






本文主要根据Redis提供的部分功能在业务功能场景下的应用举例。
(由于缓存的空间有限性,缓存在使用过程中,正常情况下必须设置超时的,所以以下的业务场景大部份是基于缓存会过期的实例应用场景规则)
缓存的使用建议查看「微服务」缓存本质全分析、对比与实践
字符串特性
#分布式锁
也称分布式协调技术,主要防止多服务之间的相互影响。
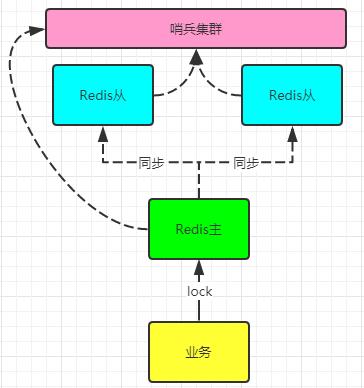
Redis的原子性set key value EX 过期秒数 NX天然对分布式锁的实现友好,但是由于Redis的主从异步同步特性,如果主Master宕机而Slave未复制到锁,则会产生锁丢失,导致业务重入。而且需要注意业务的时间与锁定时长,必须要需要考虑锁继期。建议使用框架Redisson。
#计数器
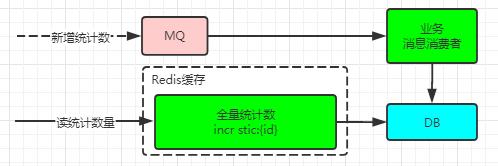
1.统计业务的计数,如访问次数、短信发送次数等统计

如图(注意上图的全量统计数是永久的,不过期),系统的统计数据如果是非严格的,则可以依赖于Redis直接实现。新增的统计数据划分为日统计与全量统计,新增统计时(如果允许Lua,则可以原子性的进行操作),同时增长日统计与全量统计,然后通过定时同步工具将增量统计数据入库。
如果是需求严格的统计,建议使用MQ。
2.抢购库存扣减
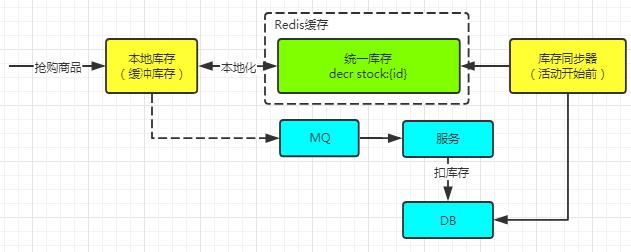
商品在活动开始前由库存同步器将存库数量同步到统一库存(Redis)中,然后通过如MQ、Redis的PUB/SUB机制通知到抢购服务层,抢购服务层根据配置计算本地库存与设置缓冲库存。
该机制主要是为了避免库存的超卖与少卖机制,缓冲库存越大则容错量越高。
本地库存与缓冲库存的作用是防止流量突发全部打到缓存层照成缓存层负载过高或宕机。
缓冲库存概述解释
缓冲库存是为了防止少卖。
假设有3台服务,总库存100,则可能划分33,33,34。抢购时有一台宕机,宕机服务所剩余的库存则会丢失。
添加缓冲库存就是为了冗余库存数据,如配置为15,则每台本地总库存=15+33(34)=48(49)。如果抢购时,有一台宕机,则宕机的部份被其他服务冗余。
所以,缓冲库存是为了在抢购服务层中提供一个库存的缓冲,以防止某台抢购服务层宕机导致部份库存丢失,照成少卖。
列表(List)
#简单消息队列
基于Redis的RPOPLPUSH 特性,实现相对安全的队列。依赖于Redis群集的稳定性决定消息的丢失概率

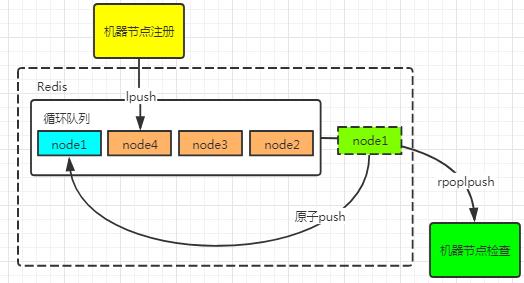
#循环列表
基于Redis的RPOPLPUSH 特性,实现如机器列表的安全健康检查。
#消息列表
基于Redis的列表(List)+ 集合(Set)实现评论/点赞列表。
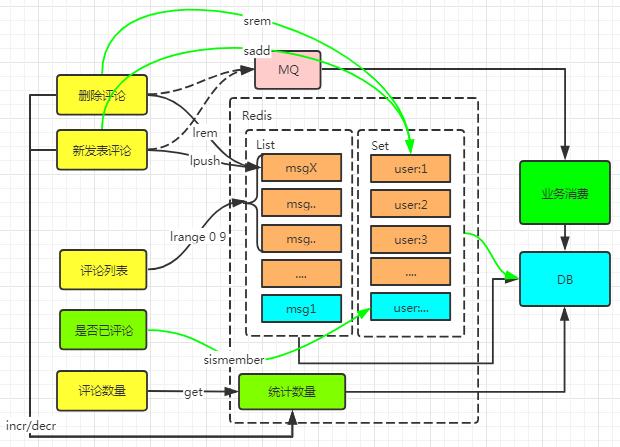
用户在新增、删除评论时,在缓存层实现业务操作,然后通过MQ实现数据库的数据最终一致性。
一篇文章在发表时属于热点数据(指实时公告、新闻之类的发布时会被大量人员关注的),用户的访问量会较大,所以,所有的操作都在缓存层直接实现。而在1天或者几天之后,该文章基本不会被人阅读,此时缓存失效,使用基本的缓存操作(读缓存,不存在则读数据库)的业务逻辑对数据库的压力影响并不会太大。
集合(Set、ZSET)
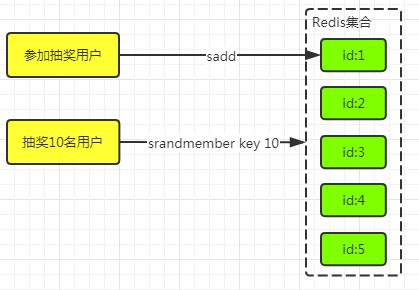
基于Redis的集合(Set)特性,实现随机的场景需求。如抽奖活动。
#抽奖
#可能认识的人
利用Redis的集合(SET)的SDIFF取差集获取可能认识的人列表。
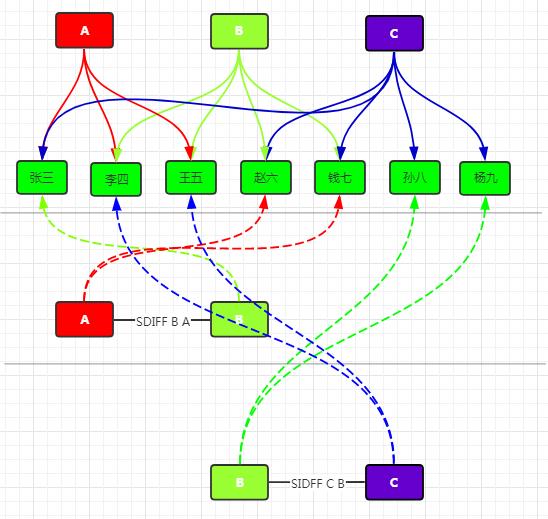
如图,举例说明了Redis的SDIFF特性的可能认识的人的一个应用。该特性还可以应用在如支付对账(支付系统与第三方支付系统订单差异对账)等场景。
#共同关注
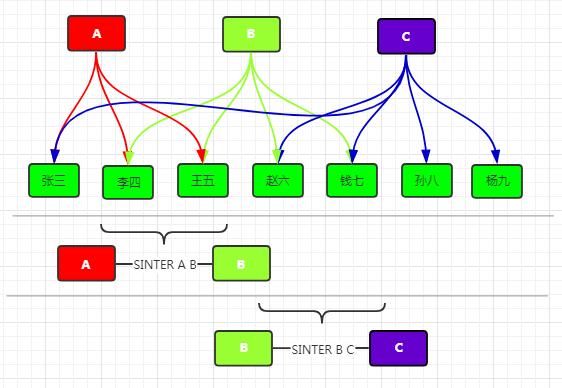
共同关注其实就是交集的计算。延伸应用如商品类型筛选场景。
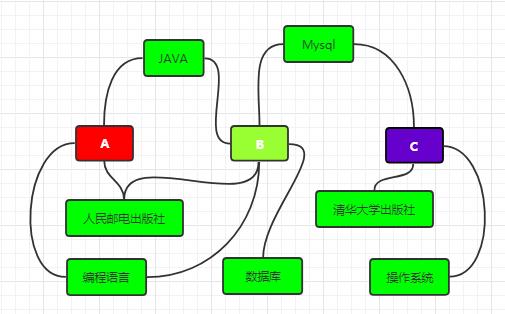
筛选 SINTER 人民邮电出版 编程语言 可以得到 A和B。
#排行榜
Reids的有序集合(ZSET)可以用来实现排行榜、好友列表、去重、历史记录等场景。
ZREVRANGE key start stop [WITHSCORES]
返回有序集 key 中,指定区间内的成员。
其中成员的位置按 score 值递减(从大到小)来排列。 具有相同 score 值的成员按字典序的逆序(reverse lexicographical order)排列。
除了成员按 score 值递减的次序排列这一点外, ZREVRANGE 命令的其他方面和 ZRANGE key start stop [WITHSCORES] 命令一样。
基数统计(HyperLogLog)
适用于在大量数据的去重计算。如: 统计注册 IP 数、统计每日访问 IP 数、统计页面实时 UV 数、 统计在线用户数、统计用户每天搜索不同词条的个数等场景。
HyperLogLog在使用过程中,最大只需要使用12KB内存(pfadd:内存是按使用慢慢增加的,而不是直接占用12KB,pfmerge:合并之后存储占用12KB)
但是需要注意的, HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。同时会存在0.81%的一个误差。

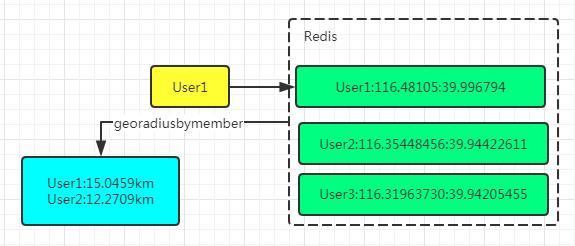
地理位置(GEO)
#附近的人
位图(BITMAP)
位图(Bitmap)是通过一个 bit 来表示某个元素对应的值或者状态。它并不是什么新的数据结构。它的内容其实就是普通的字符串。我们可以通过 get/set 获取位图的内容,也可以使用 getbit/setbit 操作 bit 值(0 或者 1)。
Bit即比特,是目前计算机中数据最小的单位。8个Bit一个Byte(字节)。Bit的值,要么为 0 ,要么为 1。由于Bit是计算机中最小的单位,使用它进行储存将非常节省空间。特别适合一些数据量大的场景。例如,统计每日活跃用户、统计每月打卡数等统计场景。
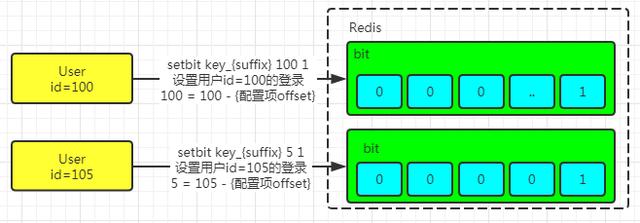
但是,需要注意,如果设置了大值的偏移量,可能会导致性能问题。建议将偏移量控制在8388608(8MB内存)内。
#用户年登录历史

#用户留存率
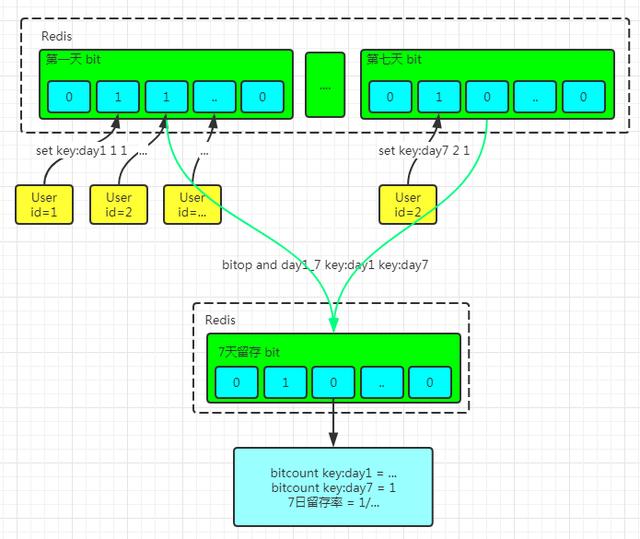
如果最大偏移量过大,可能导致内存的申请较量,堵塞Redis。所以,需要对用户的增长评估,设置用户分段。















 1867
1867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









