







摘要: 最近与某厂完成基于FATE的联邦学习框架的一个项目,第一次实践了一把联邦学习在实际业务场景中的应用,从模型评估结果来看,效果还不错。因此,本文将完成对于其中实现的提升算法 SecureBoost进行详细的介绍,算是对这个项目算法原理上的总结。
由于SecureBoost(SecureBoost: A Lossless Federated Learning Framework)中的Boosting算法是基于XGBoost来实现的,并将其扩展到横向联邦学习任务中来,在隐私保护方面做了一些分析与证明,因此熟悉XGBoost对于理解SecureBoost会起到事半功倍的作用。
本文将分成两大部分内容,首先会简单回顾一下XGboost的基本原理,如果你对这方面内容很熟悉了,可以跳过;第二部分,将是本文的重点内容,侧重于对SecureBoost原理的讲解,包括训练与预测环节;第三部分,简单做一点总结。
XGBoost原理回顾
正则化的损失函数(总)
XGBoost是Boosting算法家族中的一员,因此其形式上也是有
其中的假设空间中的所有CART回归树模型
- 树的结构(树的深度,叶子节点个数)以及特征分裂阈值,
- 叶子节点的权重(特别说明GBDT,XGBoost等使用的回归树,因为叶子节点存在权重信息)
单颗树的结构由字母
有了上述定义字母表示,就要介绍XGBoost中使用的正则化的损失函数了,相比GBDT模型,引入了正则项用于防止过拟合,其形式如下所示:
从损失函数上不难理解,在给定
正则项主要有两部分构成:
- 叶子节点权重的
范数,目的是使得权重值更平滑,连续;
- 叶子节点的个数
,在XGBoost中树的生长方式是Level-wise的方式,每一层都需要同时进行分裂,有可能导致不必要的特征参与分裂,如下图对比所示
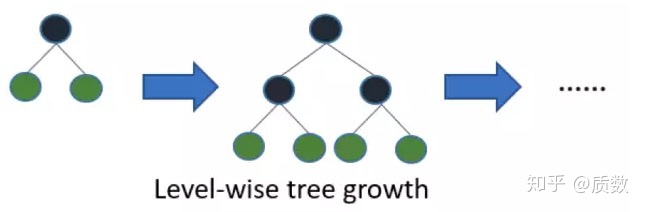
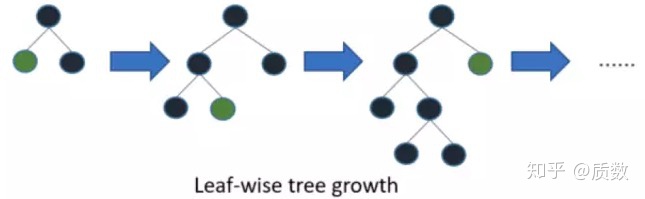
图1:两种决策树生长方式
第
假设在完成第
此时,将损失函数
完成了在第
细节
- 公式(4)的第一步中,跟
式的区别是,正则项只有前
颗树,因为此时才迭代到第
颗树,后面的树还需要在学习;
- 公式(4)中的第二步,直接将公式(3)带入即可;
- 公式(4)从第二步到第3步,发现已经将正则项,从累加变成了第
颗树的正则项,以及常数
,因此在此时前面第
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









