





一分钟读完
本文对开源轻量级的动态交通分配工具DTALite进行了介绍。DTALite是由Arizona State University的Xuesong Zhou老师基于C++开发的一款主打快速动态交通分配的工具,并结合NeXTA开发了一定的可视化功能。本文将结合近期项目中的实际使用体验,对DTALite中主要的ODME(OD逆推)、参数标定、交通分配、场景设置等操作进行介绍。
关于宏观交通仿真、动态交通分配与DTALite
目前市面上成熟的宏观交通仿真其实并不少,最著名的如TransCAD, VISUM, CUBE,都是宏观交通仿真的标杆商业软件,也几乎常年占据了交通行业宏观仿真的主要市场。这些软件我多少都有接触过,其优点就是上手容易,操作简单,结果系统,缺点就是贵,慢,且由于都是商业软件,基本采用的都是纯组装形式,灵活性差。TransCAD相关操作可参考我之前的文章:
Song:TransCAD与四阶段法——如何做一个完整的宏观交通仿真zhuanlan.zhihu.com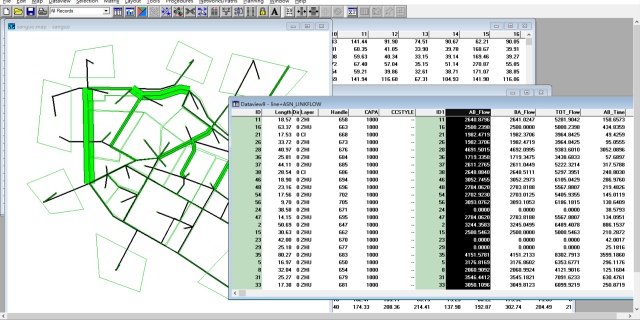
动态交通分配(DTA: Dynamic traffic assignment)是基于静态交通分配(STA)在考虑效用函数时变特性后的变体。在交通分配中,用户皆被假设为绝对理性、全知(信息透明)且贪婪的,因此他们总是选择最利于自身的路径完成出行,即,出行费用最低(费用可以是travel time、Toll等等)。STA认为,出行费用在整个分配过程中是固定的,用户在出行起始时刻便确定了路线并基于该路线完成出行。但其中的问题便是,用户彼此之间的选择是会影响到出行费用的。最常用的例子就是A-B间有两条路径,一条距离长一条距离短,用户开始都会选择距离短的,但随着短的路线的流量增大,出行时间也会随着增大,这样之后的用户则会转移到长的路线上去。而DTA则是考虑到了效用函数的时变特征,通过动态的、时间上逐步的交通分配,来捕捉用户对交通状态改变的响应。
DTALite的目的是快速完成动态交通分配,它的主要优点在于免费、轻便、快速、开源,只需要将开发好的exe文件放入准备好input files的文件夹中运行即可得到分配结果。它同时打通了宏观与微观的壁垒,可以直接输出每一个agent具体的出行轨迹。但它本身并非一款完整的四阶段仿真软件,而着重于交通分配的实现,因此在操作和数据准备上依然依赖于外部的支撑(如原始OD生成、模式划分、型心连杆的产生等)。目前DTALite已经有相对成熟的版本与使用说明可直接下载,相关介绍可以参考Xuesong Zhou老师的GITHUB:
xzhou99/dtalite_software_releasegithub.com
就交通仿真从业人员而言,宏观交通仿真与微观相比,最大的难度其实不在工具,而在数据。OD(时序动态、模式区分)、路网(联通合理、转向分明、属性如车道、通行能力完备)、流量(或速度),是上游数据端最重要的三类数据源。OD决定出行量是否合理,路网决定分配是否可靠,而流量则决定参数标定的准确性。而目前这三类数据,其实都是非常难以准确获取的,尤其对于动辄一个片区、一个城市的宏观交通仿真而言。这也导致了仿真往往很难做到真正的真实,且大量时间都花在了数据预处理上。当然,这是后话,也不是本文的重点。
数据准备
与所有我们所熟悉的宏观仿真软件不同,DTALite的文件处理与传输方式是通过csv直接进行操作的。DTALite也没有一个完整的操作界面(NeXTA在一定程度是),直接运行DTALite.exe就可以直接触发分配。所以要上手DTALite,必须要捋清其文件系统。DTALite的input file主要有以下几类:
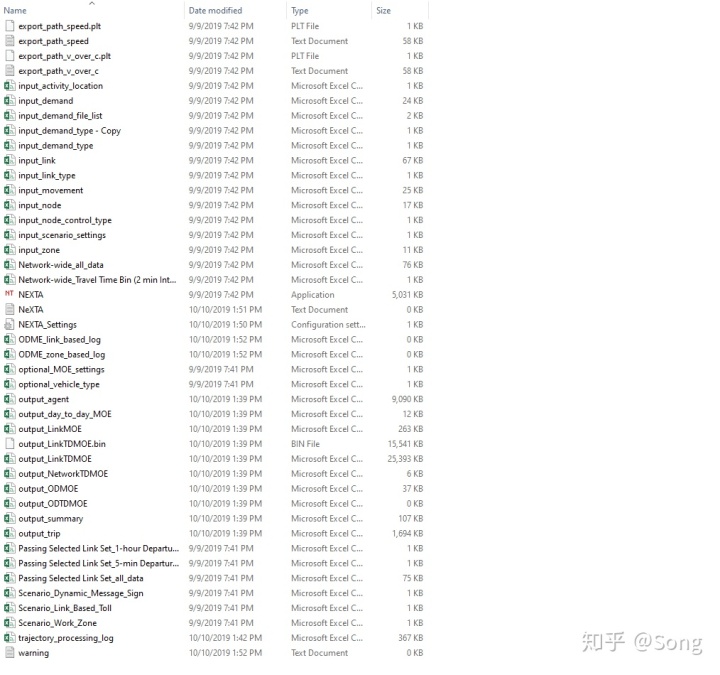
路网方面:
- input_link:记录了关于路网的所有路段信息(型心连杆(zone connector)也在其中)。
- link_type:记录了路段的等级类型。
- input_movement:记录了路段的方向与转向。
- input_node:记录了所有的路段节点信息。
- input_node_control_type:记录了所有的节点控制类型。
小区方面:
- input_activity_location:记录了所有的节点与TAZ(交通小区)间的映射关系。
- input_zone:记录了所有的TAZ(交通小区)信息。
交通需求方面:
- input_demand:记录了初始OD(可以存在多个OD files)
- input_agent:记录了agent(与OD二选一,可以同时接受OD的输入或agent的输出)
- input_demand_file_list:指定输入的demand的文件格式与名称:如果是OD,则为input_demand.csv+column,如果是agent,则为input_agent.csv+agent_csv
仿真场景方面:
- input_scenario_settings:记录了相关的仿真设置,如迭代次数、交通流模型类型(一般选3:Newell’s Kinematic Wave Model)、以及ODME的相关设置
- Scenario_Link_Based_Toll:记录了收费路段的相关信息
- Scenario_Dynamic_Message_Sign:记录了动态信息告示的相关信息
- Scenario_Work_Zone:记录了施工区、事故路段的相关信息
- Sensor_count:记录了检测器的流量(速度)信息,用于ODME
类似的,其输出文件也全部以csv格式直接输出到对应的目录内,主要包括了不同的时空、模式等统计口径的MOE(评价指标),ODME的相关结果,以及agent-level的出行路径。在此就不做总结了。
总结而言,在开始跑DTALite仿真之前,你需要准备好带有型心连杆的路网、划分好的交通小区、小区与路网节点的映射关系、各个交叉口的控制类型、按时间与出行模式划分好的原始OD文件、研究区域内路段上检测器对应的真实流量、仿真场景的相关属性。完成这些文件准备后,点击DTALite.exe,即可开始进行流量分配了。
ODME
在准备好上述数据后(当然准备好上述数据本身就比较困难),第一步要做的,就是ODME(Origin-Destination Matrix Estimation),中文也叫OD逆推。当然DTALite中的OD逆推并非完全借助流量把OD推出来,而是结合流量数据,对给定的raw OD table进行调整。首先,我们准备好不同模式、不同时段的OD信息,分别保存为多个CSV文件,然后,在input_demand_file_list中进行如下设置:
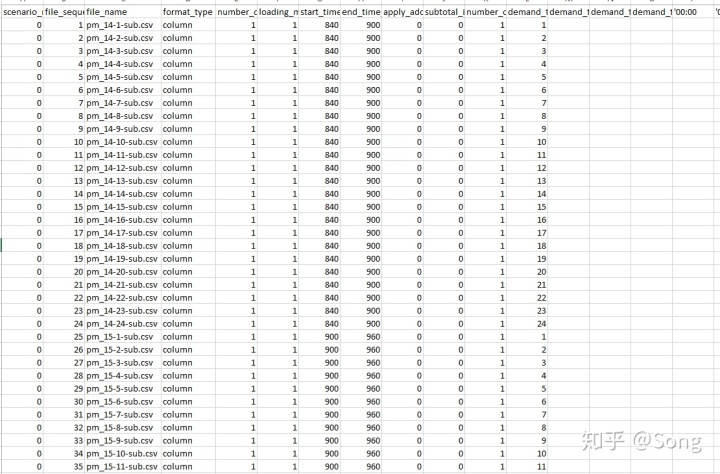
- file_name设置为对应的OD表的CSV文件名
- format_type设为为column
- start_time_in_min和end_time_in_min设为对应的OD起始终止时间
- demand_type_1设置为对应的OD模式类型
同时打开input_scenario_settings,进行如下设置:
- number_of_assignment_days设置为迭代次数,比如10次。
- traffic_assignment_method设置为3(3表示ODME,否则设置为1)。
- ODME_start_iteration和ODME_end_iteration设置为开始ODME和介绍的迭代次,比如3和10,则表示第三次迭代时开始ODME,到第10次迭代时结束。
- ODME_max_percentage_deviation_wrt_hist_demand设置与原始OD的最大调整范围,如果你对原始OD不信任而对检测器流量更信任,不妨将这个值设置大一些。
- calibration_data_start_time_in_min和calibration_data_end_time_in_min设置为与检测器的流量对应的时间段相同。
然后点击DTALite.exe开始运行即可。完毕后,打开output_summary可以查看ODME每次迭代的仿真结果,可见ODME从第3次开始触发,且ODME: % link count error持续下降,

同时,ODME_final_result中记录了每个TAZ对应的OD的调整比率。但这个只有TAZ-level而没有具体的OD-level的调整比例,用处不大。
另一个需要查看的就是debug_validation_results文件,里面记录了每个检测器的观测值与DTALite对应的仿真值间的差异。
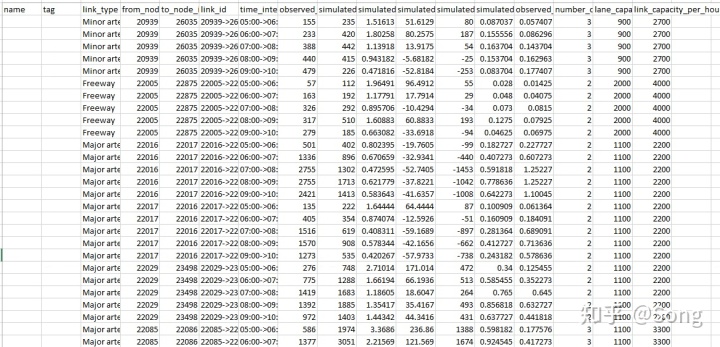
通过这个文件我们可以快速找出哪些检测器的仿真精度差,并对应进行调整。检测器的仿真精度差,往往很有可能是检测器本身的数据记录有问题,因此比较简单的解决方法是在ODME的基础上再加一层loop,通过不断调整仿真精度差的检测器,来使ODME的精度提升:
import pandas as pd
import os
import datetime
import numpy as np
import subprocess
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, mean_absolute_error
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 14})
# Iteration to calibrate the DTA
ALL_WMSE = []
ALL_debug_validation_results = pd.DataFrame()
for itera in range(0, 10):
# Read the results
debug_validation_results = pd.read_csv(r'debug_validation_results.csv')
debug_validation_results_cp = debug_validation_results.copy()
debug_validation_results_cp['Ite_Times'] = itera
ALL_debug_validation_results = ALL_debug_validation_results.append(debug_validation_results_cp)
# plt.plot(debug_validation_results['observed_link_count'], debug_validation_results['simulated_link_count'], 'o',
# alpha=0.1)
# Calculate the WMSE
wmse = np.sqrt(
sum((debug_validation_results['observed_link_count'] - debug_validation_results['simulated_link_count']) ** 2) /
sum(debug_validation_results['observed_link_count'] ** 2))
rmse = np.sqrt(mean_squared_error(debug_validation_results['observed_link_count'],
debug_validation_results['simulated_link_count']))
# print('Test RMSE: %.3f' % rmse)
mae = mean_absolute_error(debug_validation_results['observed_link_count'],
debug_validation_results['simulated_link_count'])
# print('Test MAE: %.3f' % mae)
mape = np.mean(np.abs(
(debug_validation_results['observed_link_count'] - debug_validation_results['simulated_link_count']) /
debug_validation_results['observed_link_count']))
# print('Test MAPE: %.3f' % mape)
ALL_WMSE.append([itera, wmse, rmse, mae, mape])
print(ALL_WMSE)
# Read the Sensors
sensor_count = pd.read_csv(r'sensor_count.csv')
need_columns = list(sensor_count.columns)
sensor_count['link_id'] = sensor_count['from_node_id'].astype(str) + '->' + sensor_count['to_node_id'].astype(str)
# Drop the worst sensors
debug_validation_results = debug_validation_results.sort_values(by='simulated_over_observed_ratio').reset_index(
drop=True)
tem_tail = debug_validation_results.tail(5)
tem_head = debug_validation_results.head(5)
debug_validation_results = debug_validation_results.sort_values(by='simulated_vs_observed_count_error').reset_index(
drop=True)
tem_tail1 = debug_validation_results.tail(5)
tem_head1 = debug_validation_results.head(5).reset_index(drop=True)
Broken_Sensor = set(
list(tem_tail['link_id']) + list(tem_head['link_id']) + list(tem_tail1['link_id']) + list(tem_head1['link_id']))
sensor_count = sensor_count[~sensor_count['link_id'].isin(Broken_Sensor)].reset_index(drop=True)
print('Drop # of Sensor: ' + str(len(Broken_Sensor)))
sensor_count[need_columns].to_csv('sensor_count.csv', index=False)
# Modify the link
link_data = pd.read_csv('input_link.csv')
link_data.loc[~link_data['count_sensor_id'].isin(set(sensor_count['count_sensor_id'])), 'count_sensor_id'] = np.nan
link_data['count_sensor_id'] = link_data['count_sensor_id'].astype('Int64')
link_data.to_csv('input_link.csv', index=False)
# RUN THE DTA
subprocess.call(["DTALite.exe"])最终的ODME结果,可见经过一定的迭代与调整后,仿真结果与真实结果更为接近了。
ODME的Demand Bug修正
DTALite在ODME的过程中存在一个BUG——所有的demand type在ODME之后将被清空,这意味着我们只知道调整后总的OD,但无法得知每一种具体的demand type下的OD。在此的解决方法就是基于output_agent提取出修正后最新的OD流量,并与原始的OD流量进行对比,求出修正系数后再乘在原始的带demand type的OD表中,并基于修正后的OD表,将input_scenario_settings中的traffic_assignment_method设置为1,进行重新分配,这样就可以得到带有demand type的output_agent.csv了:
# Get the final OD
Output_agent = pd.read_csv(r'output_agent.csv')
Output_agent['departure_time_in_hour'] = (Output_agent[' departure_time_in_min'] / 60).astype(int)
Final_OD = Output_agent.groupby(['from_zone_id', ' to_zone_id', 'departure_time_in_hour']).count()[
'agent_id'].reset_index()
Final_OD.columns = ['from_zone_id', 'to_zone_id', 'departure_time_in_hour', 'sim_number_of_agents']
del Output_agent
# Get the raw OD files
Input_demand_list = pd.read_csv(r'D:P3_DTAP3-PM-BASEYEAR-ODinput_demand_file_list.csv')
Raw_OD = pd.DataFrame()
for eachfile in Input_demand_list['file_name']:
tem = pd.read_csv(eachfile)
tem['departure_time_in_hour'] = int(eachfile.replace('_', '-').split('-')[1])
tem['demand_type'] = int(eachfile.replace('_', '-').split('-')[2])
tem.columns = ['from_zone_id', 'to_zone_id', 'number_of_agents',
'departure_time_in_hour', 'demand_type']
Raw_OD = Raw_OD.append(tem)
for eachhour in set(Raw_OD['departure_time_in_hour']):
tem = Raw_OD[Raw_OD['departure_time_in_hour'] == eachhour].reset_index(drop=True)
# The number of OD in one hour
tem_od = tem.groupby(['from_zone_id', 'to_zone_id']).sum()['number_of_agents'].reset_index()
tem_Final_OD = Final_OD[Final_OD['departure_time_in_hour'] == eachhour]
tem_od_gap = tem_od.merge(tem_Final_OD, on=['from_zone_id', 'to_zone_id'], how='outer').fillna(0)
# plt.plot(tem_od_gap['sim_number_of_agents'], tem_od_gap['number_of_agents'])
# how many agents should be adjust
tem_od_gap['gap'] = tem_od_gap['sim_number_of_agents'] - tem_od_gap['number_of_agents']
# The ratio of different types
tem_ratio = tem.pivot_table(index=['from_zone_id', 'to_zone_id'], columns='demand_type',
values='number_of_agents').fillna(0)
tem_ratio_need = tem_ratio.div(tem_ratio.sum(axis=1), axis=0).reset_index()
tem_od_change = tem_od_gap.merge(tem_ratio_need, on=['from_zone_id', 'to_zone_id'], how='left')
# tem_od_change = tem_od_change.sort_values(by='gap')
tem_od_change.update(round(tem_od_change.iloc[:, 6:].mul(tem_od_change.gap, 0), 0))
tem_od_change = tem_od_change.sort_values(by=['from_zone_id', 'to_zone_id']).reset_index(drop=True)
# Add back
tem_ratio = tem_ratio.reset_index().sort_values(by=['from_zone_id', 'to_zone_id'])
tem_ratio.iloc[:, 2:] = tem_ratio.iloc[:, 2:] + tem_od_change.iloc[:, 6:]
# Print the gap
print(str(eachhour) + ': Before: ' + str(sum(tem['number_of_agents'])))
print(str(eachhour) + ': Simulated: ' + str(sum(tem_Final_OD['sim_number_of_agents'])))
print(str(eachhour) + ': Adjust: ' + str((tem_ratio.iloc[:, 2:]).sum().sum()))
# Output OD
for eachtype in range(1, 25):
tem_ratio_each = tem_ratio[['from_zone_id', 'to_zone_id', eachtype]]
tem_ratio_each = tem_ratio_each[tem_ratio_each[eachtype] > 0]
tem_ratio_each.columns = ['from_zone_id', 'to_zone_id', 'number_of_agents']
tem_ratio_each.to_csv('pm_' + str(eachhour) + '-' + str(eachtype) + '-sub.csv', index=False)
# Change input_scenario_settings
input_scenario_settings = pd.read_csv(r'input_scenario_settings.csv')
input_scenario_settings['number_of_assignment_days'] = 10
input_scenario_settings['traffic_flow_model'] = 3
input_scenario_settings['traffic_assignment_method'] = 1
input_scenario_settings['ODME_start_iteration'] = 0
input_scenario_settings['ODME_end_iteration'] = 0
input_scenario_settings.to_csv(r'input_scenario_settings.csv', index=False)
# Run DTA
subprocess.call(["DTALite.exe"])最后打开output_agent.csv,确认demand type此时是否已经有数值了。如果有,则表明修复成功了。
基年流量分配与仿真
在得到合理的OD后,我们就可以开始进行流量分配了。一种做法是我们把上一步的output_agent.csv改成input_agent.csv,然后对应修改input_demand_file_list,将file_name设置为input_agent.csv,format_type设置为agent_csv;同时修改input_scenario_settings,traffic_assignment_method设置为1;ODME_start_iteration和ODME_end_iteration设置为0。然后点击DTALite运行,即可对基年的交通进行动态分配了。
使用input_agent的好处在于我们可以更为便利的调整车辆走向。比如某些道路过于拥堵或流量过低,则可以通过直接添加agent的方式进行调整:
# Modify the input_agent
input_agent = pd.read_csv('output_agent.csv', index_col=0)
# Add new agent if the simulated number is much smaller than the observed number
# Find the greatest gap and the corresponding link
for kk in range(0, len(tem_head1)):
each_from_node_id = str(tem_head1.loc[kk, 'from_node_id'])
each_to_node_id = str(tem_head1.loc[kk, 'to_node_id'])
each_gap = int((tem_head1.loc[kk, 'observed_link_count'] - tem_head1.loc[kk, 'simulated_link_count']))
each_start_time = int(tem_head1.loc[kk, 'time_interval'].replace('->', '').split(':00')[0]) * 60
each_end_time = int(tem_head1.loc[kk, 'time_interval'].replace('->', '').split(':00')[1]) * 60
input_agent['z_from_node_ind'] = input_agent['path_node_sequence'].str.find(each_from_node_id)
input_agent['z_to_node_ind'] = input_agent['path_node_sequence'].str.find(each_to_node_id)
# Fina all agents passing through the link
each_input_agent = input_agent[
((input_agent['z_to_node_ind'] - input_agent['z_from_node_ind'] - 1) == len(each_from_node_id)) & (
input_agent[' departure_time_in_min'] <= each_end_time) & (
input_agent[' departure_time_in_min'] >= each_start_time)]
# duplicates the rows
input_agent = input_agent.append(each_input_agent.sample(int(each_gap / 10), replace=True),
ignore_index=True)
input_agent = input_agent.reset_index()
input_agent.rename({'index': 'agent_id'}, axis=1, inplace=True)
input_agent.to_csv('input_agent.csv')将上面三步串联起来,即可实现ODME的全自动调参了。
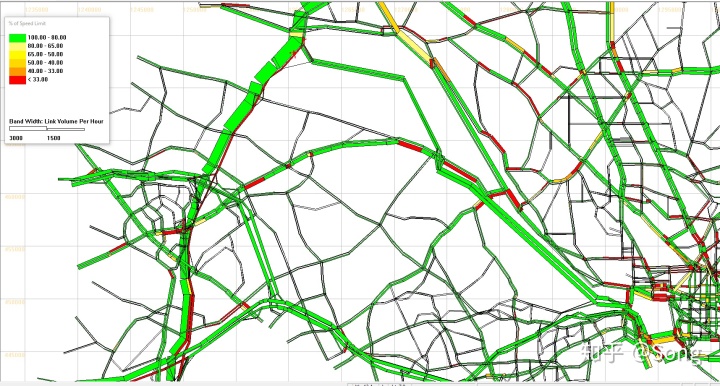
运行的结果可以通过NEXTA打开对应的.tnp文件实现。NEXTA可以展示密度、流量、车速、排放、排队、瓶颈等,同时还可以将仿真时段内整个路网的交通状态随时间的变化动态展示出来(如没有显示请点击左上加号以增加线宽):
知乎视频www.zhihu.com我们也可以将DTALite中的路网读取为Geopandas或者shp文件,从而在外部进行更为灵活的可视化与处理。这其中主要需要做好坐标系统的转化:
import matplotlib.pyplot as plt
import datetime
import pyproj
from pyproj import Proj, CRS, transform
import numpy as np
from shapely.geometry import Point, LineString, shape
import datetime
import contextily as ctx
pyproj.__version__ # (2.6.0)
# Get DTA coordinate
link_dta = pd.read_csv('input_link.csv')
link_dta['Start_XX'] = [var[4] for var in link_dta['geometry'].str.split('[> < ,]')]
link_dta['Start_YY'] = [var[5] for var in link_dta['geometry'].str.split('[> < ,]')]
link_dta['End_XX'] = [var[7] for var in link_dta['geometry'].str.split('[> < ,]')]
link_dta['End_YY'] = [var[8] for var in link_dta['geometry'].str.split('[> < ,]')]
# Project the DTA link to 84 #4326
transformer = pyproj.Transformer.from_crs('ESRI:102685', 'EPSG:4326', always_xy=True)
link_dta['Start_Lon'] = transformer.transform(link_dta['Start_XX'].values, link_dta['Start_YY'].values)[0]
link_dta['Start_Lat'] = transformer.transform(link_dta['Start_XX'].values, link_dta['Start_YY'].values)[1]
link_dta['End_Lon'] = transformer.transform(link_dta['End_XX'].values, link_dta['End_YY'].values)[0]
link_dta['End_Lat'] = transformer.transform(link_dta['End_XX'].values, link_dta['End_YY'].values)[1]
# Project DTA 84 to utm
transformer = pyproj.Transformer.from_crs('EPSG:4326', 'EPSG:32618', always_xy=True)
link_dta['Start_Lon_utm'] = transformer.transform(link_dta['Start_Lon'].values, link_dta['Start_Lat'].values)[0]
link_dta['Start_Lat_utm'] = transformer.transform(link_dta['Start_Lon'].values, link_dta['Start_Lat'].values)[1]
link_dta['End_Lon_utm'] = transformer.transform(link_dta['End_Lon'].values, link_dta['End_Lat'].values)[0]
link_dta['End_Lat_utm'] = transformer.transform(link_dta['End_Lon'].values, link_dta['End_Lat'].values)[1]
# Put DTALink To Geopandas
link_dta_gpd = pd.DataFrame(np.concatenate(
(link_dta[['link_id', 'Start_Lon', 'Start_Lat']].values, link_dta[['link_id', 'End_Lon', 'End_Lat']].values),
axis=0))
link_dta_gpd.columns = ['link_id', 'Start_Lon', 'Start_Lat']
geometry = [Point(xy) for xy in zip(link_dta_gpd.Start_Lon, link_dta_gpd.Start_Lat)]
link_dta_gpd = gpd.GeoDataFrame(link_dta_gpd, geometry=geometry)
gdf_link_dta = link_dta_gpd.groupby(['link_id'])['geometry'].apply(lambda x: LineString(x.tolist()))
gdf_link_dta = gpd.GeoDataFrame(gdf_link_dta, geometry='geometry')
gdf_link_dta = gdf_link_dta.reset_index()
gdf_link_dta_output = gdf_link_dta.merge(link_dta[['link_id', 'from_node_id', 'to_node_id', 'direction',
'number_of_lanes', 'speed_limit', 'lane_cap', 'link_type',
'link_type_name', 'jam_density', 'wave_speed', 'demand_type_code',
'count_sensor_id', 'speed_sensor_id', 'Start_Lon', 'Start_Lat',
'End_Lon', 'End_Lat', 'Direction']], on='link_id')
gdf_link_dta_output.crs = {'init': 'epsg:4326'}
gdf_link_dta_output.to_file('link_dta_84.shp')
gdf_link_dta.plot()仿真场景的转化
基年仿真往往是仿真的第一步,对于宏观仿真而言,往往还需要做未来的仿真。未来年的仿真与基年类似,其实就是换一个未来年的规划路网与未来年的增长OD矩阵,重新进行一次上述过程即可。
另一类仿真则是特定场景仿真,如设置收费道路、出现交通事故等,这些特定的场景在DTALite中也可以方便的实现。以交通事故为例,只需要在Scenario_Work_Zone中将出现事故的路段ID、减少的通行能力与速度、持续的时间输入即可:
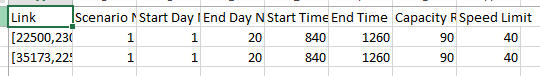
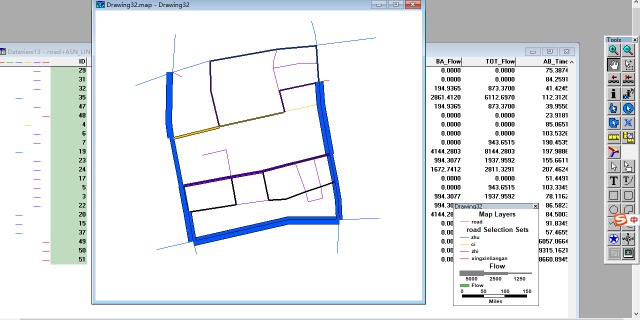
下图展示了事故出现后的仿真结果,可见当事故发生后,对应方向的交通状态明显恶劣了:
写在最后
至此,基于DTALite实现ODME与动态交通分配的基本操作基本就完成了。在整个过程中如果能结合自己熟悉的语言或软件,将DTALite作为一个主打交通分配的工具,则可以很好提升交通分配过程的精确度与速度。
当然,DTALite还具有很多其他的功能,如设置个性化的时间成本、设置动态信息指示、与其余交通仿真软件的对接、交通排放计算、信号控制设置等等,网上有更为系统的学习教程,感兴趣的可以前往对应的网站进行学习:
https://code.google.com/archive/p/nexta/code.google.com














 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









