







Tensorflow已经成长为事实上的机器学习(ML)平台,在业界和研究领域都很流行。对Tensorflow的需求和支持促成了大量围绕训练和服务机器学习(ML)模型的OSS库、工具和框架。Tensorflow服务是一个构建在分布式生产环境中用于服务机器学习(ML)模型的推理方面的项目。
今天,我们将重点讨论通过优化预测服务器和客户机来提高延迟的技术。模型预测通常是“在线”操作(在关键的应用程序请求路径上),因此我们的主要优化目标是以尽可能低的延迟处理大量请求。
首先让我们快速概述一下Tensorflow服务。
什么是Tensorflow服务?
Tensorflow Serving提供灵活的服务器架构,旨在部署和服务机器学习(ML)模型。一旦模型被训练过并准备用于预测,Tensorflow服务就需要将模型导出为Servable兼容格式。
Servable是封装Tensorflow对象的中心抽象。例如,模型可以表示为一个或多个可服务对象。因此,Servables是客户机用来执行计算(如推理)的底层对象。可服务的大小很重要,因为较小的模型使用更少的内存、更少的存储空间,并且将具有更快的加载时间。Servables希望模型采用SavedModel格式,以便使用Predict API加载和服务。
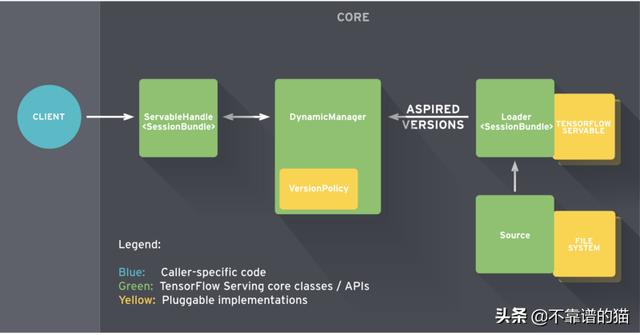
Tensorflow Serving将核心服务组件放在一起,构建一个gRPC/HTTP服务器,该服务器可以服务多个ML模型(或多个版本)、提供监视组件和可配置的体系结构。
Tensorflow服务与Docker
让我们使用标准Tensorflow服务(无CPU优化)获得基线预测性能延迟指标。
首先,从Tensorflow Docker hub中提取最新的服务镜像:
docker pull tensorflow/serving:latest出于本文的目的,所有容器都在4核15GB Ubuntu 16.04主机上运行。
将Tensorflow模型导出为SavedModel格式
使用Tensorflow训练模型时,输出可以保存为变量检查点(磁盘上的文件)。可以通过恢复模型检查点或其转换的冻结图(二进制)直接运行推理。
为了使用Tensorflow服务来提供这些模型,必须将冻结图导出为SavedModel格式。Tensorflow文档提供了以SavedModel格式导出训练模型的示例。
我们将使用深度残差网络(ResNet)模型,该模型可用于对ImageNet的1000个类的数据集进行分类。下载预训练的ResNet-50 v2模型(https://github.com/tensorflow/models/tree/master/official/resnet#pre-trained-model),特别是channels_last(NHWC) convolution SavedModel,它通常更适合CPU。
复制下列结构中的RestNet模型目录:
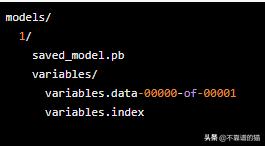
Tensorflow Serving期望模型采用数字排序的目录结构来管理模型版本控制。在这种情况下,目录1/对应于模型版本1,其中包含模型体系结构saved_model.pb以及模型权重(变量)的快照。
加载并提供SavedModel
以下命令在docker容器中启动Tensorflow服务模型服务器。为了加载SavedModel,需要将模型的主机目录挂载到预期的容器目录中。
docker run -d -p 9000:8500 -v $(pwd)/models:/models/resnet -e MODEL_NAME=resnet -t tensorflow/serving:latest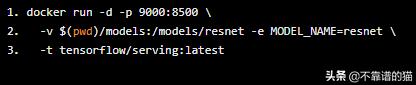
检查容器日志显示,ModelServer正在运行,准备在gRPC和HTTP端点上为resnet模型提供推理请求:
I tensorflow_serving/core/loader_harness.cc:86] Successfully loaded servable version {name: resnet version: 1}I tensorflow_serving/model_servers/server.cc:286] Running gRPC ModelServer at 0.0.0.0:8500 ... I tensorflow_serving/model_servers/server.cc:302] Exporting HTTP/REST API at:localhost:8501 ...
预测客户端
Tensorflow Serving将API服务模式定义为协议缓冲区(protobufs)。预测API的gRPC客户端实现打包为tensorflow_serving.apispython包。我们还需要tensorflowpython包来实现实用功能。
让
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









