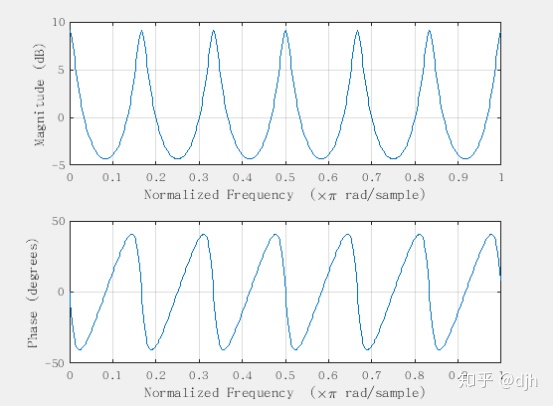
它的频谱特性
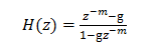
它的幅度谱 和 相位谱
他的零极点都是单位元对称的。
频谱平坦
相位延迟
d、对初步数学模型的优化-----Schroeder混合模型的提出
这样增加了全通以后好多,但是还是不够。这个时候有个叫Schroeder的人提出了一个很吊的方案。称之为Schroeder混响模型。

这种模型得到很好的工业生产。
e、对初步数学模型的再优化-----Moorer对Schroeder的优化
但是总有更吊的人在后面。
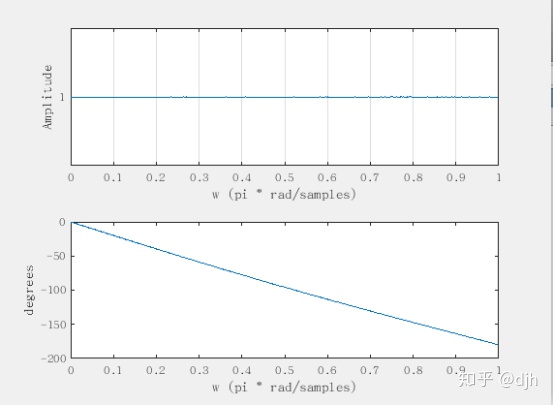
Moorer对Schroeder的混响提出三点点改善意见,
第一:需要考虑信号在空间传播高频衰减因素,加入低通滤波器使高频衰减。
第二:后面的全通应该嵌套使用,这样会有更好的群延时,
第三:可以增加前级反馈,形成早反射,增加混响效果。
下面是框图。下一章我们将会对这个原理一步步对应分析算法的实现。
从梳状滤波器一直到最终的模型,进过很多人的努力。还是很不容易。
现在各个手机或者其他混响设备上用基本都是这种模型,当然有些软件它自己还会增加一些自己的eq,
我们最终看下界面结构,
如下:
app软件:
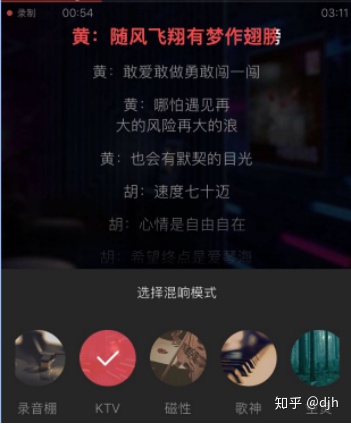
各大软件如唱吧一般,不会直接给那么多参数给你调。考虑用户的体验,一般会给出一些选项。什么大厅,礼堂,演唱会等等。
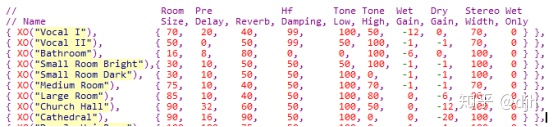
声音或者Audiacity展示。
3、算法的实现
了解了上面的原理后,算法的实现就变得简单易懂了。
当然我们崇尚拿来主义sox
混响算法,在诸多开源中都有实现,例如sox,freeverb,Tonic等等开源框架,都有。我们今天拿sox的进行分析。
下载sox后直接在/src/reverb.c就可以看到完整的混响算法。我们根据上面讲的一部部分析。
这个c文件和h文件很长,我们抽出需要的来看。
梳状滤波
static comb_process 函数就是梳状滤波器的结构,其实
*p->ptr = *input + p->store * *feedback;
这个表达是就是:y[n] = ay[n - m] + x[n]; 而上面的一局话是一个标准的低通滤波器。
这个低通滤波器就moorer提出的需要对高频部分进行衰减。
p->store = output + (p->store - output) * *hf_damping;
y[n] -gy[n] = (1-g)x[n]
并且如下在主函数中进行了 7 次的do while 并联。
size_t 全通滤波
static allpass_process 就是上章描述的全通,而*p->ptr = *input + output * .5 和 output - *input;这句话并非标准的全通模型,其H(z)如下
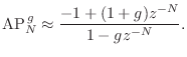
差分方程如下
y[n] = -x[n] + (1+g)x[n-m] + gy[n - m]
刚好对应这两句代码,另外allpass_process的input是指针形式它传进来的是后面自己return的内容,这样就形成了一个的输出给到下一个输入,形成moorer提出的嵌套。
代码如下
i = array_length(allpass_lengths) - 1; do out = allpass_process(p->allpass + i, &out); while (i--);
早反射
根据moorer的说法,早反射对声音效果是很重要的,在sox中它使用fifo队列来组织数据流,当没有满足早反射时间时fifo填充的是0.代码如下
static 如上代码,将需要延迟的参数pre_delay_ms (单位ms),转换成采样个数,在给到fifo_write进行写0操作。
有时间看看我们自己简化了以后的。















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









