







目录
- SVM原理
- 某些API解释
- SVM实现
- 作业问题记录
- SVM优化
- SVM运用
- 参考文献
一、SVM原理
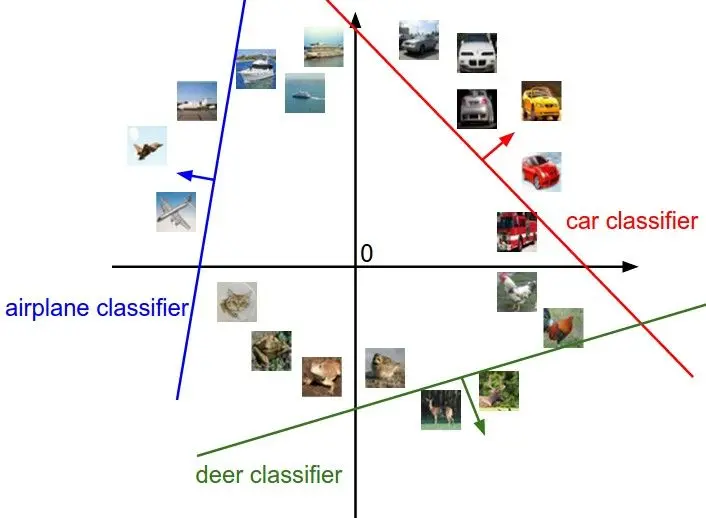
线性SVM分类是给每一个样本一个分数,其正确的分数应该比错误的分数大。在实际分类中,为了提高分类器的鲁棒性,我们希望正确的分数比错误的分数大得多一些,其差值为 ,如图1-1所示,我们希望car的所有样本离红线更远一些(箭头方向)。该损失函数则为Hinge损失函数,其公式如下:
,如图1-1所示,我们希望car的所有样本离红线更远一些(箭头方向)。该损失函数则为Hinge损失函数,其公式如下:


其中, 为第i个样本的损失函数,
为第i个样本的损失函数, 为第i个样本的错误分类标签的分数,
为第i个样本的错误分类标签的分数, 为第i个样本的正确分类标签的分数。在这里设为1。
为第i个样本的正确分类标签的分数。在这里设为1。
训练总体损失函数为:

为了防止过拟合,用一个正则化项来衡量一个模型的复杂度。因此,其训练总体损失函数为:
![L = \frac{1}{N}\sum_{i}^{N}L_{i} + \lambda R(W) =\frac{1}{N}\sum_{i}^{N}\sum_{j\neq y_{i}}[max(0,w_{j}^{T}x - w_{y_{j}}^{T}x + 1)] +\lambda \sum_{k}\sum_{l}W_{k,l}^{2}](https://i-blog.csdnimg.cn/blog_migrate/0cdd81a85445188bfbbc6519d0a933a9.png)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









