





本次将采用爬虫获取一些新闻数据,比如我们要获取新浪的一些新闻:
1、编写代码,获取新浪首页的网页源码:
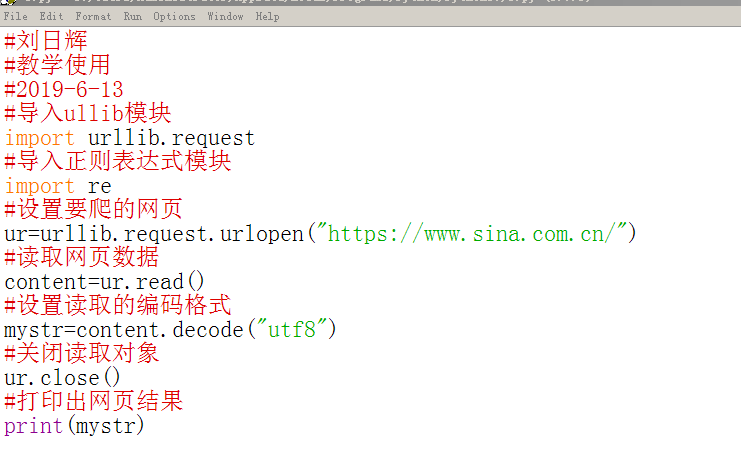
运行效果:
我们会看到程序输出了新浪网页的所有源代码:
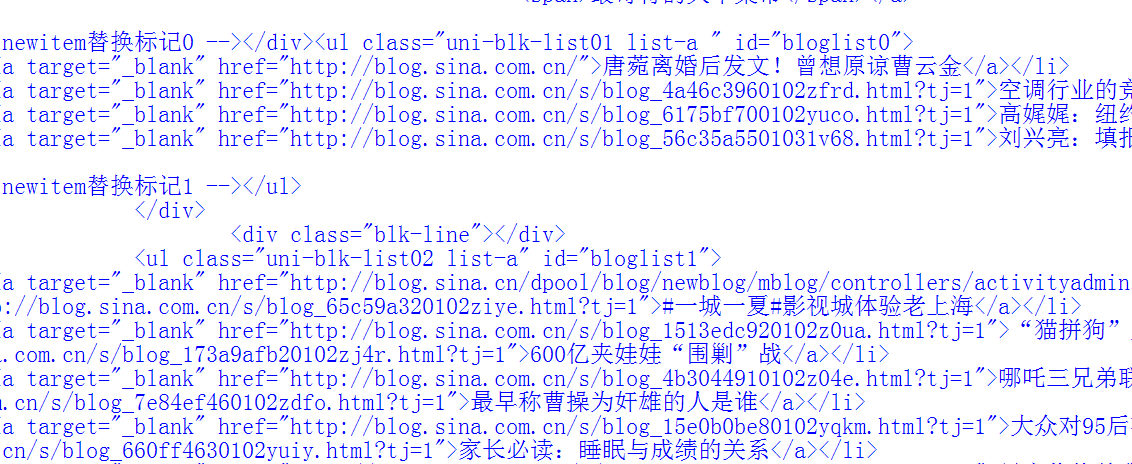
网页源代码非常长,我们单纯通过split()函数来切割是不现实的,所以我们要用re正则表达式模块:
当我们发现我们想要的东西都有一些规律的时候,我们可以通过正则表达式来提取:
比如我们看到源代码里面有一个规律如下,很多新闻的前后都是.shtml" target="_blank">万科:物流地产狂想曲:

所以我们可以通过新建一个正则表达式来提取,下面我们对之前的代码加入正则表达式部分:
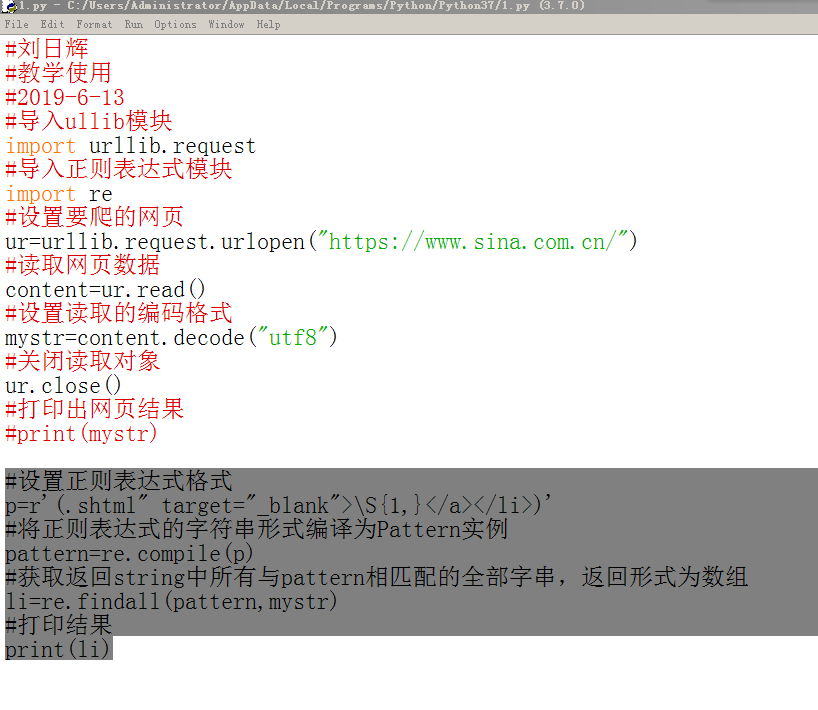
上面中的\S{1,}意思是匹配一个以上的任意非空字符
运行后结果:

我们看到,上面比之前的少了很多内容。
我们把上面的内容梳理一下发现也是有规律的:列表的每个元素都可以通过split()切割:

所以我们加入切割方法,采用循环从列表中抽取数据的方式进行处理:
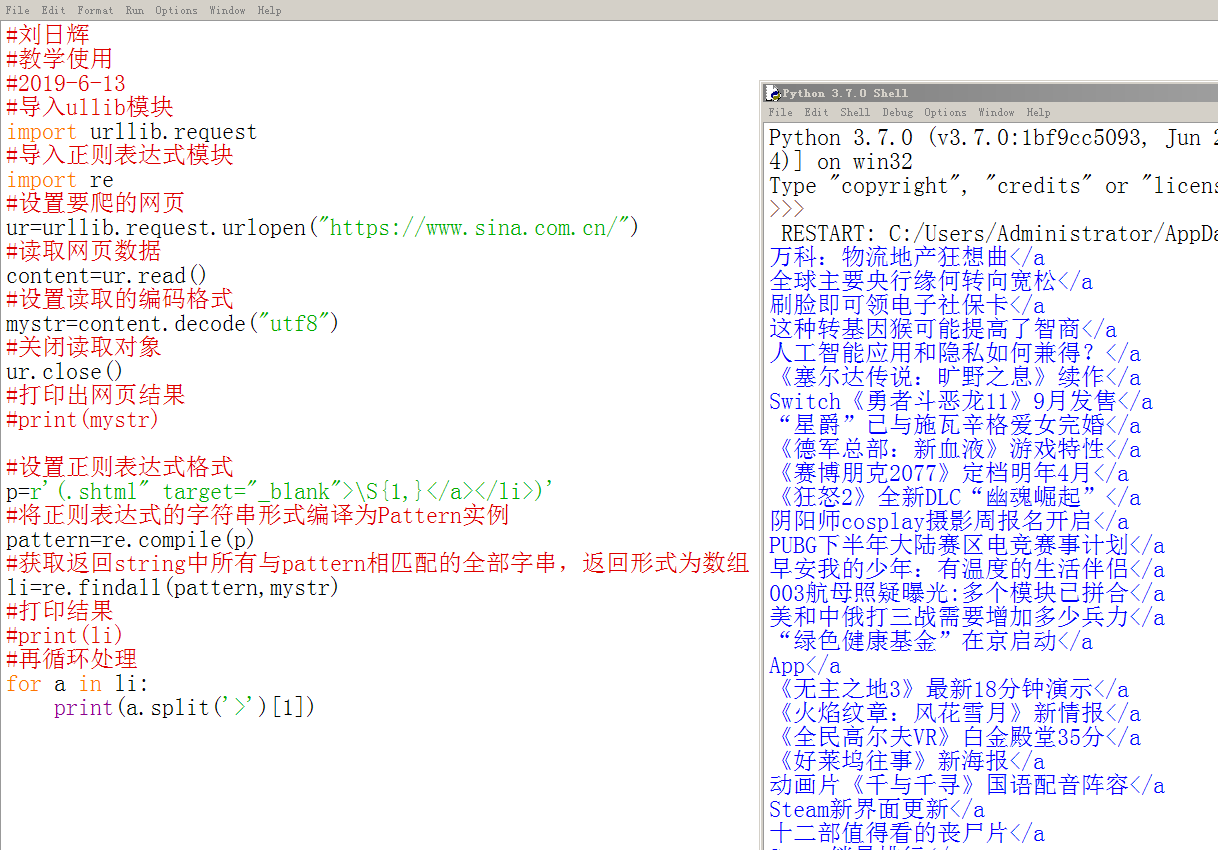
这个时候我们发现处理后的内容比较接近我们想要的数据了,但是还是有HTML样式,所以再进一步处理。
再次对结果切割后已经符合我们的要求了:
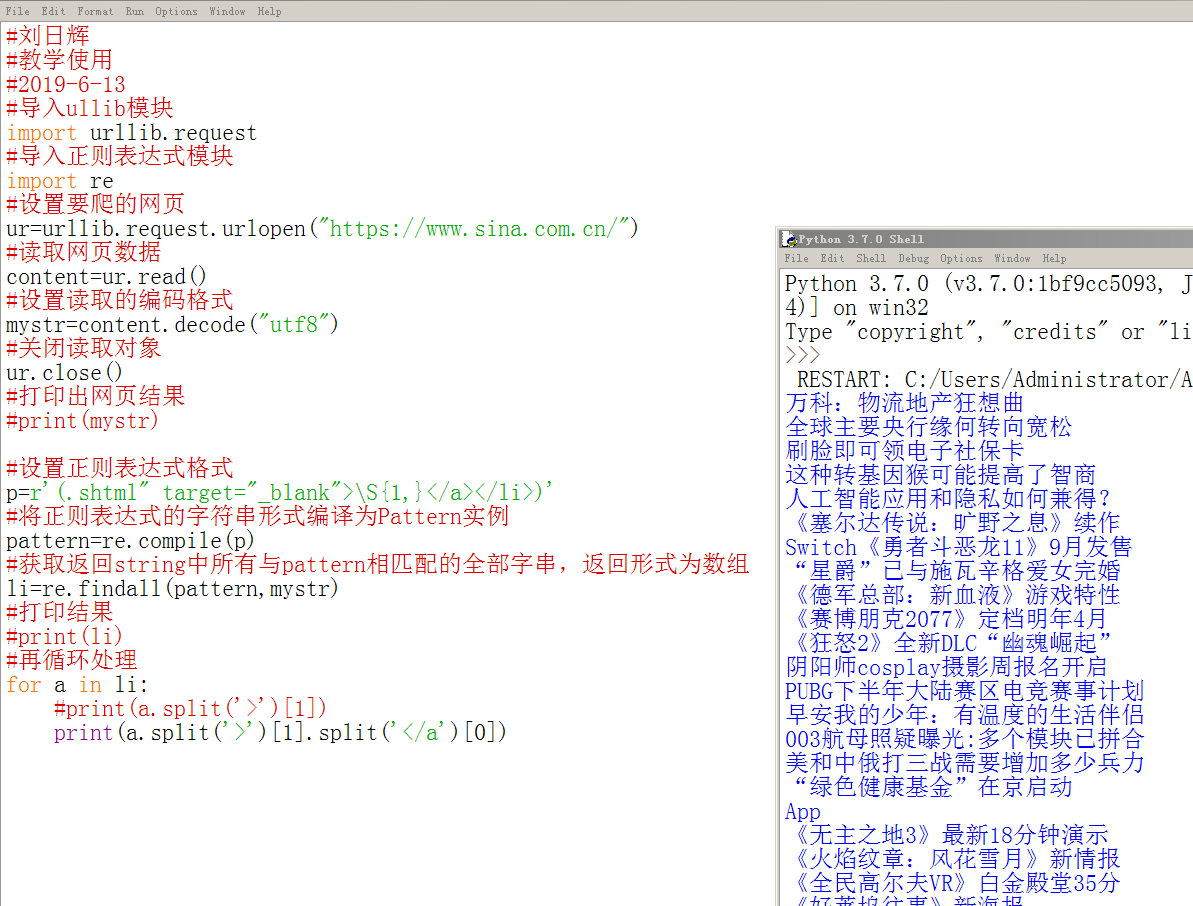
那么,我们得出的结果符合要求了,我们要存到一个列表里面备用:
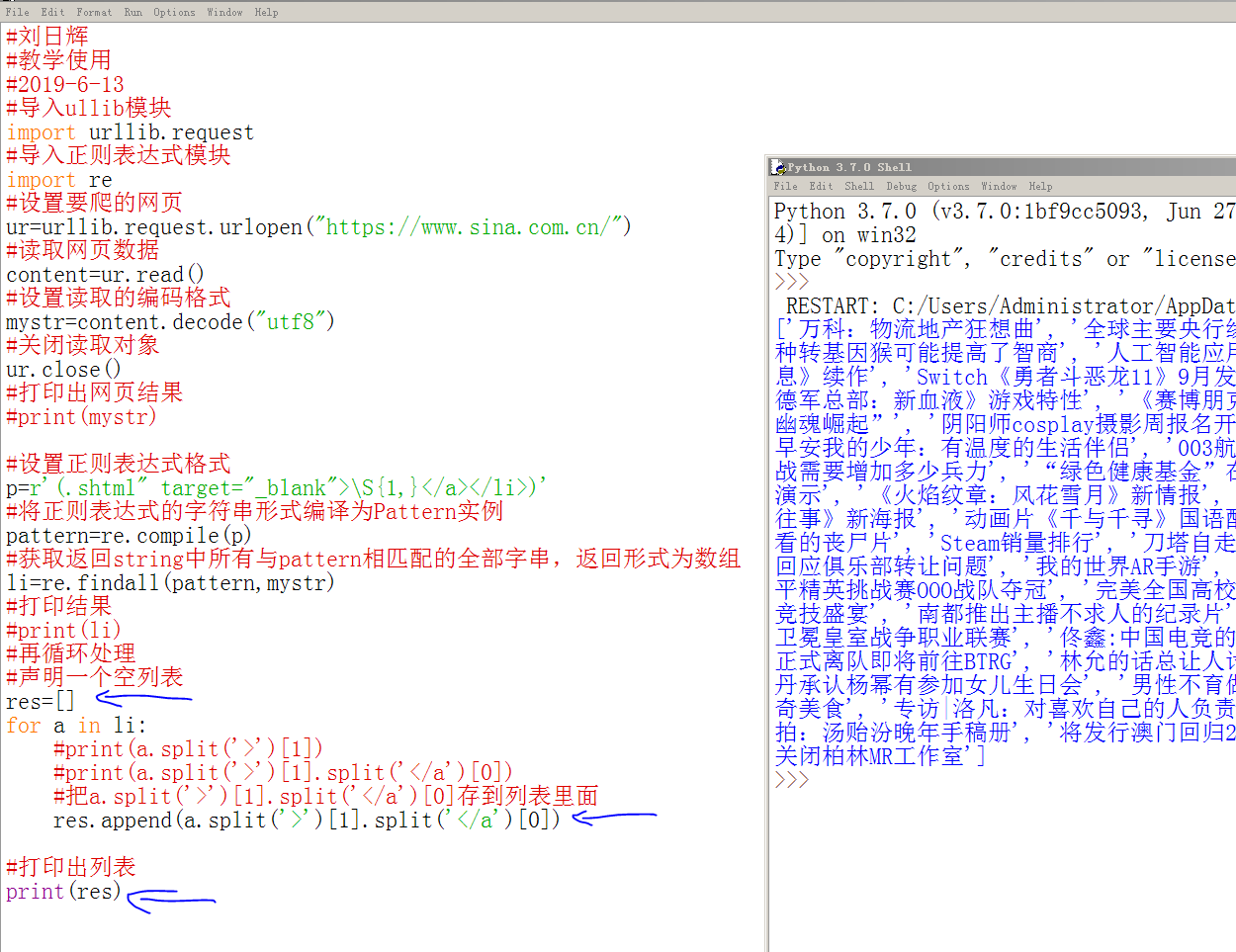















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









