





决策树:使用环境:信息不确定性衡量熵值类型:
信息熵:信息不确定性衡量
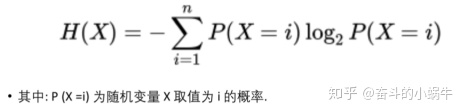
条件熵:获取更多信息减少不确定性
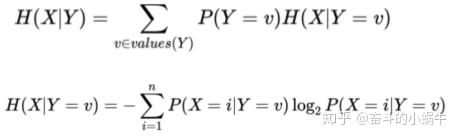
信息增益:父节点熵-子节点熵,最大信息增益的特征为最佳分割特征
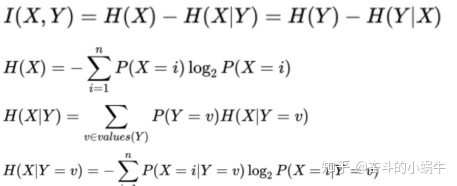
举例:
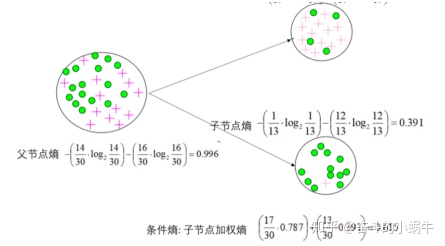
/示例
依据天气预测是否打高尔夫球的概率:两个步骤
步骤1:(确定分割节点,对于分割节点的每种情况继续进行分割)
步骤2:依据建好的树进行预测
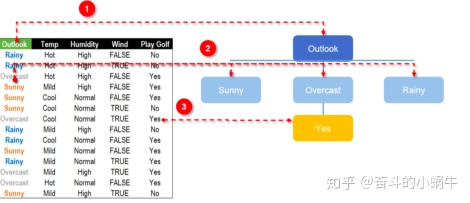
步骤1: 建树---确定父节点
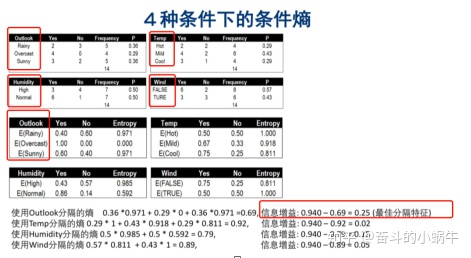
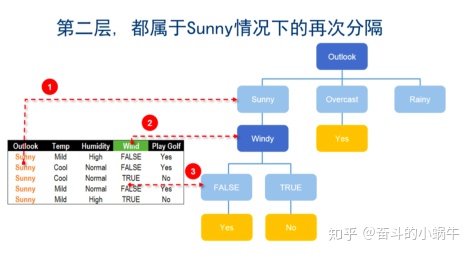
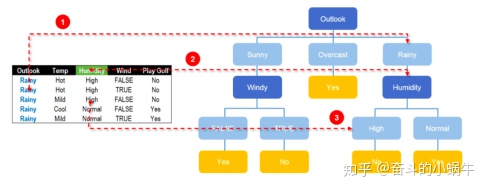
步骤1: 建树---确定子节点
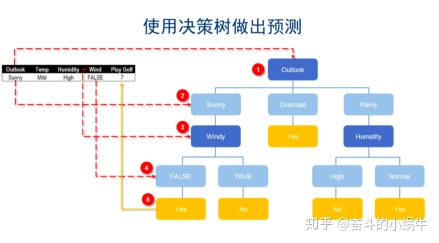
步骤2: 预测
值为连续值情况如何确定?
解决办法:将连续值划分为n个区间,每个区间作为一个值
/
总结:优缺点 优点:
可解释性高(可以整棵树展示)
可以处理非线形数据
不需要归一化
可用于特征工程、特征选择?
对数据分布没有偏好
广泛使用
容易实现
可以转换为规则
缺点:
启发式生成,不是最优解
容易过拟合
微小数据改变会改变整棵树形状
对类别不平衡的数据不友好随机森林:与adaboost区别: 随机是并行,adaboost是串行的原理:同时训练多个决策树,然后进行投票,根据投票结果做预测随机性特点:训练数据中随机选择子集;选择分叉特征的时候,随机选择一个特征优势:
消除了决策树容易过拟合的缺点;(带放回的去样,样本可能重叠)
减少预测的变化(不会因为训练数据的小变化而剧烈变化)
案例:离职预测:kaggle数据















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









