






0. 前言
最近做属性抽取,并且基于多模态信息(文本+图片)那种,然后发现了一个比较经典的论文“Multimodal Attribute Extraction”。正好就顺着这个论文的思路,捋一下这个任务,复现一下,再记录一下实践过程和想法
论文在 2017 年,提出了这么一个做多模态任务的框架,在现在来看感觉还挺经典的,虽然具体方法放到今天来看平平无奇,没什么高端操作,比不起现在的论文里各种眼花缭乱一通乱秀。但是出发总要从原点开始,中间有些想法和总结,有点什么就记点什么
(NIPS 2017) Multimodal Attribute Extractionarxiv.org1. 问题描述
什么是属性抽取:现实世界的任何事物,都要靠若干属性来修饰和描述,比如你买了一个肉夹馍,它的“肉料”是“牛肉”还是“猪肉”,它的“口味”是“麻辣”还是“不辣”,都需要被描述清楚,你才能做出决定想不想吃,要不要买
那到哪去获取这些“属性描述”呢?你可以看看菜单上写没写,也可以直接问老板,简单直接,但是这些“原始数据”不总是完美的。万一老板今天心情不好,不乐意跟你说话,怎么办。你就需要靠自己。你往冷柜一看,上面写着是“牛肉”的,再往调料盘一看,没有辣椒粉的罐子,就推理出应该是“不辣”的。挺好,开心地点了一个吃,做了一次成功的“属性抽取”,被自己的机智所折服
但是也有可能,你吃着发现,是辣的,吐了。原来老板把辣椒粉装在别的罐子里了。这个故事告诉我们,“属性抽取”也是有风险的,因为原始数据也是有噪声的
怎么做属性抽取:两种方式,“抽取式”和“生成式”。直接上图
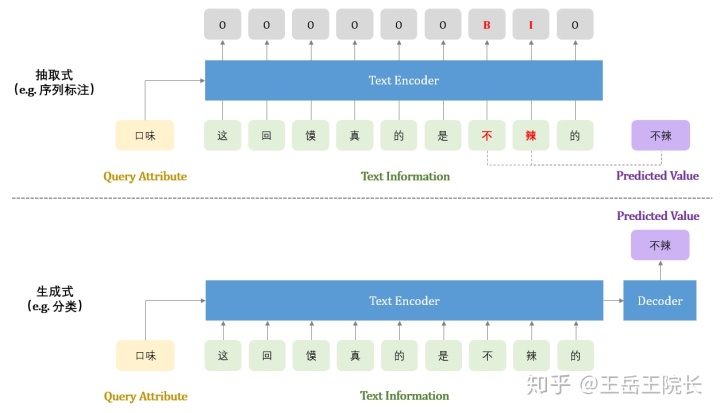
抽取式:就是抽取输入文本中的字词,组成预测的属性值。也就是说,预测出的属性值一定要在输入侧出现过
实现上,可以用上图所示的序列标注的方式,也可以做成类似 SQuAD 那种的 QA 问题,把属性作为 query,把属性值作为 answer,最终输出两个 index,取原文中两个 index 之间的字词作为属性值
另外,用序列标注的方式做的话,也有不同的实现方式,比如不把待预测的属性名(Query Attribute)作为输入,而是作为输出。也就是说,不告诉模型想预测哪个属性,模型你觉得你能预测到哪个属性就输出哪个属性。这种实现方式也包括几种,比如可以做成一个多任务学习,一个子任务做分类预测属性名,一个子任务做序列标注标记属性值;也可以只做一个序列标注任务,属性名靠标签本身标记,例如把原本的“B”标签扩展成“B-口味”“B-肉料”等多个标签,每个标签对应一种属性。五花八门,百川入海,殊途同归。各种方式都有人做,具体文章不一一列举了
列一个最近看到抽取式方法的论文吧,方法非常简单明了,一眼就懂
Scaling Up Open Tagging from Tens to Thousands: Comprehension Empowered Attribute Value Extraction from Product Title. ACL2019
生成式:就是直接生成属性值,而这个属性值不一定在输入文本中出现,只要模型在训练数据中见过就 ok
实现上,可以直接在一个“大而完整的属性词表”上做分类任务,也可以用 seq2seq 的方式把属性值分割成字词序列输出。但是无论如何,都是需要一个“大而完整的属性词表”,也就是属性值一定是可枚举可穷尽的。代表论文就比如最开始提到的那篇
两种方式优缺点比较:
抽取式
- 只能抽取在输入文本中出现过的属性值,导致很多属性不可做
- 预测属性值一定在输入中出现过,具有一定可解释性,准确性也更高,不会乱预测
生成式
- 只能预测可枚举的高频属性,导致很多属性值不可做
- 预测出来的属性值没有可解释性,在实际业务中,预测出来结果也不一定敢用(比如模型预测出来这个肉夹馍用的是牛肉,但是你也不一定敢信,又看不出来,万一是假的)
当然也可以融各自所长,做一个既能抽取又能生成的模型:比如基于 CopyNet 或者 Pointer-Generator,针对不同的输入情况,可以自由在“抽取模式”和“生成模式”之间进行切换。感觉听上去还比较高级吧,相关文章没看到过,感兴趣可以试一下,一条光明的小道指给你们了,还没毕业的可以拿去发论文哈,不用客气
背景故事就讲这些吧。下面就是具体的模型和实践过程
代码地址
- 数据集:MAE-dataset https://rloganiv.github.io/mae/
- 环境:Python3.6, Tensorflow 1.12
- 代码:

原始数据文件太大了,包括文本信息与图片文件,需要的话可以自己下载,把下好的数据解压到 data/origin/train 以及 data/origin/test 目录下,然后通过 data/process_data.py 把数据处理后生成到 data/train 和 data/test 下即可
但是出于客户为先的服务态度,我随机 sample 了一些数据留在了 data/train 以及 data/test 目录下,不用费力去下载原始数据就能跑 demo,就是为了给你们那种 git clone 完就能原地起飞的畅爽体验
不用客气

2. 模型及实现
先讲模型,最后说数据处理
模型很简单小巧,看图,一眼就懂
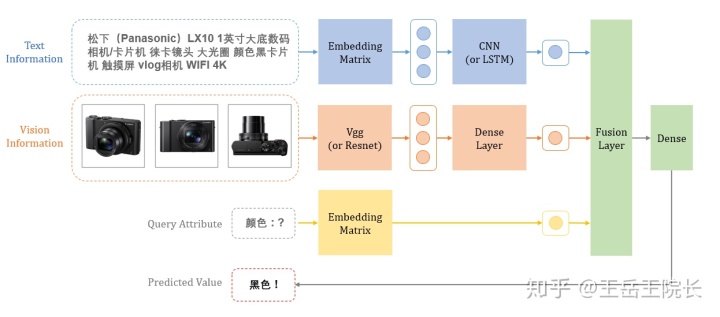
用 CNN 得到文本的编码向量;用预训练的 VGG 提取图片的特征向量,作为输入,然后接一层全连接层将得到图片的编码向量;直接用 Embedding 矩阵编码待预测属性;最后用一个融合层(Fusion Layer)将以上三个向量融合在一起,再接一层全连接,就得到预测的属性值了
然后上代码,先说输入
self这里就提一下 inputs_image,这个是输入的图片信息,每个商品最多 3 张图片,每张图片被VGG 预先提取为一个 4096 维(img_embedding_size=4096)的特征向量,具体提取方法后面数据处理部分再说
接下来就是按照图上的结构搭模型
with 这里说下这个多模态融合层(Fusion Layer)。相比单独的 NLP 任务或者 CV 任务,多模态任务也没什么特别的地方,无非是多了一项输入。所以,它的亮点就在于,多模态信息之间如何进行“交互”。把它俩“交”好了,让人眼前一亮,就能让人觉得你这个新颖、高级、给力
现在常用的交互方式有很多,比如(1)直接 concat 然后接一层全连接(2)二者之间做一层 Attention(3)类似 VL-BERT 那种,把文本输入和图片输入前后拼接在一起,通过 Transformer 去学他们之间的关系,本质上还是学 Attention,等等的
这篇论文里还提供了一种方式:gated multimodal unit(gmu),如代码中所示。这个 gmu 还挺有意思的。商品的有些属性可以通过图片看出来(比如颜色),而有些属性不行,必须要从文字中读出来(比如内存大小),这个 gmu 就是基于 gate 机制,让模型自己去学,什么时候看图,什么时候读字。实现上也比较简单,看图就懂
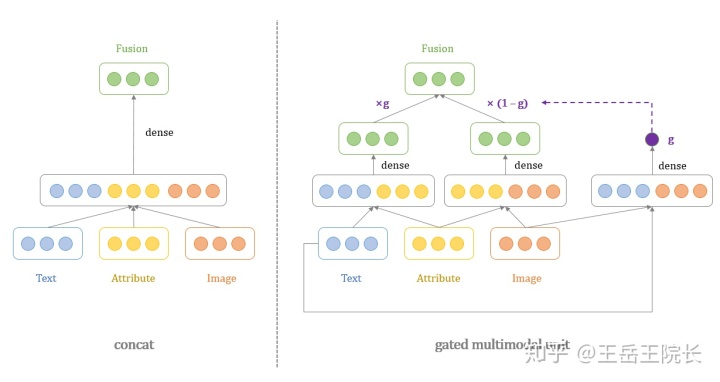
这种 gate 机制听上去就很高级。但是就这个数据集上而言,实际效果远不如直接 concat。任凭你花里胡哨,不如我简单粗暴
还有一些其他的交互方式,比如我们最近在做的一种,展示效果还是挺炫的。本质上还是计算 Attention,但不是把图片整个压缩成一整个向量,而是分成不同区域,保留每个区域的表征向量,这样在文本中提到某个属性时,可以观察模型是否可以在图片上找到这个属性对应的区域。比如下图里,文本里提到“小翻领”,模型就更加关注图片上衣领那块区域。分享一下图一乐,具体细节不细讲跑题了

Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product. Zhu T, Wang Y, Li H, et al. EMNLP 2020. https:// arxiv.org/pdf/2009.0716 2
接下来是 loss。loss 本身没啥可讲的,但是这里还有点意思。这篇论文用的是基于“余弦相似度”的 loss,一般常用的是“交叉熵”loss。两者公式不一样,但是出发点都是相同的,感觉应该没什么区别。但是从实验结果来看,有时候 loss 的影响可太大了
先上两种方式的实现代码
# D 是 predicted value 的向量维度
distribute_matrix 是一个 D * V 的矩阵,放在余弦相似度那里,可以理解成把词表中每个 value 做成一个 D 维的向量,储存在整个矩阵中,然后逐个去跟预测出的 value vector 计算相似度,看哪个相似度最高就选哪个;放在交叉熵那里,可以理解成一个 dense 层,把预测出的 value vector 映射到 V 维的概率分布上,每一维对应词表中一个 value 的概率
交叉熵这里是手写的,便于理解,实际应用中可以直接换成 tf 现成的函数 sparse_softmax_cross_entropy_with_logits,效果要好一些,里面做了很多优化的
这里为啥要提一下这个 loss 呢,因为两种 loss 感觉上出发点都是一样的,都是提高正例上的相似度或概率,打压负例,应该区别不大。论文里是每条数据只采样一个负例,听上去不太合理,我试了一下效果也不好,然后就把所有的负例 loss 都算进来(reduce_sum那里)。但是实验结果显示,交叉熵要好太多了,学习速度也不是一个量级的
至于啥原因,很难讲,可能是机器玄学吧。有可能是交叉熵这种 y*log(p) 的形式本身非常适合分类任务,也可能是计算交叉熵前的 softmax 非常适合反向传播。我乱猜的。有机会请交叉熵喝酒让他亲自给我唠一唠
单方面宣布交叉熵是 loss 届的王,万物皆可交叉熵

最后上一下实验结果对比,直接引用论文里的表了。单用图片的话(Image Baseline),效果还比不上直接写规则(Most-Common Value)。文字+图片的话(Multimodal Baseline)效果会比单用文字(Text Baseline)好一点点点点。说明核心还是文字,图片只是配角

由此出发再多说一句,不了解啊,瞎猜,是不是现在有很多的多模态任务,把图片或者视频或者语音的信息引入之后,效果上并没有什么明显提升,其实都是表面光鲜的配角
但是高级就完事了。秀就完事了
3. 数据预处理
关于数据怎么预处理,都可以从代码里找到,感兴趣的话看一眼代码就可以
这里主要提一下怎么对图片进行预处理。现在一般多模态任务都会先用一个预训练模型把图片提取为特征向量吧,如果把原始图片作为输入的话,模型还要另外搭好多层 CNN 去学习图片特征提取,对模型来说压力太大了。预训练模型可以用 VGG 或者 Resnet 或者其他的,可以直接把一张图片直接压缩成一个 D 维向量,也可以把图片分割为 Nx * Ny 块,输出形状为(Nx * Ny * D)的结果
具体实现方式我没有找到 tensorflow 版本的,就用的 pytorch 官方提供的接口torchvision.models,网上可以直接搜到教程就不细说了。运行代码时会自动下载预训练好的模型,如果下载较慢可以本地下好然后传到它的默认下载目录下,一般是 ~/.torch/models 这种目录,具体路径可以看输出提示
然后假设一共有 N 张图片,分别用预训练模型跑一边得到一个 N*D 的矩阵,储存下来。然后训练的时候,按照每条输入数据对应的 image index 去矩阵中取,比如第一个商品有 3 张图片,分别是第 1,3,128 号图片,就去从这个矩阵中抽
大家如果平时在预处理或者训练过程中,有更科学的数据处理方式,非常欢迎指导交流,普渡众生,善莫大焉,独乐乐不如众乐乐

就这样,打完收工















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









