





"Wouldn't you like to know why reducing internal covariate shift speeds up gradient descent?...
Wouldn't you like to know what internal covariate shift is?"
"你们不想知道为什么减少ICS就能加速GD过程吗?...你们就不想知道何为ICS吗?"
--Ali Rahimi@NIPS 2017
导言

批量规范化(Batch Normalization)方法,能大幅加速模型训练,同时保持预测准确率不降,因而被一些优秀模型采纳为标准模型层。
这一次,我们从零开始,一步步了解Batch Norm方法的初衷、算法、效果和原理分析,然后不借助深度学习框架,实现这个算法,并在数据集上验证效果。
初衷
深度神经网络(Deep Neural Networks)的训练,往往需要反复调试参数的初始化,使用小学习率参数,导致训练较慢;此外,饱和非线性模型,函数在饱和区导数趋于0,也使模型不易训练。
Batch Norm方法的作者,把上述问题归因于 internal covariate shift(ICS),认为:在DNN训练过程中,每一层输入数据的分布,随前层参数的变化而变,层间输入分布的变化,使训练变得复杂,带来了上述问题。
然而:
什么是covariate?
什么是 shift?
这个internal covariate shift又是什么?
分布偏移
监督学习有个基本假设:源空间的训练数据和目标空间的待预测数据,是独立同分布的( independently and identically drawn from the same distribution)。
Dataset Shift
训练数据和待预测数据分布不同,称为数据集偏移(Dataset shift)。
如果训练样本容量小,或者实验设计不当,采集得到的训练样本,其特征不能反映真实世界的总体特征,就会导致dataset shift。
Covariate Shift
输入分布偏移(Covariate Shift)是一种特殊的dataset shift。
定义输入数据x是解释变量( explanatory variable)或协变量(covariate),类别标签y是应变量(response variable),如果训练数据和待预测数据的条件概率相同,而边缘概率不同:
这种情况被称为Covariate Shift。
又由条件概率定义的引申:
可以推知,此时训练数据和待预测数据的联合概率也不同:
训练出来的模型,预测失准了。
Internal Covariate Shift(ICS)
Batch Norm方法的作者,用ICS来表述机器学习模型中,层间输入数据分布变化的情况,没有给出ICS的正式定义;作者希望通过减少层间协变量偏移,改善模型训练效率,以此为初衷,提出了Batch Norm方法。
Batch Norm前向传播
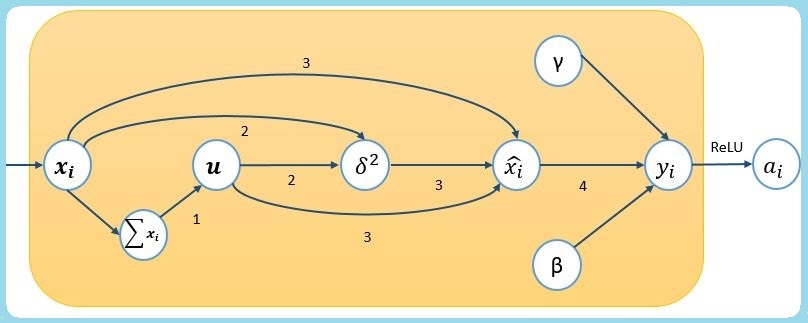
模型训练前向传播时,设每个容量为m的mini-batch是样本集合X,对其中每个单一样例
其中,式(3)分母的ε(1e-8)是平滑项(a smoothing term), 用于在方差极小的情况下,避免除0错( avoids division by zero) 。
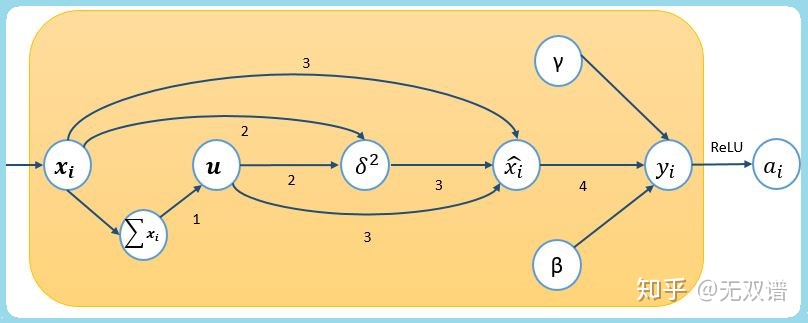
观察前三步,把输入数据规范化为均值为0,方差近似1的标准化变量,再通过式(4)的线性变换,做伸缩(scaling)和平移(shifting),通过γ和β参数训练,学习合适的伸缩与平移幅度,恢复模型表达,得到mini-batch的Batch Norm输出;训练完成后,学习得 γ 和 β 参数。
训练过程中,保留所有mini-batches计算得到的样本均值和方差,用于预测时做无偏估计,在实现篇详细介绍,此处不再展开。
你可以进一步了解规范化,也可以跳到卷积层的Batch Norm处理一节继续阅读,不影响方法使用。
再深一点-关于规范化
Batch Norm的规范化,是利用标准化变量,把mini-batch中的输入,转换为近似正态分布的步骤。
观察前三步:
可知转换后的期望:
转换后的方差:
由于平滑因子ε取值较小,转换后的结果,均值为0,方差接近1。
Batch Norm方法正是基于这一原理,把输入数据规范化为近似标准正态分布, 再通过学习得到的参数,对数据做缩放和平移,恢复特征表达;输出的数据,仍然近似的服从。
卷积层的Batch Norm处理
对线性处理的全连接层:
由于经过Batch Norm处理时,通过训练β参数,进对线性变换的结果做了合适的平移,bias项可以忽略不用。
对卷积层:
如果置于Batch Norm层之前,同样可以忽略bias项;
卷积层输出特征张量的通道数,由卷积核的个数决定,每个输出通道(深度)上的特征张量(feature map),其不同区域使用同一组γ、β参数做Batch Norm处理。
Batch Norm的效果
从结果看,深层网络,普遍使用BN取得更好的训练效果:
- 缓解了梯度传递问题,使模型适应更大的学习率,加速了训练;
- 改善了饱和非线性模型不易训练的问题;
- 还起到了正则化的作用。
梯度传递问题
我们知道,对神经网络的全连接层,第 L 层(全连接层)原始输出:
该层经过函数 f 激活后的输出:
第 L -1层的原始输出误差 δ 可以由 L 层的输出误差反推得到:
如果不考虑激活处理,则在深度网络中,从第L层,反向传播到第L-n层的误差:
网络较深的情况下,经过权参累乘,误差传递可能出现问题:
如果权参张量
两种情况被分别称为 梯度弥散(vanishing gradients)和梯度爆炸(exploding gradients)
上面例举了全连接层处理,观察卷积层误差传递:
也有同样的问题。
应用了Batch Norm方法后,各层的输出和误差回传都经过一次缩放调整,整个模型对学习率的选择和初始化敏感度相应降低,改善了训练效果。
饱和非线性激活问题
回顾激活函数的作用和图像,饱和非线性(saturating non-linearity)函数sigmoid(右上)和tanh(左下):
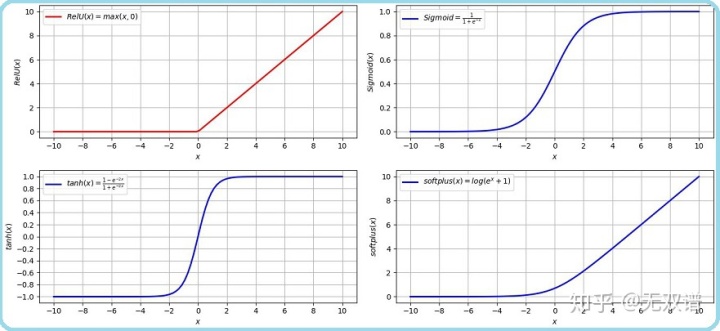
在横轴x=0附近,导数较大,远离x=0的数据,逐渐落入激活函数的饱和区:激活后的神经元输出,对输入的变化不再敏感,造成梯度消失,降低训练速度。
而非饱和(non-saturating)激活函数ReLU(左上)和softplus(右下),单侧抑制输出,右侧有宽广的激活边界。
Batch Norm方法经过规范化和缩放平移,可以使输入数据,重新回到非饱和区,还可以更进一步:控制激活的饱和程度,或是非饱和函数抑制与激活的范围。
正则化效果
Batch Norm的作者通过实验观察到:增加的BN,也有缓解过拟合的作用,对模型起到了正则化效果。
作者分析了原因:由于Batch Norm处理,一个mini-batch里的不同样本相互影响,起到了正则化作用,但是着墨不多;显然,作者自己对这个原因分析并不满意。
2018年,MIT一个研究小组的工作认为:正则化,而不是去ICS,才是Batch Norm有效的原因。
Batch Norm为何有效
按照去ICS的思路:经过网络中前置层的变换,当前层输入的分布改变,影响了训练;Batch Norm方法所以有效,是由于在非线性层之前,通过控制各层输入分布的均值和方差,来稳定各层输入的分布,从而促进了训练效果。
那么Batch Norm是不是通过去ICS,而改善了模型呢?
或者反过来问,Batch Norm之后再添加ICS,模型会变差吗?
研究小组在Batch Norm层后,增加随机噪声( random noise),这些随机噪声和输入数据是独立同分布的,然而不同于Batch Norm处理后输出的数据分布,这些噪声均值不为0,方差也不为1;经过实验,训练出来的参数,仍然好于不用Batch Norm的对照模型,由此证明方法的有效性和ICS不相关。
上面这个实验,可以说是这项工作的一大亮点。
如果和ICS不相关,那Batch Norm为什么有效呢?
这个小组观察到,使用了Batch Norm方法的神经网络模型和深度线性模型,损失和梯度都减少了抖动,优化损失的解空间更平滑,一些同样起到平滑效果的正则化方法,在深度线性网络上也起到了Batch Norm的优化效果。由此认为,Batch Norm正是由于这些平滑效果,解决了梯度传递与非饱和激活问题,提升训练性能。
小组也试图探究Batch Norm是否实现了去ICS,为此,计算了先后两次权参w更新之间,w梯度变化,希望以此间接给出ICS的量化定义,通过实验比较变化,认为Batch Norm可能没有去除“ICS”,甚至可能使“ICS”加剧了。这个结论是小组从自己定义的“ICS”出发得到的。
小结
Batch Norm方法的初衷,是解决internal covariate shift问题,然而真正发挥的作用,是缓解了梯度传递问题,以及饱和非线性激活问题,通过平滑优化解空间,起到了正则化作用,使模型对大步长学习率敏感度降低,更加易于训练。
接下来的“实现篇”,将进一步介绍Batch Norm在训练和预测阶段,处理方式的差异和以及差异的缘由;介绍方法的学习策略和反向传播推导;不借助深度学习框架,实现Batch Norm方法的训练和预测算法,并在数据集上观察训练效果。
(完)
下一篇:反向传播推导、无偏估计预测、numpy实现:
无双谱:从0到1:批量规范化Batch Normalization(实现篇)zhuanlan.zhihu.com
参考
[1] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[2] Arthur Gretton, Alexander J Smola, Jiayuan Huang, Marcel Schmittfull, Karsten M Borgwardt, and Bernhard Schölkopf. Covariate shift by kernel mean matching. 2009.
[3] Ali Rahimi and Ben Recht. Back when we were kids. In NIPS Test-of-Time Award Talk, 2017.
[4] Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. How does batch normalization help optimization? (no, it is not about internal covariate shift). arXiv preprint arXiv:1805.11604, 2018.
[5] PennStat class STAT 414 The Pennsylvania State University STAT 414















 6363
6363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









