





本文使用 Zhihu On VSCode 创作并发布
上一篇主要总结了linux进程的表示,以及fork、exec、exit等,本章主要关注调度器的实现。
调度器
Linux调度器根据实时调度和非实时调度分为两种调度器:实时调度器和CFS调度器,对应的进程称为实时进程和普通进程,绝大部分进程是普通进程
- 实时进程最有高优先权,总是会抢占普通进程先执行。
- CFS的实现只依赖进程的等待时间,即进程在就绪队列中已经等待了多长时间,对CPU时间需求最迫切的进程被调度执行。

所有可运行进程都在就绪队列中存放,内部实现是一个红黑树,进程按等待时间的长短进行排序,其中等待时间的计算会参考集成的类型(实时/普通)和优先级(nice),等待时间最长的进程在树的最左侧,调度器下一次将调度该进程,被调度执行的进程在执行前会先出队。
假如用fair_clock代表队列的虚拟时间,wait_runtime代表进程的等待时间,排序依据fair_clock-wait_runtime的值。fair_clock是队列的虚拟时间,会随着进程运行一直单调增加,如果进程运行了,那么进程的wait_runtime会减少,没运行则保持不变。
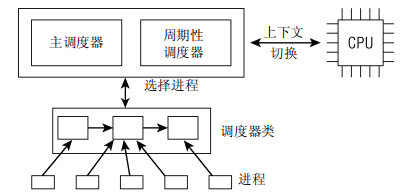
调度器由主调度器、周期性调度器、调度器类、就绪队列组成:
- 主调度器:进程主动发起调度,如sleep等
- 周期性调度器:根据HZ定时发起调度,更新各个调度队列、实体等数据
- 调度器类:实现不同的调度策略,调度器类是一个串联list(实时调度器类->CFS->IDLE)
- 就绪队列:每个cpu都有一个就绪队列,但只保存通用数据,实际的进程队列保存在上述各个调度器类中,每个调度器类包含各自的进程队列
进程task_struct包含指向调度器类的指针,并内嵌了调度实体的结构,调度器类表示该进程所属的调度器类,调度器调度的对象是调度实体(调度实体不仅可以是进程,也可以是其他,但这里只关注进程)。
<sched.h>
struct task_struct {
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
struct list_head run_list;
const struct sched_class *sched_class;
struct sched_entity se;
unsigned int policy;
cpumask_t cpus_allowed;
unsigned int time_slice;
...
}
调度器类需要实现以下方法,cfs和实时调度器类都实现了
<sched.h>
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep);
void (*yield_task) (struct rq *rq);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p);
struct task_struct * (*pick_next_task) (struct rq *rq);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p);
void (*task_new) (struct rq *rq, struct task_struct *p);
};
- enqueue_task, 添加一个新进程到就绪队列
- dequeue_task,从就绪队列中去除一个进程
- yield_task,放弃执行
- check_preempt_curr,唤醒一个新的进程并抢占执行
- pick_next_task,选择下一个进程
- put_prev_task,在切换进程前调用
- set_curr_task,调度策略变化是调用
- task_tick,周期性调度器调用,更新各个数据
- new_task,创建新进程后通知调度器
全局就绪队列
kernel/sched.c
struct rq {
unsigned long nr_running;
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
...
struct load_weight load;
struct cfs_rq cfs; // CFS就绪队列
struct rt_rq rt; // 实时就绪队列
struct task_struct *curr, *idle;
u64 clock; // 队列时间
...
};
CFS就绪队列
kernel/sched.c
struct cfs_rq {
struct load_weight load; // 队列权重
unsigned long nr_running; // 队列中可运行实体数量
u64 min_vruntime; // 队列最小虚拟时间
struct rb_root tasks_timeline; // 红黑树
struct rb_node *rb_leftmost; // 最左侧节点
struct sched_entity *curr; // 当前调度实体
}
正在运行的实体是不在就绪队列中的,但通过curr关联
调度实体
<sched.h>
struct sched_entity {
struct load_weight load; // 权重,根据调度类型(实时/普通)和nice计算
struct rb_node run_node;
unsigned int on_rq;
u64 exec_start; // 每次调度是更新为调度时间
u64 sum_exec_runtime; // 累计调度时间
u64 vruntime; // 虚拟运行时间
u64 prev_sum_exec_runtime;
...
}
将所有设计的结构体都放在这里方便理解cfs调度的逻辑(下面会讲)
权重计算
在linux内部优先级是从0到139
0~99是实时进程的优先级
100~139是普通进程的优先级,对应nice -20~19,其中nice 0是120,默认普通进程是nice 0
进程优先级会影响获得cpu执行时间,具体如下图所示:
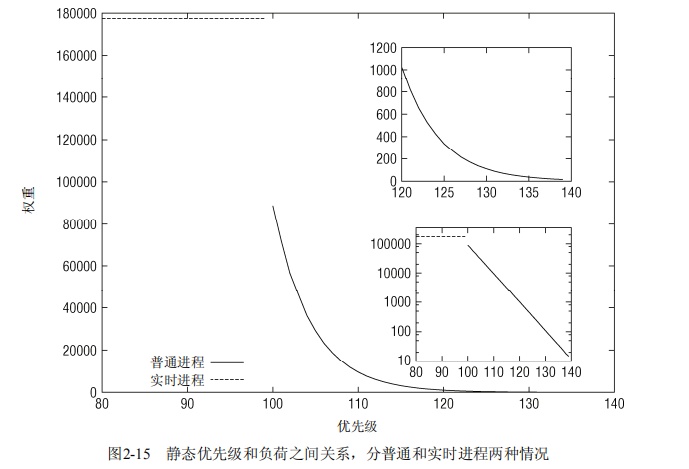
- nice每个优先级会影响10%的cpu时间分配
- 普通到实时进程间的临界点上是不连续的
虚拟时间vruntime计算
kernel/sched_fair.c
delta_exec_weighted = delta_exec;
if (unlikely(curr->load.weight != NICE_0_LOAD)) {
delta_exec_weighted = calc_delta_fair(delta_exec_weighted,
&curr->load);
}
curr->vruntime += delta_exec_weighted;
...
其中calc_delta_fair:delta_exec * nice 0的load / 进程实际load,越重要的进程会有越高的优先级(即,越低的nice值),会得到更大的权重,但作为分母,计算出累加的虚拟运行时间会小一些,这样就可以获得更多的cpu执行时间。
完全公平调度器的真正关键点是,红黑树的排序过程是根据下列键进行的:
kernel/sched_fair.c
static inline s64 entity_key(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
return se->vruntime - cfs_rq->min_vruntime;
}
键值较小的结点,排序位置就更靠左,因此会被更快地调度。用这种方法,内核实现了下面两种对立的机制:
- 在进程运行时,其vruntime稳定地增加,它在红黑树中总是向右移动的。因为越重要的进程vruntime增加越慢,因此它们向右移动的速度也越慢,这样其被调度的机会要大于次要进程,这刚好是我们需要的。
- 如果进程进入睡眠,则其vruntime保持不变。因为每个队列min_vruntime同时会增加,那么睡眠进程醒来后,在红黑树中的位置会更靠左,因为其键值变得更小了。
调度延迟
内核保证每个可运行进程至少在每个调度延迟周期内(默认20ms,如果进程多了会增加)可以运行一次,也就是每次的调度周期。
在每个调度延迟周期内,每个进程的cpu的时间分配逻辑是:
调度延迟周期时长 * 调度实体权重 / 就绪队列总权重
实时调度
实时进程与普通进程有一个根本的不同之处:如果系统中有一个实时进程且可运行,那么调度器 总是会选中它运行,除非有另一个优先级更高的实时进程。
现有的两种实时类:
- 循环进程(SCHED_RR)
- 先进先出进程(SCHED_FIFO)















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









