





思想
其实出发点我觉得不难想到,主要基于以下几点设计出来了SSD的结构:
- 相对于Faster RCNN家族的两阶段检测,想一个网络最后直接出两个head,一个算bbox们的分类loss,一个算bbox相对于标准位置(也就是所谓anchor)的位置偏差loss。而不是像Faster RNN那样RPN算一次loss(分类回归都要算),ROI Pooling后还要再算一次loss。因此提出一阶段模型。
- 既然希望只算bbox相对于标准位置上anchor的一次偏差loss,就需要定义标准anchor的(x0,y0,w,h),也就自然想到用Faster RCNN的anchor,即从feature map上每个位置出n个不同scale不同aspect ratio的anchor。但faster rcnn是将每个scale和每个aspect ratio都组合,比如3x3=9个anchors,每个位置会出9个anchor会显得太冗余了。因此ssd在anchor设定这块减少了数量。
- 既然一个网络就要学到bbox位置偏移量,如果是faster rcnn那类只在一种scale上的feature map想检测出各种大小的ground truth框有点困难了,引入类似FPN的结构,在浅层和深层等不同大小的feature map上都进行预测,这样能利用不同大小的感受野,检测到原图上大小尺寸不同的物体。
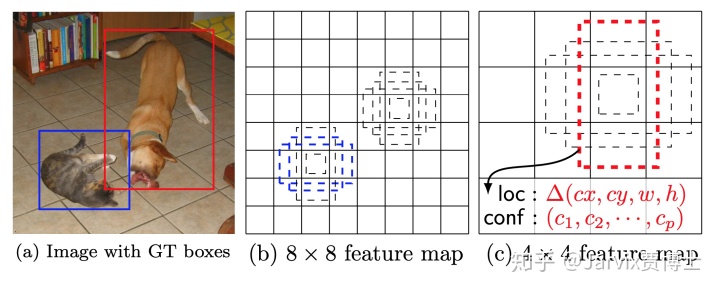
这张图能把我说的第2,3点讲清楚了。
原图(a)中有一个较小的目标(篮框),和一个较大的目标(红框)。
原图经过多层卷积后,可以在某层上得到8x8的feature map,即图(b),也可以在稍后面的层得到4x4的feature map,即图(c)。
针对图(b),每个位置上出4(或6)个,图中是出4个不同scale和aspect ratio的anchors。比如ratio_anchor=2x2,也就是在8x8和4x4两种feature map上anchor size是相同的,都是2x2,那么由于8x8层对应的感受野比4x4的小,因此2x2的anchor对应到原图上则是较小的一块区域。那么,原图中较大的目标(红框表示的物体)在8x8 feature map很可能没有anchor能检测到它,但蓝框物体是可以在8x8 feature map上检测到的,即图(b)中的2个蓝虚线框所表示的anchors。对应的,4x4 feature map的感受野更大,它上面就可能有对应的anchor能检测到原图中较大物体,即图(c)中的红虚线框所表示的anchor。这样一来,原图中一大一小两个物体就在不同scale的feature map上被检测出来了。
这就是为什么SSD要利用“直筒”网络的不同scale的feature maps,每个都出classifier head和regression head来做检测的原因。
backbone
原文中的图例使用的是VGG。
先看原始的VGG网络结构,如下图:

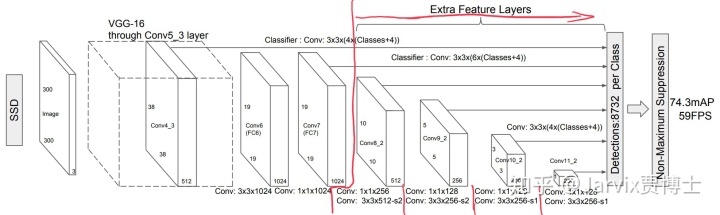
作为SSD的backbone时,只用到了conv5以前的层。pool5开始到后面几个FC层都去掉了。
去掉原始的一些层之后,作者又加入了新层,如下图所示。

conv5-3之后的三层:pool5,conv6和conv7都是新增的。这里pool5的stride=1并没有做downsampling,保持了conv5-3的output size。
按论文中作者设定的输入图片大小为(B,3,300,300),那么conv5-3之后得到(B,512,19,19),pool5后仍然为(B,512,19,19)。
pool5后接了一个3x3带dilation的卷积层conv6,又接一个1x1的conv7。这两层的输出都相同,为(B,1024,19,19)。
- 空洞卷积的作用是扩大感受野。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。在检测、分割任务中十分有用。一方面感受野大了可以检测分割大目标(对conv7及其之后的层有帮助),另一方面分辨率高了可以精确定位目标。
- 1x1卷积在这里的作用是进一步增加非线性。
extra layers
这些层为了逐步得到multi scale的feature而存在。具体请看下图:
从conv8到conv11共四层,出4种不同scale的feature map。
conv8-1的输入也就是conv7的输出,shape=[B,1024,19,19]
-------------------------------------------------------------------------------------------
经过conv8-1,ksize=1,filter num=256,输出[B,256,19,19](1x1降低channel数)
经过conv8-2,ksize=3,filter num=512,stride=2,padding=1,输出[B,512,10,10]
-------------------------------------------------------------------------------------------
经过conv9-1,ksize=1,filter num=128,输出[B,128,10,10] (1x1降低channel数)
经过conv9-2,ksize=3,filter num=256,stride=2,padding=1,输出[B,256,5,5]
-------------------------------------------------------------------------------------------
经过conv10-1,ksize=1,filter num=128,输出[B,128,5,5]
经过conv10-2,ksize=3,filter num=256,stride=1,输出[B,256,3,3]
-------------------------------------------------------------------------------------------
经过conv11-1,ksize=1,filter num=128,输出[B,128,3,3]
经过conv11-2,ksize=3,filter num=256,stride=1,输出[B,256,1,1]
-------------------------------------------------------------------------------------------
以上就得到了extra feature layers,对应于原论文中图例的结构。
multibox
从上一步得到[B,512,10,10],[B,256,5,5],[B,256,3,3],[B,256,1,1]四种feature map,再加上conv4-3[B,512,38,38]和conv7[B,1024,19,19]两层较浅的特征(为了检测小目标)。
这六个feature map,每个位置上都要出4或6个anchors,每个anchor要输出n_classes个prob(cls_head),和4个bbox偏移量(reg_head)。
假如anchor_num=4, cls_head的卷积层out_channel=(anchor_num)x(n_classes),reg_head的卷积层out_channel=(anchor_num)x4。这些卷积的kernel size和padding都相同,ksize=3,padding=1。最终得到:
cls_head = [B, (anchor_num)x(n_classes), 38/19/10/5/3/1, 38/19/10/5/3/1]
reg_head = [B, (anchor_num)x4, 38/19/10/5/3/1, 38/19/10/5/3/1]
multi_box_cfg = [4,6,6,6,4,4],也就是这6个feature map上每个位置放置的anchor数不同的。有的层每个位置放4个anchor,有的feature map的每个位置放6个anchor。
那么,总的detection bbox数=38x38x4+19x19x6+10x10x6+5x5x6+3x3x4+1x1x4=8732















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









