






一、Flink概述
1、技术发展趋势
(1)2020年,在整个大数据领域,Flink可算是火得一塌糊,不但将阿里Blink中的大部分特性merge到社区的Flink中,使得Flink在流式实时计算领域更是一骑绝尘,让其他实时计算框架只能望其项背
(2)目前Flink根本看不到其他的对手!同时Flink新版本又完美的兼容Hive,使得Flink在离线计算也快马加鞭,飞速赶超,完美实现批流统一,甚至很多有人称2020年为批流统一元年!、
2、Flink简介
(1)Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算
(2)可部署在各种集群环境,对各种大小的数据规模进行快速计算
3、Flink的历史
(1)早在 2008 年,Flink 的前身已经是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一
(2)Flink的商业公司 Data Artisans,位于柏林的,公司成立于2014年,共获得两轮融资共计650万欧。该公司旨在为企业提供大规模数据处理解决方案,使企业可以管理和部署实时数据,实时反馈数据,做更快、更精准的商业决策
(3)目前,ING, Netflix 和 Uber 等企业都通过 Data Artisans 的 Apache Flink 平台部署大规模分布式应用,如实时数据分析、机器学习、搜索、排序推荐和欺诈风险等
2019年1月8日,阿里巴巴以 9000 万欧元收购该公司!
4、Flink的特点
- 批流统一
- 支持高吞吐、低延迟、高性能的流处
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 支持迭代计算
- Flink在JVM内部实现了自己的内存管理
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
5、传统Lambda架构的存在的问题
Storm
| 优点 | 缺点 |
| 低延迟 | 吞吐量低、不能保证exactly-once、编程API不丰富 |
Spark Streaming
| 优点 | 缺点 | 概述 |
| 吞吐量高、可以保证exactly-once、编程API丰富 | 延迟较高 | Spark就是为离线计算而设计的,在Spark生态体系中,不论是流处理和批处理都是底层引擎都是Spark Core Spark Streaming将微批次小任务不停的提交到Spark引擎,从而实现准实时计算,SparkStreaming只不过是一种特殊的批处理而已 |
存在的问题:
- 处理延迟较高
- 对状态的支持不完美
- 对窗口的支持不灵活
- 不支持EventTime
Flink
| 优点 | 缺点 | 概述 |
| 低延迟、吞吐量高、可以保证exactly-once、编程API丰富 | 快速迭代中,API变化比较快 | Flink就是为实时计算而设计的,Flink可以同时实现批处理和流处理 Flink将批处理(即有有界数据)视作一种特殊的流处理 |
实时未来技术要求:
- 高吞吐
- 在压力下保持正确
- 操作简单
- 延迟低
- 时间正确、语义化窗口
6、Flink架构简介
JobManager
(1)也称之为Master,用于协调分布式执行,它用来调度task,协调检查点,协调失败时恢复等
(2)Flink运行时至少存在一个master,如果配置高可用模式则会存在多个master,它们其中有一个是leader,而其他的都是standby
TaskManager:
(1)也称之为Worker,用于执行一个dataflow的task、数据缓冲和Data Streams的数据交换,Flink运行时至少会存在一个TaskManager
(2)JobManager和TaskManager可以直接运行在物理机上,或者运行YARN这样的资源调度框架
(3)TaskManager通过网络连接到JobManager,通过RPC通信告知自身的可用性进而获得任务分配
7、SparkStreaming和Flink的角色对比
| SparkStreaming | Flink |
| DStream | DataStream |
| Trasnformation | Trasnformation |
| Action | Sink |
| Task | SubTask |
| Pipeline | Oprator chains |
| DAG | DataFlow Graph |
| Master + Driver | JobManager |
| Worker + Executor | TaskManager |
二、Flink搭建
1、standalone模式
standalone模式是Flink自带的分布式集群模式,不依赖其他的资源调度框架
2、部署standalone模式
(1)下载flink安装包,下载地址https://flink.apache.org/downloads.html

(2)上传flink安装包到Linux服务器上、解压flink安装包
[root@Master module]# tar -xvf flink-1.12.0-bin-scala_2.12.tgz -C /module(3)修改conf目录下的flink-conf.yaml配置文件
[root@Master module]# cd flink-1.12.1/conf/
[root@Master conf]# vim flink-conf.yaml
#指定jobmanager的地址
jobmanager.rpc.address:Master
#指定taskmanager的可用槽位的数量
taskmanager.numberOfTaskSlots: 2(5)将配置好的Flink拷贝到其他节点
[root@Master module]# scp -r flink-1.12.1/ Slave01:$PWD
[root@Master module]# scp -r flink-1.12.1/ Slave02:$PWD(6)执行启动脚本
[root@Master flink-1.12.1]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host Master.
Starting taskexecutor daemon on host Slave01.
Starting taskexecutor daemon on host Slave02.(8)访问:http://master.apache.com:8081/
3、flink的Web UI页面讲解
(1)在主页面的Available Task Slots(节点槽数数,我这里有2个槽)数量显示为Available Task Slots:2
(2)在主页面的Running Jobs(表示正在运行的job,我这里没有正在运行的job)数量显示为Running Jobs:0
(3)在主页面的Task Managers,查看可用的槽有几个?这里的类目有:
192.168.242.104:33214-32da38
akka.tcp://flink@192.168.242.104:33214 / user / rpc / taskmanager_0 43606 21-02-02 17:40:11 2 2 1个 973兆字节 512兆字节 512兆字节
192.168.242.104:45007-e982f0
akka.tcp://flink@192.168.242.104:45007 / user / rpc / taskmanager_0 40185 21-02-02 17:40:11 2 2 1个 973兆字节 512兆字节 512兆字节
192.168.242.103:33177-7df92b
akka.tcp://flink@192.168.242.103:33177 / user / rpc / taskmanager_0 35815 21-02-02 17:40:11 2 2 1个 973兆字节 512兆字节 512兆字节
192.168.242.103:46633-c6fdf8
akka.tcp://flink@192.168.242.103:46633 / user / rpc / taskmanager_0 33584 21-02-02 17:40:11 2 2 1个 973兆字节 512兆字节 512兆字节
- 路径,ID(Path,id)
- 数据口(Data,Port)
- 最后的心跳(Last Heartbeat)
- 所有的插槽(All Slots)
- 空闲插槽(Free Slots)
- CPU核心(CPU cores)
- 物理MEM(Physicay MEM)
- JVM堆大小(JVM Heap size)
- Flink托管MEM(Flink Managed MEM)
(4)查看task-manager详情信息
http://master.apache.com:8081/#/task-manager/192.168.242.103:46633-c6fdf8/metrics
(5)提交任务(2种方式)
第1种,通过命令行提交
第2种,通过web页面提交
在主页面的Submit New Job,进行提交,提交Flink任务,步骤如下:
(1)方法jobManager所在节点的8081端口,点击Submint New Job。方法jobManager所在节点的8081端口,点击Submint New Job
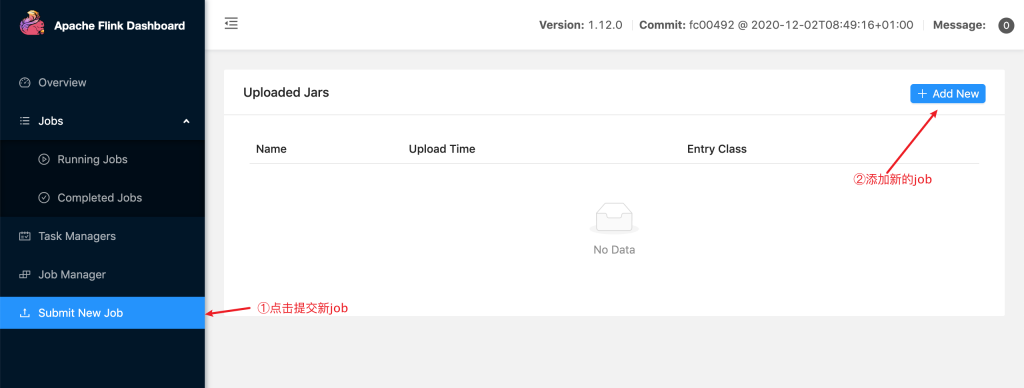
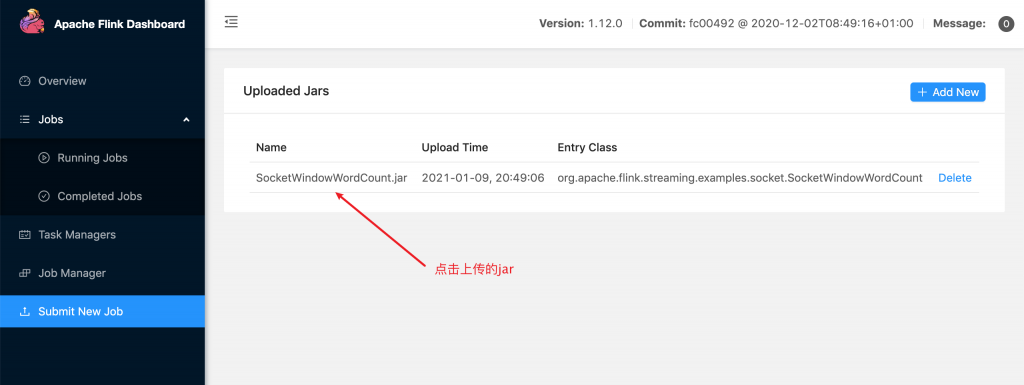
(2)点击Add New 上传Jar包,这个示例jar包在官方给的example目录下(提交SocketWindowWordCount.jar文件)
(3)编辑提交的信息,在设置图标指定路径参数为:--hostname Master --port 8888,这里并行度参数为:3
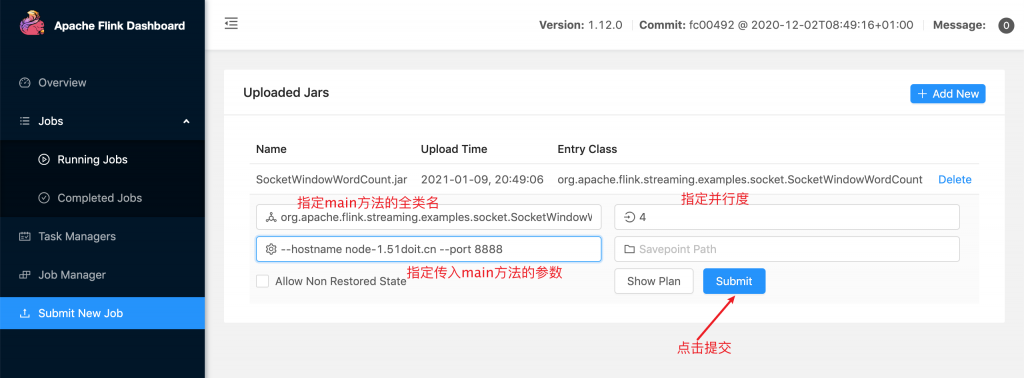
参数说明:
| -m | 指定主机名后面的端口为JobManager的REST的端口,而不是RPC的端口,RPC通信端口是6123 |
| -p | 指定是并行度 |
| -c | 指定main方法的全类名 |
(4)提交之前需要在linux环境下,执行命令:nc -lk 8888
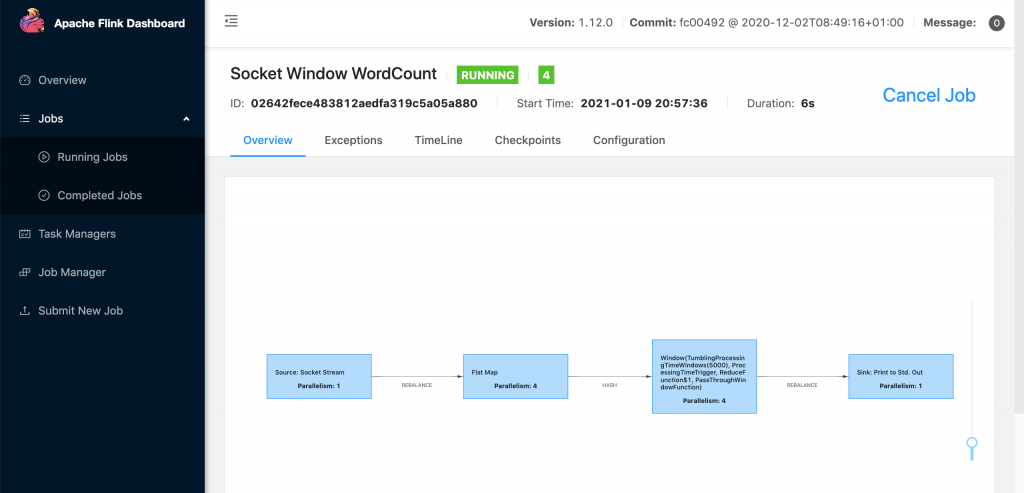
(5)提交后,路径为:http://master.apache.com:8081/#/job/d48df62b819a870e8741746b246007e7/overview,打印出来的信息
(6)在命令行输入生产的数据,而真正运行的是在http://master.apache.com:8081/#/task-manager/192.168.242.103:46633-c6fdf8/stdout
终止job任务,在http://master.apache.com:8081/#/job/0280580f1ef739ee9eaa61d29890d5e5/overview的Cancel Job按钮
停止任务后,它的资源占用的槽就会释放
三、准备环境
(1)在window环境下的cmd窗口下,执行该命令,生成flink(java语言)项目模板
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.12.0 -DgroupId=cn._51doit.flink -DartifactId=flink-java -Dversion=1.0 -Dpackage=cn._51doit.flink -DinteractiveMode=false
(2)打开idea工具以open方式打开该项目模板
(3)删除BatchJob、StreamingJob代码
四、DataFlow编程模型
1、概述:
Flink提供了不同级别的编程抽象
2、如何实现对分布式的数据进行流式计算和离线计算?
通过调用抽象的数据集调用算子构建DataFlow,就可以实现对分布式的数据进行流式计算和离线计算
3、DataSet与DataStream抽象数据集如何区分?
| DataSet: | 是批处理的抽象数据集 |
| DataStream: | 是流式计算的抽象数据集 |
说明:他们都有共同的方法
| Source | Transformation | Sink |
| 主要负责数据的读取 | 主要负责对数据的转换操作 | 负责最终计算好的结果数据输出 |















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









