







使用过ArrayList的小伙伴们都知道ArrayList实现了java.util.List接口,间接的实现了java.util.Collection接口,是我们日常开发过程使用频繁的有序数据集合。在java中还提供了一些其他的有序数据集合,今天的主角就是其中的LinkedList集合。
小伙伴们有没有想过,有了ArrayList,为什么还需要LinkedList?
要想回答这个问题,就需要知道ArrayList和LinkedList的本质区别,例如数据结构的区别、操作的区别。
在之前关于ArrayList的文章中,通过源码可以得知ArrayList内部使用静态数组存储数据元素,当容量不足时,会使用新的容量初始化一个数组,然后把原来数组中保存的元素拷贝到新的数组中。
画外音:数组在内存中是连续的一块区域。
通过这些描述,可以推断出ArrayList在使用时的局限:
ArrayList的内存是连续的,如果不满足可能会导致ArrayList初始化失败;
ArrayList中的数据插入、删除操作频繁时,可能会频繁的进行数据拷贝、数组初始化,影响效率。
这些ArrayList的局限在LinkedList中都得到了解决,先从宏观上看下LinkedList与ArrayList的不同:
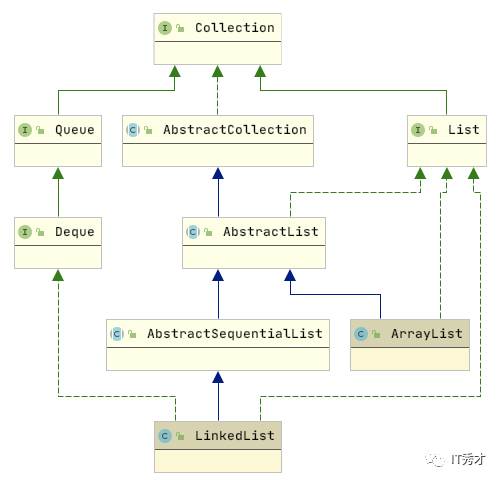
从上图中可以大致了解到LinkedList除了实现java.util.List接口,还实现了java.util.Queue和java.util.Deque两个接口,这两个接口的作用是:
java.util.Queue : 队列,在队尾添加元素,在队头读取元素,可以看作是单向链表;
java.util.Deque : 双向队列,可以在队尾、对头进行添加、读取的操作,可以看作是双向链表。
换言之,LinkedList内部就不是使用数组存储数据,而是使用队列的形式存储数据元素,而队列中每一个数据元素都是队列中的一个节点,即Node。
在下文中,通过源码介绍:
Node节点的数据结构
LinkedList的内部结构
与ArrayList操作对比
节点(Node)数据结构
秀才不多说,直接让源码来说:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable{ // prev code ...... /** * LinkedList的内部静态类 * @param */ private static class Node<E> { E item; // 当前节点的元素 Node next; // 当前节点的后一个节点 Node prev; // 当前节点的前一个节点 /** * 使用特定参数,构造一个Node节点 * @param prev * @param element * @param next */ Node(Node prev, E element, Node next) { this.item = element; this.next = next; this.prev = prev; } } // last code ......}通过以上源码可以得知:Node节点除了存储数据本身,还会使用两个引用来明确自己所处的位置。
这也表明LinkedList是一个双向链表,从某一个Node节点触发可以访问到其前一个节点,也可以访问到其后一个节点。
LinkedList的内部结构
想要知道LinkedList的内部结构,就需要查看下LinkedList中维护了哪些成员属性,直接让源码告诉你:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable{ // LinkedList中实际存储元素的个数 transient int size = 0; /** * Pointer to first node. * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) * 指向LinkedList中第一个元素的引用 */ transient Node first; /** * Pointer to last node. * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) * 指向LinkedList中最后一个元素的引用 */ transient Node last; /** * Constructs an empty list. * 构造一个空的LinkedList集合 */ public LinkedList() { } /** * Constructs a list containing the elements of the specified * collection, in the order they are returned by the collection's * iterator. * * @param c the collection whose elements are to be placed into this list * @throws NullPointerException if the specified collection is null * * 使用特定的Collection集合构造LinkedList,并且把特定的Collection中数据添加到LinkedList中 */ public LinkedList(Collection extends E> c) { this(); addAll(c); } // other code ...... }看完源码所说的这些,就可以得知:LinkedList中使用Node节点本身来保证元素存储的顺序,并且分别记录了第一个节点和最后一个节点的引用。
其内部结构的理解,可以用下图进行表示:
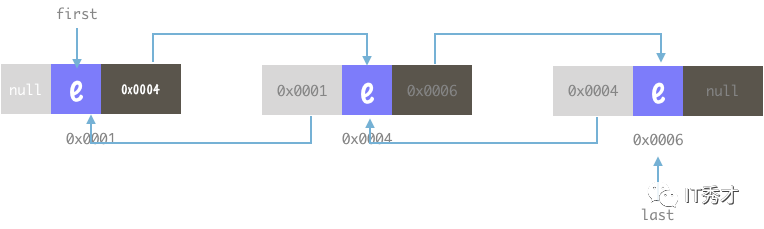
结合上图,可以总结得到:
LinkedList中的元素在内存中的分布可以是不连续的;
可以从first向后遍历,也可以从last向前遍历。
与ArrayList操作对比
现在基本明确了LinkedList对内存的要求比ArrayList要小一些,在进行插入、删除操作时的优越性又是怎么表现的呢?
以指定位置插入元素为例:
ArrayList向指定位置插入元素的api方法是:add(int index, E element);
LinkedList向指定位置插入元素的api方法是:add(int index, E element);
直接让源码来说:
ArrayList#add(int index, E element)
/** * Inserts the specified element at the specified position in this * list. Shifts the element currently at that position (if any) and * any subsequent elements to the right (adds one to their indices). * * @param index index at which the specified element is to be inserted * @param element element to be inserted * @throws IndexOutOfBoundsException {@inheritDoc} */ public void add(int index, E element) { // 检查指定的索引值,如果小于0 ,或大于当前数组的size值,则抛出异常 rangeCheckForAdd(index); // 数组扩容操作 ensureCapacityInternal(size + 1); // Increments modCount!! // 把elementData数组中指定位置后面的所有元素向后移动一位 // 第一个参数:源数组 // 第二个参数:源数组中移动的起始索引值 // 第三个参数:目标数组 // 第四个参数:目标数据中的起始索引值 // 第五个参数:源数组中移动的元素个数 System.arraycopy(elementData, index, elementData, index + 1, size - index); // 把目标元素添加到elementData数组的指定位置 elementData[index] = element; // 更新当前ArrayList的元素数量 size++; }ArrayList在进行指定位置插入元素的操作时,影响效率的有两个操作:
自动扩容操作;
内部元素的移动操作。
LinkedList#add(int index, E element)
/** * Inserts the specified element at the specified position in this list. * Shifts the element currently at that position (if any) and any * subsequent elements to the right (adds one to their indices). * * @param index index at which the specified element is to be inserted * @param element element to be inserted * @throws IndexOutOfBoundsException {@inheritDoc} */ public void add(int index, E element) { // 检查目标索引值,是否存在下表越界的情况 checkPositionIndex(index); if (index == size) // 在LinkedList最后位置插入元素 linkLast(element); else // 通过node(int index ) 方法检索到目标索引位置的node节点 // 在目标索引节点之前插入当前元素 linkBefore(element, node(index)); } /** * Returns the (non-null) Node at the specified element index. */ Nodenode(int index) { // assert isElementIndex(index); // 判断目标索引值在前半部分,还是在后半部分 if (index < (size >> 1)) { // 前半部分的情况 Node x = first; // 从第一个节点开始遍历,直到目标索引位置 for (int i = 0; i < index; i++) x = x.next; return x; } else { // 后半部分的情况 Node x = last; // 从最后一个节点开始遍历,直到目标索引位置 for (int i = size - 1; i > index; i--) x = x.prev; return x; } } /** * Links e as last element. * 在最后位置插入元素 */ void linkLast(E e) { final Node l = last; // 暂存原来的最后一个节点 final Node newNode = new Node<>(l, e, null); last = newNode; // 更新当前LinkedList的最后一个节点 if (l == null) // 原来最后一个节点为null,说明在插入目标元素之前LinkedList是空的 // 当前LinkedList只存在目标元素的节点,即是第一个,也是最后一个 first = newNode; else // 更新前一个节点与目标节点的关联 l.next = newNode; // 当前LinkedList元素数量更新 size++; // 结构变化次数更新 modCount++; } /** * Inserts element e before non-null Node succ. * 在非空Node节点之前插入目标元素 */ void linkBefore(E e, Node succ) { // assert succ != null; // 获取非空节点的前一个节点 final Node pred = succ.prev; final Node newNode = new Node<>(pred, e, succ); // 建立非空节点与新节点的关联 newNode succ.prev = newNode; if (pred == null) // 前一个节点为空,说明非空节点是first节点,现在更新为newNode节点为first节点 first = newNode; else // 前一节点存在,则建立前一个节点与新节点的关联 pred --> new Node pred.next = newNode; // 执行完成之后的情况是:pred --> newNode --> succ // 更新元素数量 size++; // 更新结构变化次数 modCount++; }LinkedList进行指定位置插入操作时,影响效率的是找到目标索引位置的Node节点,然后修改前后节点的引用。
综合来看在进行指定位置插入操作时,可以延伸到对结构发生变更的操作,LinkedList的效率是优于ArrayList。
但各位小伙伴需要注意的是,ArrayList在根据索引进行读取元素时的效率要优于LinkedList。
怕,你就输了;只要不放弃,你也可以让源码说话。














 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









