





半监督文本分类的对抗训练方法
题目:
Adversarial Training Methods for Semi-Supervised Text Classification
作者:
Takeru Miyato, Andrew M. Dai, Ian Goodfellow
来源:
Published as a conference paper at ICLR 2017
Machine Learning (cs.LG)
Submitted on 25 May 2016
文档链接:
arXiv:1605.07725
代码链接:
https://github.com/tensorflow/models/tree/master/research/adversarial_text
https://github.com/TobiasLee/Text-Classification
摘要
对抗性训练提供了一种正则化监督学习算法的方法,而虚拟对抗性训练能够将监督学习算法扩展到半监督设置。然而,这两种方法都需要对输入向量的大量条目进行小扰动,这对于稀疏的高维输入(如一个热词表示)是不合适的。我们将对抗性训练和虚拟对抗性训练扩展到文本领域,方法是将扰动应用于一个递归神经网络中的单词嵌入,而不是应用于原始输入本身。该方法在多个基准半监督和纯监督任务上均取得了较好的效果。我们提供了可视化和分析,表明学习的单词嵌入在质量上得到了提高,并且在训练时,模型不太容易过度拟合。
英文原文
Adversarial training provides a means of regularizing supervised learning algorithms while virtual adversarial training is able to extend supervised learning algorithms to the semi-supervised setting. However, both methods require making small perturbations to numerous entries of the input vector, which is inappropriate for sparse high-dimensional inputs such as one-hot word representations. We extend adversarial and virtual adversarial training to the text domain by applying perturbations to the word embeddings in a recurrent neural network rather than to the original input itself. The proposed method achieves state of the art results on multiple benchmark semi-supervised and purely supervised tasks. We provide visualizations and analysis showing that the learned word embeddings have improved in quality and that while training, the model is less prone to overfitting.
要点
我们的研究表明,Dai & Le(2015)提出的基于神经语言模型无监督预训练的方法,在多个半监督文本分类任务(包括情感分类和主题分类)上取得了最先进的性能。我们强调,只有一个额外的超参数ε的,最优化,即限制对抗性扰动大小的范数约束,实现了这种最先进的性能。这些结果强烈鼓励将我们提出的方法用于其他文本分类任务。我们认为文本分类是半监督学习的理想设置,因为有大量的未标记语料库可供半监督学习算法利用。这项工作是我们所知道的第一个使用对抗性和虚拟对抗性训练来改进文本或RNN模型的工作。通过对训练模型的分析,定性地描述了对抗训练和虚拟对抗训练的效果。我们发现,对抗性训练和虚拟对抗性训练在基本方法的基础上改进了单词嵌入。
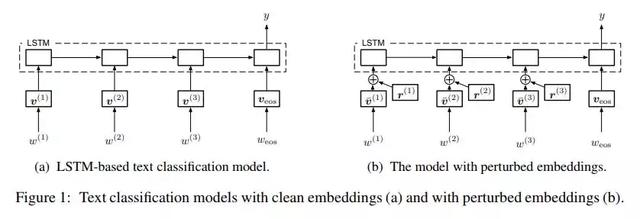
图1:使用干净的嵌入(a)和受干扰的嵌入(b)的文本分类模型。
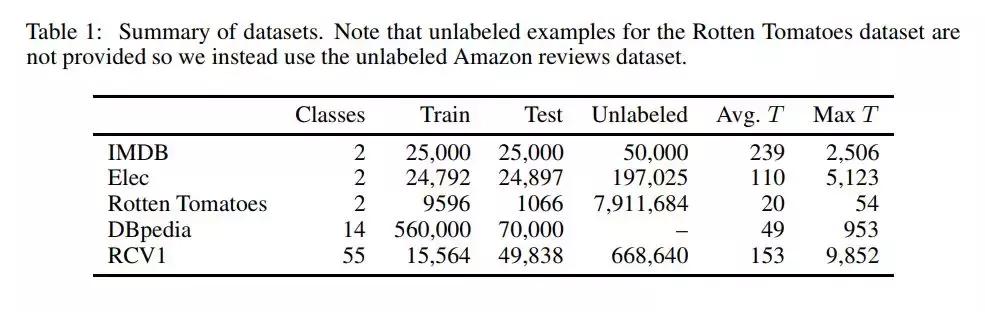
表1:数据集摘要。注意,没有提供Rotten Tomatoes数据集的未标记示例,因此我们使用未标记的Amazon评论数据集。
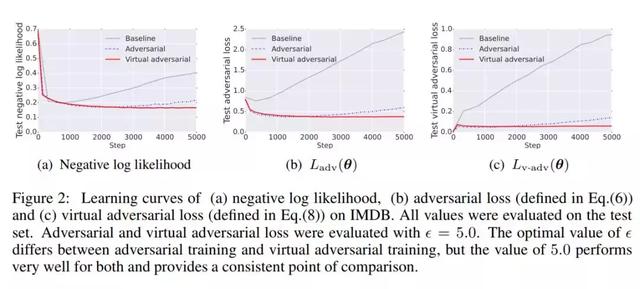
图2:学习曲线(a)的负对数似然,(b)对抗的损失(Eq。(6)中定义)和(c)虚拟对抗的损失(Eq。(8)中定义)在IMDB上。所有值对测试集进行评估。对抗和虚拟对抗的损失进行评估与ǫ= 5.0。ǫ不同的最优值之间的对抗训练和虚拟对抗训练,但5.0的价值表现都很好,并提供一个一致的观点。
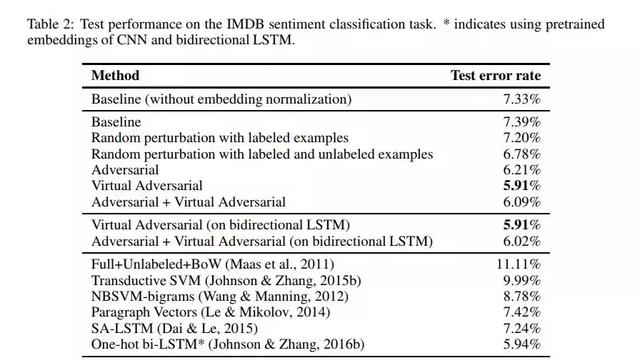
表2:IMDB情绪分类任务的测试性能。*表示使用预先训练好的CNN嵌入和双向LSTM。

表3:“好”和“坏”的10个最近邻,每个方法都训练了embeddings这个单词。我们用余弦距离表示度规。“基线”表示嵌入dropout的训练,“随机”表示带有标记示例的随机扰动训练。“对抗”,
“虚拟对抗性”是指对抗性训练和虚拟对抗性训练。
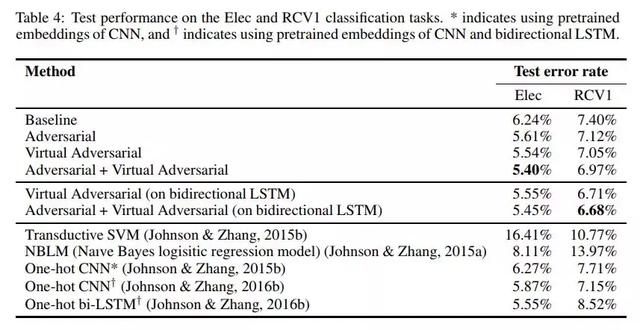
表4:测试Elec和RCV1分类任务的性能。*表示使用CNN的预训练嵌入,†表示使用CNN和双向LSTM的预训练嵌入。
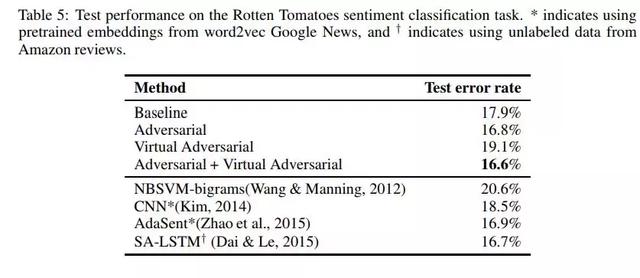
表5:Rotten Tomatoes情感分类任务测试成绩。*表示使用来自word2vec谷歌News的预训练嵌入,†表示使用来自word2vec谷歌News的未标记数据
亚马逊的评论。
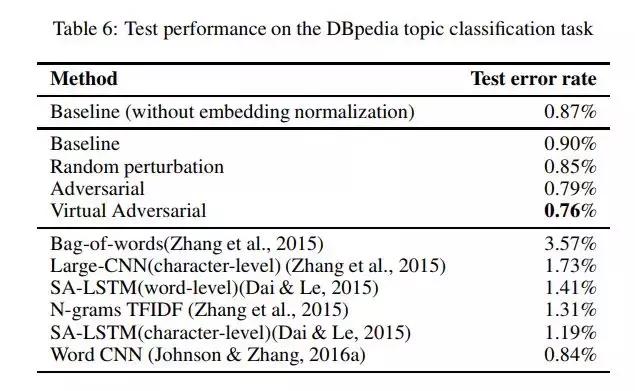
表6:测试DBpedia主题分类任务的性能















 3330
3330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









