







一、Flink简介介绍
Flink:框架和(分布式)引擎,对(有界和无界)数据流进行有状态(即存储中间结果)计算。
- 无界数据:有定义的开始,没有结束,必须持续处理,即摄取到数据立即处理
- 有界数据:有定义的开始,也有结束,摄取到所有数据后再计算,可以被排序,即无需有序摄取,通常称为批处理。
- 存储位置:
内存:速度快,可靠性差
分布式系统:速度慢,可靠性强
DataStream 批流统一处理
DataStream 批流统一处理,数据流的统一处理接口。流处理中有两种不同的流:
- 批处理,是将其数据当作有界(有定义开始,有定义结束)流处理,例如文本文件数据
- 流处理,是将其数据当作无界(无定义开始,无定义结束)流处理,例如实时数据
二、Flink集群的架构

三、Flink三种运行方式(与spark相似)
1、local 本地测试
2、Standallone Cluster 独立集群(做实时计算,不需要hadoop,该独立集群可能用的上)
3、Flink on Yarn 推荐
四、基础环境搭建
1、服务器资源配置准备
在文件/etc/hosts追加内容,配置映射地址,不使用虚拟映射直接使用ip也是可以
192.168.56.128 hadoop001
192.168.56.129 hadoop002
192.168.56.130 hadoop003实际的ip根据服务器资源修改
2、Java环境配置
将下载好的Java进行安装,在文件 /root/.bash_profile或/etc/profile后追加内容。
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HIOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
部署前提,最Flink新版本1.17要求java 11以上版本,1.12还可以使用java 8版本。根据版本自行选择对应版本JDK。;
注意:/root/.bash_profile表示系统环境(系统下所有用户生效)
/etc/profile表示用户环境(只有当前用户生效)
3、使环境变量生效
source /root/.bash_profile4、验证是否成功
java -version5、Flink上传、解压、配置环境变量
#进入压缩包所在目录
cd /usr/local/
#解压
tar -zxvf /usr/local/flink-1.17.0-bin-scala_2.12.tgz
#重命名
mv flink-1.17.0 flink
#配置环境变量
vi /root/.bash_profile
#添加
export FLINK_HOME=/usr/local/flink
export PATH=$PATH:$FLINK_HOME/bin
#刷新
source /root/.bash_profile6、防火墙设置
centos的防火墙要关闭,并确认是否关闭成功。
会用到的命令如下,
a. 查看防火墙状态:firewall-cmd --state
如果是not running状态,说明没有启动防火墙
b. 关闭防火墙:systemctl stop firewalld.service
c. 设置开机禁启:systemctl disable firewalld.service
========================
以下为常用防火墙命令
查看防火墙状态:firewall-cmd --state
查看防火墙版本:firewall-cmd --version
更多防火墙状态:systemctl status firewalld.service
开启防火墙:systemctl start firewalld.service
关闭防火墙:systemctl stop firewalld.service
重启防火墙:systemctl restart firewalld.service
设置开机自启:systemctl enable firewalld.service
设置开机禁启:systemctl disable firewalld.service
查看是否自启:systemctl is-enabled firewalld.service
查看自启列表:systemctl list-unit-files|grep enabled
————————————————
五、Local运行模式环境
1、设置放开权限
进入flink安装目录下的conf目录下修改flink-conf.yaml文件
修改rest.bind-address: localhost 为 rest.bind-address:0.0.0.0,这个非常关键,是为了能在任何地方,比如windows的浏览器上访问flink web ui。否则访问失败,如下图:

2、启动flink本地模式
local运行模式,主要用于测试,进入flink安装目录下,执行以下命令:
bin/start-cluster.sh3、访问web页面
访问 http://192.168.56.128:8081 或

六、Standallone Cluster 独立集群
1、设置放开权限
进入flink安装目录下的conf目录下修改flink-conf.yaml文件
修改rest.bind-address: localhost 为 rest.bind-address:0.0.0.0,这个非常关键,是为了能在任何地方,比如windows的浏览器上访问flink web ui。否则访问失败,如下图:
修改jobmanager.bind-host: localhost 为jobmanager.bind-host:0.0.0.0,放开flink的rpc通信权限,等心跳包发送到jobmanager则注册成功,否则Total Task Slots 等于0 Task Managers 等于0 此时若提交任务,直接报资源不可用,如下图:
2、指定主节点ip地址
vi /usr/local/flink/conf/flink-conf.yaml
# (修改)指定主节点ip地址
jobmanager.rpc.address: hadoop0013、指定从节点
指定从节点后,启动时候会自动在对应的从节点上启动TaskManager进程。
vi workers
# (修改)指定从节点
hadoop001
hadoop002
hadoop0034、指定主节点
指定主节点,则启动时候,JobManager进程在指定的主节点上启动。如果不指定,则在哪台机器上启动Flink,哪台机器就是主节点,即JobManager进程就在哪台机器上。
vi masters
# 改成主节点hadoop001
hadoop001:80815、启动flink 的Standallone Cluster模式
Standallone Cluster 独立集群(做实时计算,不需要hadoop,该独立集群可能用的上)
进入flink安装目 录下,执行以下命令:
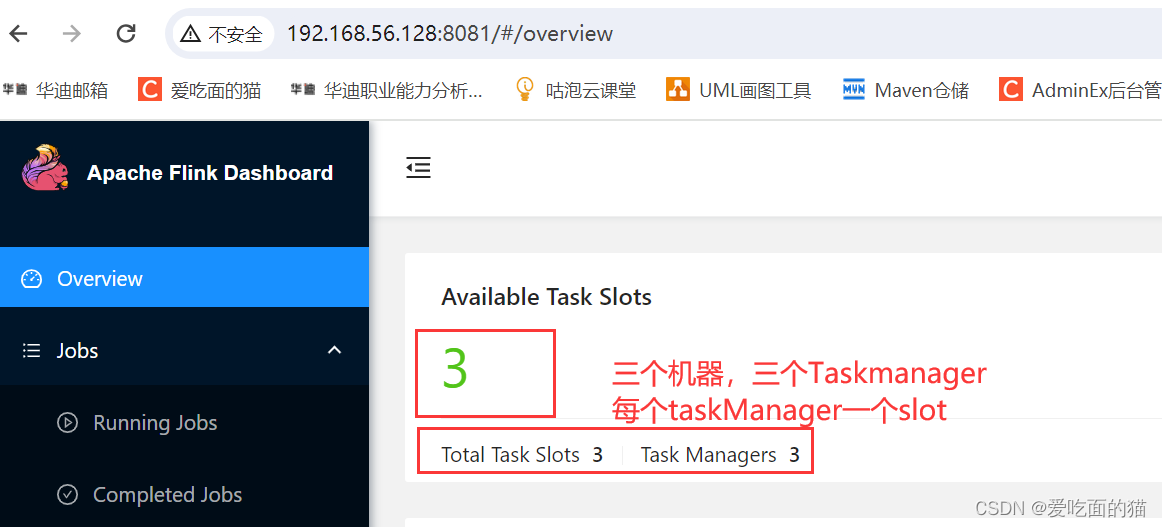
bin/start-cluster.sh6、访问web页面
访问 http://192.168.56.128:8081 或
七、Flink提交任务快速启动
1、Idea创建项目flink
2、添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3、编写代码
package com.hwadee.flink;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName$ FlinkBatchWordCount
* @Description 使用Flink编写一个批处理程序,实现单词统计功能
* <p>
* DataStream 批流统一处理,数据流的统一处理接口。
* 流处理中有两种不同的流:
* 批处理,是将其数据当作有界(有定义开始,有定义结束)流处理,例如文本文件数据
* 流处理,是将其数据当作无界(无定义开始,无定义结束)流处理,例如实时数据
*
* 实时数据: 打开集群,在某节点上进行 执行命令nc -lk 7777(指定未占用的端口号),输入内容作为实时数据
*
* 首先设置 idea中的参数配置
* program params 中 设置 --host 192.168.56.128 --port 7777
*/
public class FlinkRealTimeStreamWordCount03 {
public static void main(String[] args) throws Exception {
// 1、创建流处理执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
System.out.println("please wait for inpu data ...");
// 从参数中提取主机名和端口号
ParameterTool tool = ParameterTool.fromArgs(args);
String hostname = tool.get("host");
Integer port = tool.getInt("port");
// 2、 读取数据,创建数据源
DataStreamSource<String> source =
env.socketTextStream(hostname,port);
// 3、 对数据进行转换处理
SingleOutputStreamOperator<Tuple2<String, Long>> operator = source.flatMap(
(String line, Collector<Tuple2<String, Long>> out) -> {
// 将输入的文本进行分割
String[] words = line.split(" ");
// 将每个单词转换为 Tuple2输出
for (String word : words) {
if (word.contains(".")) {
out.collect(Tuple2.of(".", 1L));
}
out.collect(Tuple2.of(word, 1L));
}
}
).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4、 数据按key值分组
// 第一种方式已经弃用
// KeyedStream<Tuple2<String, Long>, Tuple> keyBy = operator.keyBy(0);
// 第二种方式推荐,使用 selector,同样使用 lambda表达式
// operator.keyBy(data -> {return data.f0;}); 只有一行代码,大括号和return 可以省略
KeyedStream<Tuple2<String, Long>, String> keyBy = operator.keyBy(data -> data.f0);
// 5、 进行数据聚合
SingleOutputStreamOperator<Tuple2<String, Long>> sum = keyBy.sum(1);
// 6、 输出结果
sum.print();
// 7. 执行
env.execute();
/**
* 结果说明
* Idea 使用多线程模拟分布式Flink集群 运行并行任务
* 前面数字代表线程号,在flink中是 slot ,即最小的单任务槽
* 输出顺序是因为集群运行并行任务。
* 注意 : 只有在同一个任务上才能进行叠加。如 hello 叠加都是在 线程14上执行的。
* 14> (hello,1)
* 17> (It,1)
* 10> (brain,,1)
* 14> (hello,2)
* 08> (Here,1)
* 14> (hello,3)
* 10> (Here,1)
*/
}
}
4、项目打包
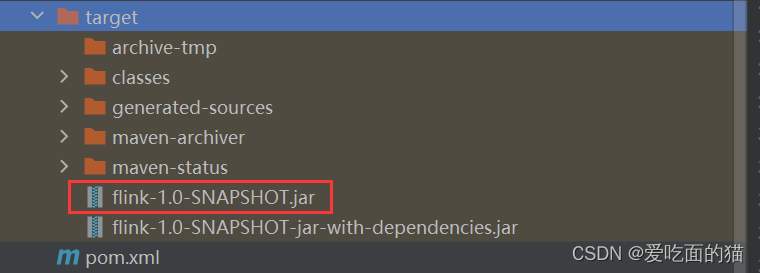
5、添加任务及参数
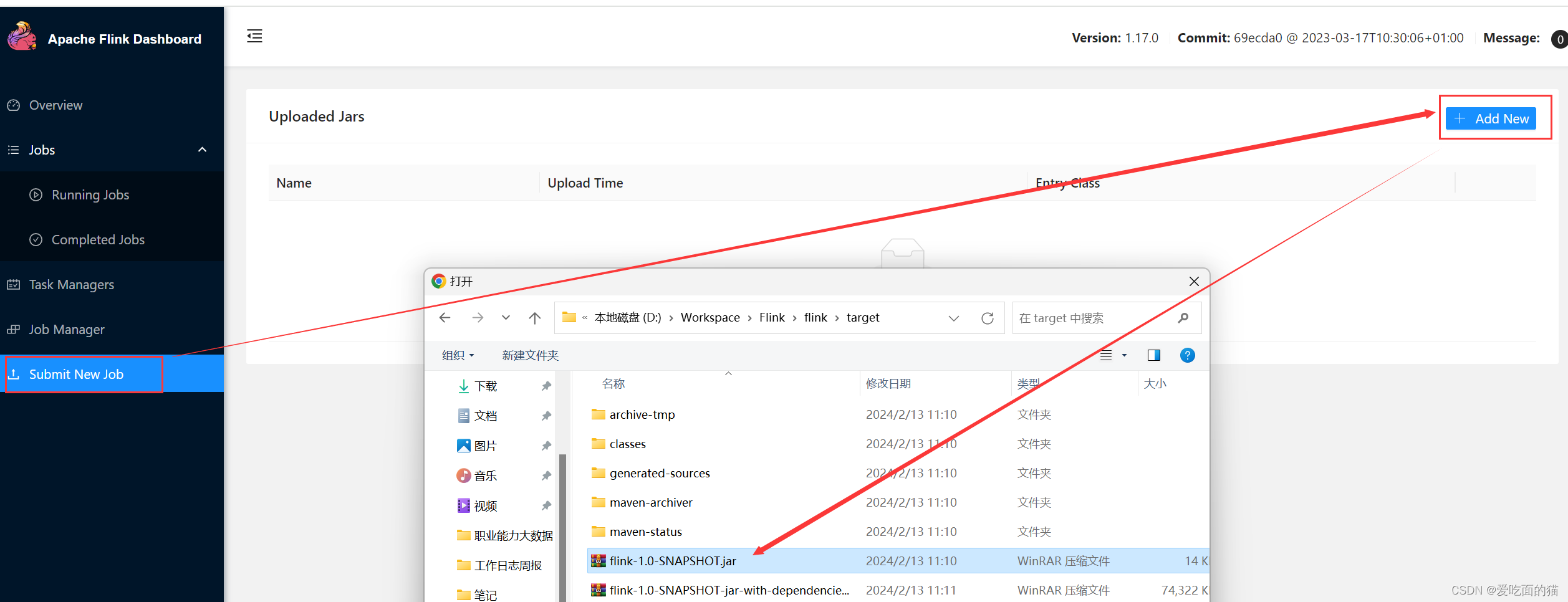
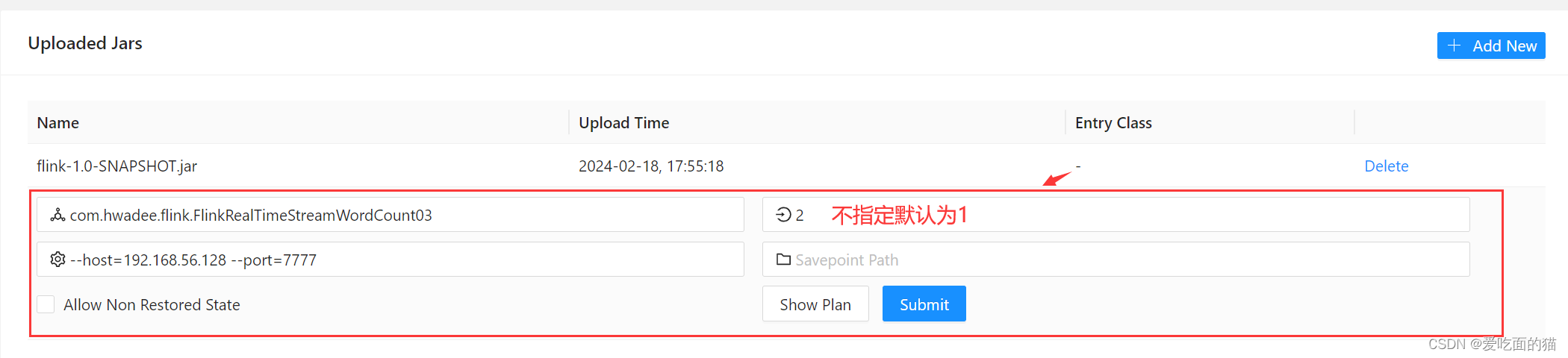















 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









