





Hello大家好,今天我们继续上篇文章,为大家分享一些Hive在工作中常用的聚合函数,分组函数,排序等等…………
我们就直接从聚合函数开始,什么是聚合函数呢,其实就是一句话,将多行合并为一行,就这么简单,常用到的聚合函数主要有一下几种:sum,count,max,min,avg等,其中注意的是count是对记录的统计,sum是对值的累加~
假设我们有一张员工薪资表(emp_table),现在要统计员工的最大,最小,平均工资和所有工资的和,代码如下:
hive> select max(salary),min(salary),avg(salary),sum(salary) from emp_table;查询记录记录数
hive> select count(*) from emp_table;hive> select count(1) from emp_table;-- 注意的是,上述俩种方式一样-- count() count(1) :这两种方式是一样的。接下来我们看看Hive中的几种排序方式
首先第一个排序是order by排序,order by会对输入的数据做全局的排序,所以只会有一个reduce,这样的话在大量的数据面前查询效率较低,费时较长
hive> select * from salary order by salary desc;-- desc 升序 asc降序另一个就是sort by排序,sort by排序不是全局排序,他在进入reduce阶段之前就已经排序,使用sort by排序可以设定reduce的数量
-- 启动两个reduceset mapred.reduce.tasks=2; 启动后执行sort by排序你就会发现reduce启动了2个
MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 6.07 sec HDFS Read: 11241 HDFS Write: 460 SUCCESSTotal MapReduce CPU Time Spent: 6 seconds 70 msec接下来是distribute by排序, distribute by通过计算一个列的值进行分区,有几个分区sort by就执行几次,也就会有多少个reduce
-- 通过 distribute by 对列计算值分区,然后查询排序select * from salary distribute by depart sort by salary asc;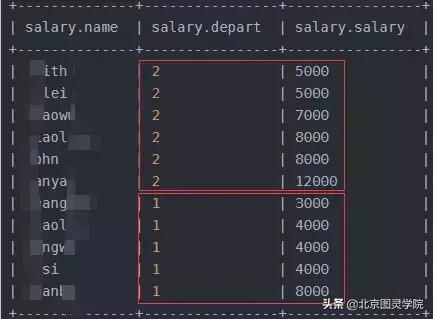
最后一个是cluster by聚集排序,就是distribute by + sort by的组合,但是只能默认升序,不支持自定义升序排序
hive> select * from salary cluster by salary;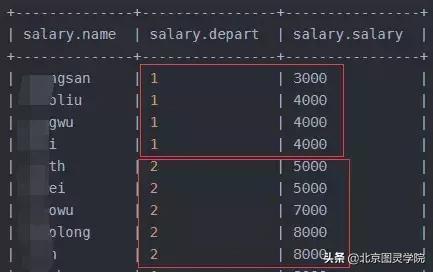
分组函数
在hive中我们使用group by方法对数据进行分组,hive有个特殊的嗜好,就是在group by分组的字段一定要出现在select的查询字段中,否则报错
接下来我们就对我们的员工表按照部门进行排序
hive> select depar from emp group by depar;--结果研发部市场部过控部……………………查询每个部门的平均薪资
hive> select depar,avg(salary) avg_sal from emp group by depar;研发部 15400.345234523423市场部 34243.423424过控部 34242.5454654654……………………-- 数据胡编乱造的查询平均薪资大于2000的部门
hive> select depar,avg(salary) from emp group by deptar having avg(salary) > 2000;按照部门和入职时间进行分组
hive> select depar,hiredate from emp group by depar,hiredate;按照部门和入职时间进行分组并计算出每组的人数
hive> select depar,hiredate,count(ename) from emp group by depar,hiredate;在hive分组中还有一个case when then end分组方式,该分组方式不会经过mr处理,示例如下:
查询员工的姓名和工资等级,按如下规则显示
salary小于等于1000,显示LOWER,
salary大于等于1000且小于等于2000,显示MIDDLE,
salary大于2000小于等于4000,显示HIGH
salary大于4000显示HIGHEST
select ename,salarycasewhen salary > 0 and salary <= 1000 then 'LOWER'when salary > 1000 and salary <= 2000 then 'MIDDLE'when salary > 20000 and salary <= 4000 then 'HIGH'ELSE 'HIGHEST'endfrom emp;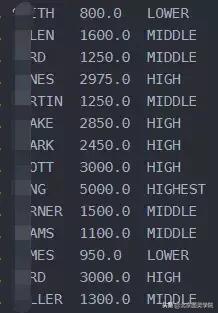
本片文章参考资料
https://blog.csdn.net/Realoyou/article/details/79189726https://blog.csdn.net/yu0_zhang0/article/details/79011192https://blog.csdn.net/doveyoung8/article/details/80022579http://www.cnblogs.com/lishouguang/p/4560837.htmlhttps://blog.csdn.net/qq_32941881/article/details/82347933强烈推荐:
https://www.iteblog.com/archives/2258.html#1UNIX_from_unixtime













 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









