





注:本系列专栏需要有简单的python3 语言基础爬虫的相关作用在此就不再说明,相信能够点进该系列文章的读者都已经了解了爬虫是什么,并且能够做什么。由于是发布在互联网的文章,所以系列文章都不以书籍的方式从头到尾的叙述作用及其一些简介。文章将快速的进入爬虫的开发讲解。
开始
爬虫一般的实现流程如下:

首先向一个 Url 地址发送请求,随后远端服务器将会返回整个网页。常规情况下,当我们使用浏览器访问网站也是这么一个流程;用户在浏览器输入一个地址,浏览器将会发送一个服务器请求,服务器返回请求的内容,随后浏览器解析内容。其次,发送请求后,将会得到整个网页的内容。最后,通过我们的需求去解析整个网页,通过正则或其它方式获取需要的数据。
发送请求 获取网页
一般情况下发送请求和获取网页是相互实现的,通过请求后就会得到网页数据。我们使用requests 库进行web的请求。代码编写如下:
import requestsurl="https://www.baidu.com/"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}html=requests.get(url,headers=headers)print(html.text)- import requests:引入 requests 模块
- url="https://www.baidu.com/":设置要请求的url值,这里为百度
- headers:为了更好的伪造自己是浏览器访问的,需要加一个头,让自己看起来是通过浏览器访问
- html=requests.get(url,headers=headers):requests使用get方法,请求网站为url设置的值,头部为headers
- print(html.text):显示返回的值html中的text文本,text文本则为网页的源代码
解析网页
接下来需要使用一个库 BeautifulSoup库,BeautifulSoup 是灵活方便的网页解析库,使用bs4(BeautifulSoup )可以快速的使我们获取网页中的一般信息。例如我们需要获取刚刚得到网页源码中的title标题,首先引入 bs库:
from bs4 import BeautifulSoup随后使用 beautifulsoup 进行解析,html.parser 代表html的解析器,可以解析html代码;其中 html.text 为网页源码为html,如下:
val = BeautifulSoup(html.text, 'html.parser')解析完成后,如果想获取标题值,则直接使用 .title 进行获取:
print(val.title)运行结果如下:

完整代码如下:
import requestsfrom bs4 import BeautifulSoupurl="https://www.baidu.com/"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}html=requests.get(url,headers=headers)val = BeautifulSoup(html.text, 'html.parser')print(val.title)如果想进行抓取文件的保存,可以如下方式编写代码:
f = open(r'D:html.html',mode='w')f.write(html.text)f.close() 以上代码将网页的源代码保存至D盘根目录下,完整代码如下:
import requestsfrom bs4 import BeautifulSoupurl="https://www.baidu.com/"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}html=requests.get(url,headers=headers)val = BeautifulSoup(html.text, 'html.parser')print(val.title)f = open(r'D:html.html',mode='w')f.write(html.text)f.close() 以上代码可能会出现编码不一致,出现“乱码”的情况,可以通过以下方式解决:
f = open(r'D:html.html',mode='w',encoding="utf-8")在open函数中,添加编码为 utf-8 即可。最终打开保存的文件如下:
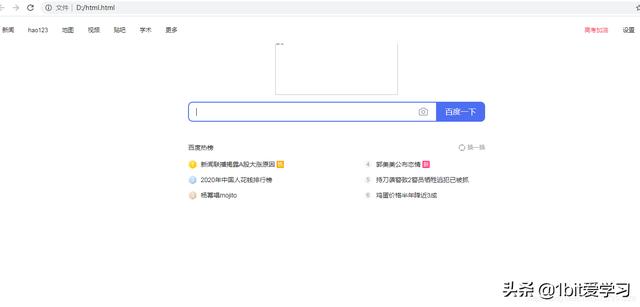
由于有些资源是动态加载,获取的链接有时效性,所以并没有显示。
这样最简单的一个爬虫就解决了,下一篇将继续深入了解爬虫。














 5221
5221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









