





AdaGrad(Adaptive Gradient)
AdaGrad[1]是2011年发表的一种亚梯度方法,在很多大规模问题上验证了有效性.
它的迭代为:
关于数学符号,请看
郝曌骏:机器学习中的优化算法(1)zhuanlan.zhihu.com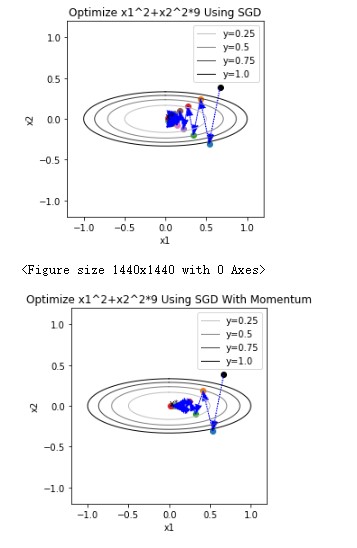
AdaGrad有类似于learning rate annealing的效果,不过学习率衰减不是迭代次数的函数,而是梯度平方和的平方根的函数.
预期达到的效果就是:- 之前梯度相对比较大的维度上更新幅度相对小.不同的维度的更新幅度的差距会减小- 随着梯度平方和的增加,更新幅度会越来越小,接近0
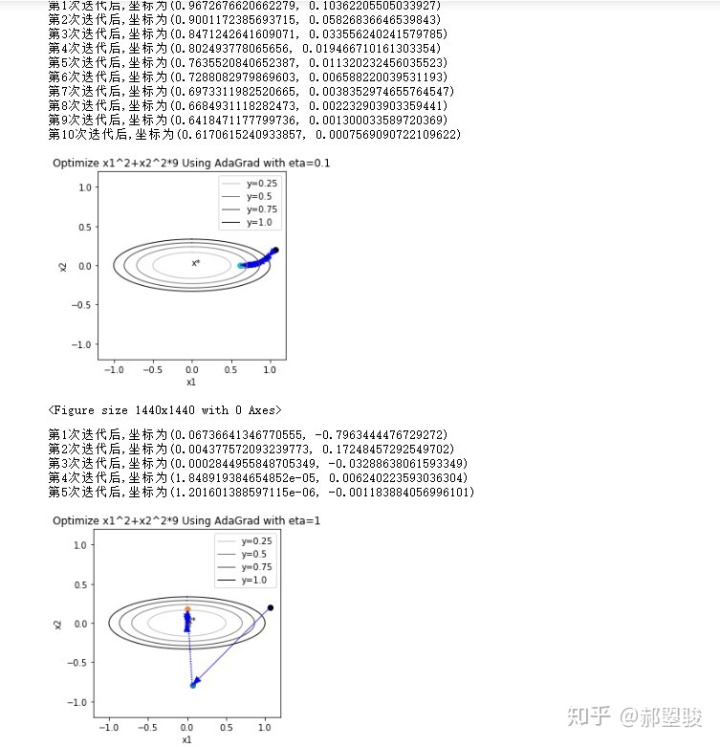
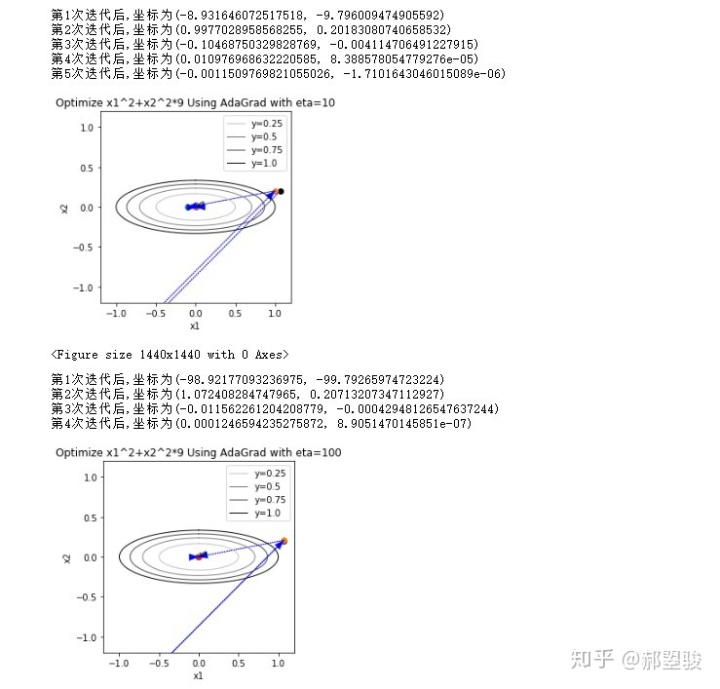
缺点:
- 分母持续增大,更新幅度会趋近于0,后期停滞
- 梯度的量级被消除,更新量对学习率很敏感
- 算法对学习率
很敏感,参考上面不同量级的学习率下算法的表现
Adadelta
Adadelta[2]是2012年作者在Google实习时提出的对AdaGrad的改进.
每次迭代为
其中
Adadelta对于AdaGrad的改进主要是
- 对于每个维度,用梯度平方的指数加权平均代替了至今全部梯度的平方和,避免了后期更新时更新幅度逐渐趋近于0的问题
- 用更新量的平方的指数加权平均来动态得代替了全局的标量的学习率,避免了对学习率的敏感
- 同时,文章作者提出Adadelta保证了更新量的量纲和参数一致
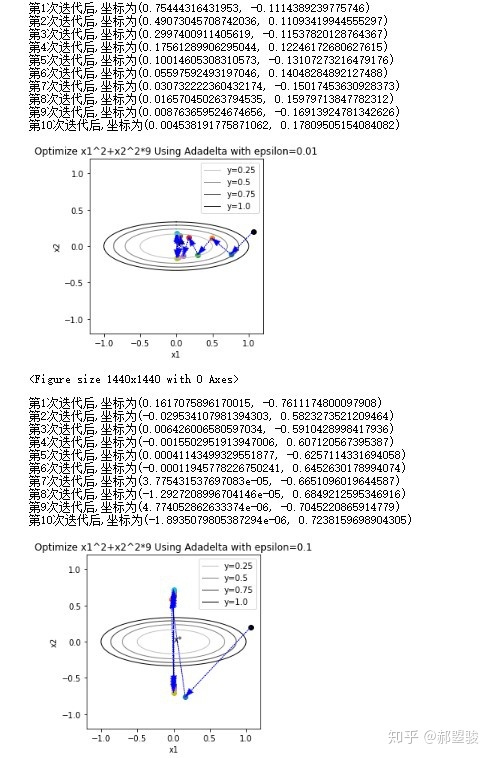
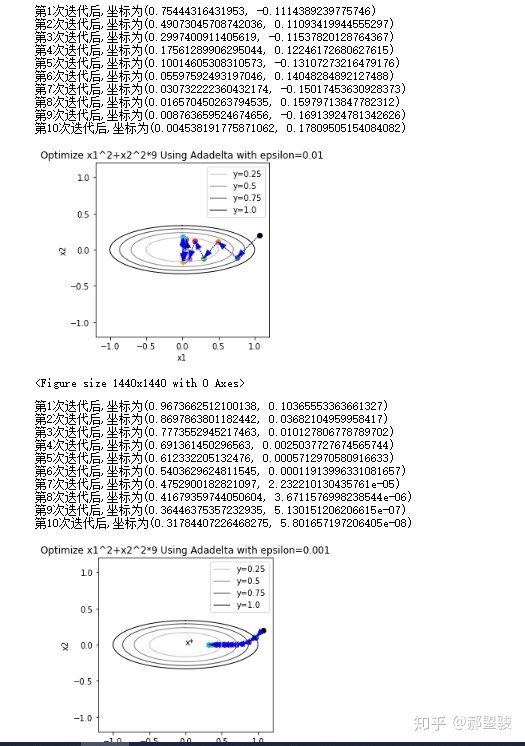
但是,实验中发现不需要人工设定的学习率,但是对
- 小了的话,前期步长很小
- 大了的话,后期容易引起震荡
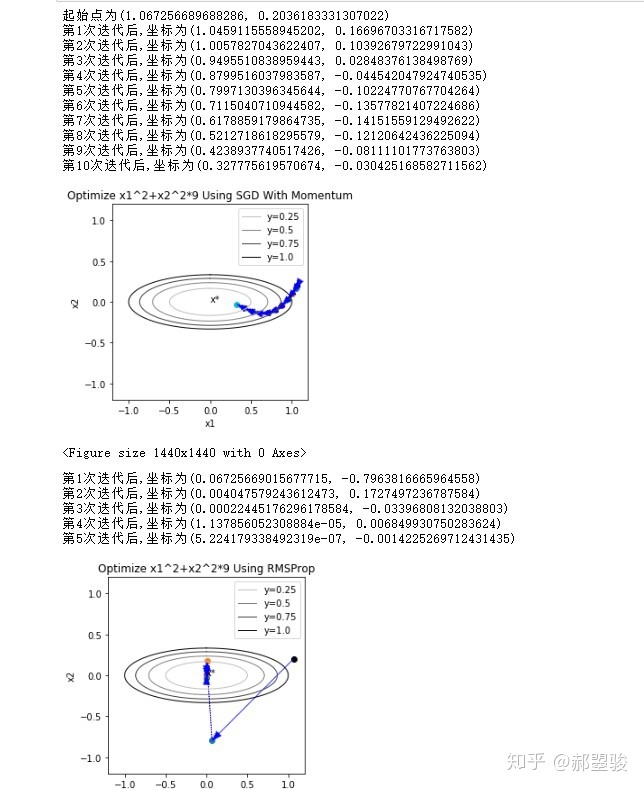
作为对比,以下是带Momentum的GD和RMSProp的效果
附录1
画图的代码
import 附录2
AdaGrad和Adadelta在pytorch中的实现为
import torch
torch.optim.Adagrad() # 学习率默认为1
torch.optim.Adadelt() # 学习率默认为0.01参考
- ^AdaGrad的论文 http://jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
- ^Adadelta的论文 https://arxiv.org/abs/1212.5701















 4334
4334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









