







为了迎接618的到来,平台上新了数百台机器,其中,2021年上市的A5000,相对于更早发布的30系列,大家可能还不太熟悉,这边先放上某东618的价格截图,大家参考一下。

由于显存同为24G,也是采用了最新的安培架构,A5000自然免不了和3090的对比。
从一般的应用场景来看,3090属于消费级游戏显卡,而A5000是高端专业计算卡和图形卡,适用于AI、渲染、3D建模等具体场景。
而在深度学习领域,根据算法模型的差异,两者在实际表现中也各具优势,比如3090的单精度性能高于A5000,但在半精度和混合精度训练中,A5000的性价比又不输3090,甚至更为突出。
所以,这里不得不提及A5000的一些特点,比如,专业卡的配置更加兼容稳定;低功耗(230w)带来的出色效能;具备ECC(纠错码)可减少内存报错的困扰等。
为了方便大家对比和体验,GPUSHARE.COM针对A5000机型,上架了一系列618特惠活动,让大家能够低价、轻松地开启云GPU训练。
恒源云官网:gpushare.com https://gpushare.com/
https://gpushare.com/
一、A5000尝新特价!消费送券!
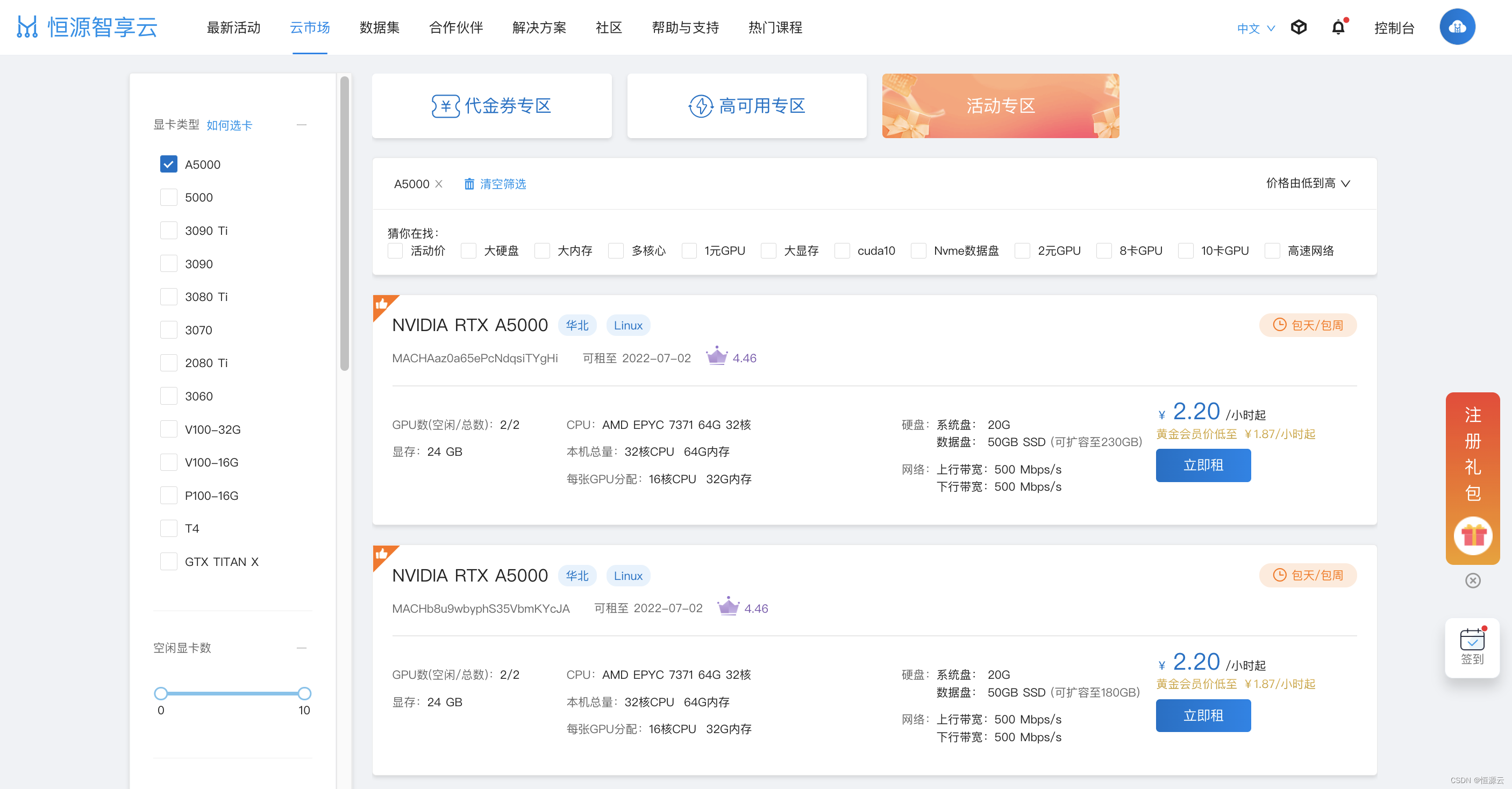
▼ 包天限时85折
6.9至6.30活动期间,平台A5000专享限时降价特惠,低价格、高可用、高配置,每张GPU分配16核CPU+32G内存,按量活动价2.2元/小时,黄金会员仅需1.87元/小时。
比按量更实惠的,当然是包天(24小时)/包周(7天)了,本次A5000活动,包天折扣限时降至85折,与包周折扣持平。
▼ 消费送券 · 高达60元
6.9至6.30活动期间,A5000订单消费累计(实际支付)达一定金额,用户可获得相应的代金券奖励。
二、送黄金会员最多3个月!
 上个月,平台首次尝试黄金会员抽奖,拿出了10个免费名额,参与用户人数超出预期,对此,GPUSHARE.COM坚持算力普惠和平等的理念,让更多用户享受黄金会员的折扣和权益,这次618特别准备了大量免费名额。
上个月,平台首次尝试黄金会员抽奖,拿出了10个免费名额,参与用户人数超出预期,对此,GPUSHARE.COM坚持算力普惠和平等的理念,让更多用户享受黄金会员的折扣和权益,这次618特别准备了大量免费名额。
凡是符合以下任一条件的用户,即可获得1个月的免费黄金会员,权益与正式会员无异,同时,以下福利并不互斥,意味着,参与用户最多可获得 3个月黄金会员。
▼ 老用户回馈 · 送1个月黄金会员
6.9 18:00 左右,凡是在平台充值过的老用户(充值金额大于0元即可),已收到系统自动发放的1个月黄金会员。
▼ 学生福利 · 送1个月黄金会员
凡是6月(6.1-6.30)提交并通过学生认证的用户,充值晋升为青铜(学生充值50元即享)及以上等级,可联系客服领取1个月黄金会员,登记当天立刻发放,6.30截止领取。
▼ A5000包周 · 送1个月黄金会员
6.9至6.30活动期间,凡是包周A5000机器的用户,可联系客服领取1个月黄金会员,登记当天立刻发放,6.30截止领取。
三、618充值返券更多!
▼ 充值返代金券+优惠券 · 大升级
6.9至6.18活动期间,充值返代金券数量升级(可直接消费代金券专区机器),同时,还将发放同等金额的优惠券(适用于包天/周/月订单满减),仅限10天,结束后恢复至日常。
—— 我是6月活动说明 ——
· 以上活动内容,并不互斥,大家可同时参与
· 平台禁止刷券行为,一旦发现,礼券作无效处理,严重者将被封号,请大家友善参与平台活动
· 本次活动,解释权归恒源云所有,关于活动的福利领取、疑问咨询等,可以联系客服

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









