






为了更好的浏览体验,可访问:
PDF版github.com本文直接翻译了综述,后期会有系列文章,解析常见的几个语言模型、原理等。
摘要
作为自然语言处理(Natural Language Processing,NLP)系统的核心组件,语言模型(Language Model,LM)能够提供词的向量表示和词序列的联合概率。神经网络语言模型(Neural Network Language Models,NNLM)克服了维度灾难,并且大大提升了传统语言模型的性能。本文主要阐述了神经网络语言模型综述。首先,本文大致描述了经典的神经网络语言模型结构,然后介绍和分析一些主流的模型改进方法。本文总结和对比了神经网络所用的数据集、工业实践中的一些工具库,以及一些神经网络语言模型研究方向。
绪论
语言模型是大部分NLP任务的基础,如在机器翻译(Machine Translation,MT)任务中,语言模型被用来评估翻译系统输出一个特定序列的概率,以提升其在目标语言中的流畅度。而在语音识别(Speech Recognition,SR)任务中,将联合语言模型和声学模型来预测输出下一个词。
早期的NLP系统主要基于人工编写的规则,该过程不仅耗时长,而且难以完成以至无法覆盖到多样的语言环境。20世纪80年代,人们提出了对于构成序列
其中
考虑到难以学习上述模型中的大量参数,通常需要一种近似方法来近似表示。N元模型便是一种近似方法,并且在神经网络语言模型之前,一直作为最优模型而被广泛使用。
困惑度(Perplexity,PPL)[13]是一种语言模型评估方法,其本质上是一个信息论中概率模型质量评估指标。当困惑度值越低时,则表明模型更优。给定一个包含N
上述公式表明,困惑度与语料库紧密相关,因而两个或多个语言模型只有构建在相同的语料库上才能使用困惑度进行对比。
然而,
虽然使用平滑技术的n元模型能够正常工作,却仍然有其他问题,其中维度灾难便是一个重大问题,从而大大制约了通用语言模型在大规模语料库上的建模能力,当人们想要对离散空间中的联合分布建模时,这个问题及其显著。例如,当你想要建模一个10,000词汇的
为了解决这个问题,便引入了神经网络(Neural Network,NN)使语言模型映射到一个连续空间。包括前馈神经网络(Forward Feedback Neural Network,FFNN)和循环神经网络(Recurrent Neural Network,RNN)在内的神经网络都能自动学习到特征和连续的表征。因此,人们都希望神经网络能够应用于语言模型,甚至是其他的NLP任务,以适配自然语言的离散、组合和稀疏的特性。
第一个前馈神经网络语言模型( FFNN Language Model,FFNNLM)是由[5]提出,通过学习词的分布式表示来解决维度灾难,使得一个词能够使用一个低维向量(称之为embedding)表示。FFNNLM比
本文主要集中于讨论NNLM的各种方法及其发展趋势。在第2节我们将介绍经典神经网络语言模型,第3节将分别讨论和分析NNLM的各类改进方法,紧接着,在第4和4节将介绍常用的数据集和工具库,最后,得出本文的结论,并讨论今后NNLM的研究方向。
经典神经网络语言模型
前馈神经网络语言模型
[35]曾尝试将NN应用于LM,虽然他们的模型比基准的
根据公式(1)的表示,LM的目标等价于评估一个条件概率
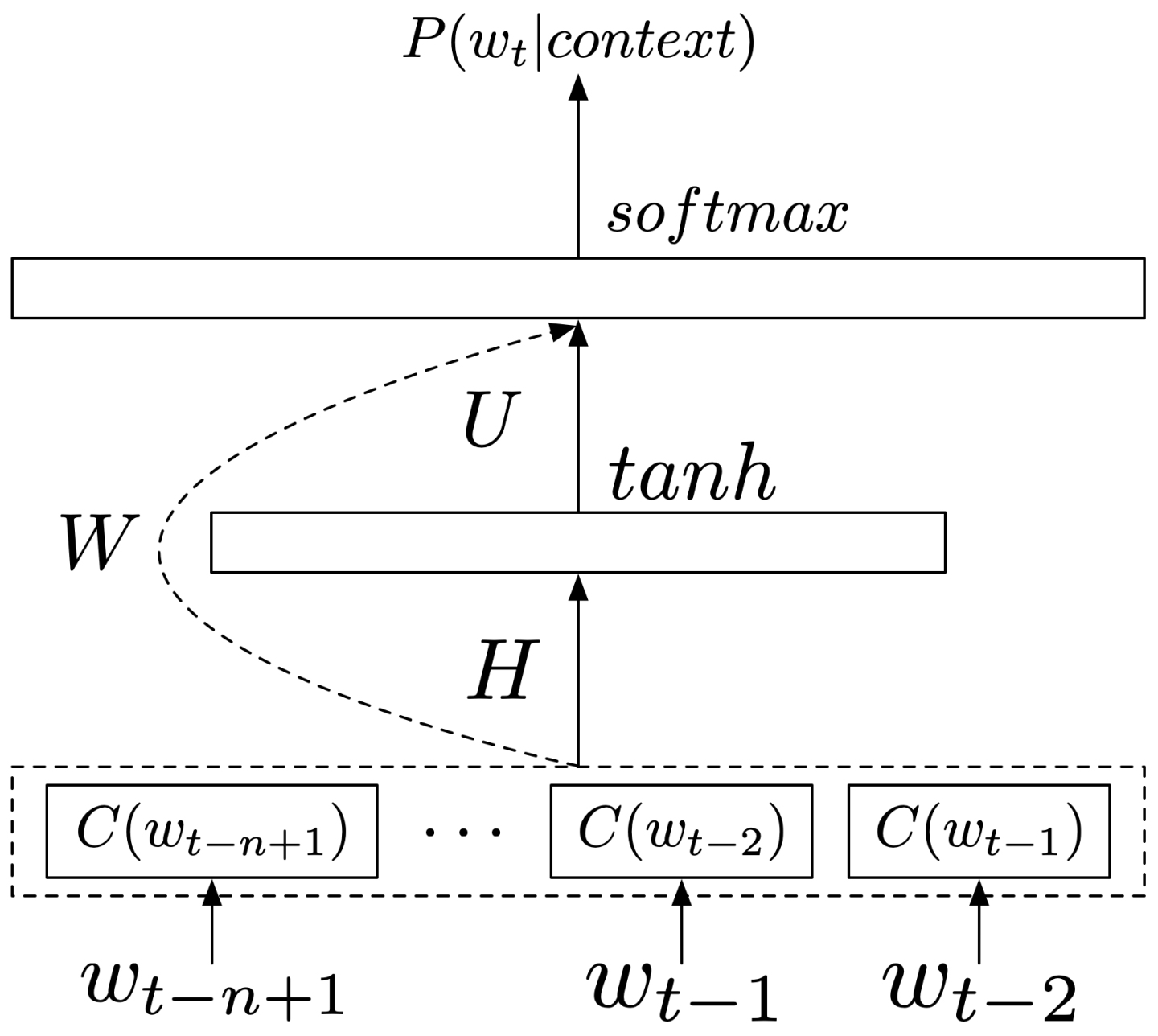
[7]提出了如图1所示的最原始的FFNNLM结构,其能够表示为:
其中,
FFNNLM通过学习到每个词的分布式表示,来实现在连续空间上的建模。其中,词的表示只是LM用于提升其他NLP任务的副产品。基于FFNNLM,[1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









