







一、Non-local
原文链接:Non-local Neural Networks | IEEE Conference Publication | IEEE Xplore
1.公式
其中。
的形式可以不同,如
(1)Gaussian:
(2)Embedded Gaussian:
自注意力(self-attention)是non-local在Embedded Gaussian中的特例。因为
就是对给定的
,沿着维度
作softmax操作。
(3)点积(embedded):
(4)拼接:
其中表示拼接操作;
是将拼接后的向量转换为标量的权重向量。
2.Non-local块
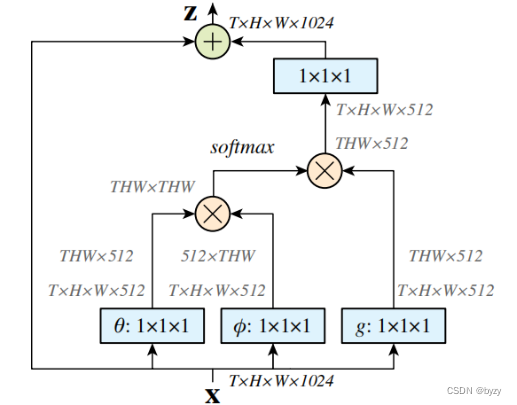
上图为Non-local(embedded Gaussian)的结构。图中蓝色方块为卷积;
和
分别表示矩阵加法和矩阵乘法。1024和512代表通道数。softmax操作是对每一行做的。
如果去掉上图中的
和
,就变为Gaussian结构;将softmax操作替换为乘以
,就变为点积结构。
实际实施时,不改变性能,但减小计算量的方法:在和
后加入最大池化层。
二、Criss-Cross
原文链接:CCNet: Criss-Cross Attention for Semantic Segmentation | IEEE Conference Publication | IEEE Xplore
网络结构: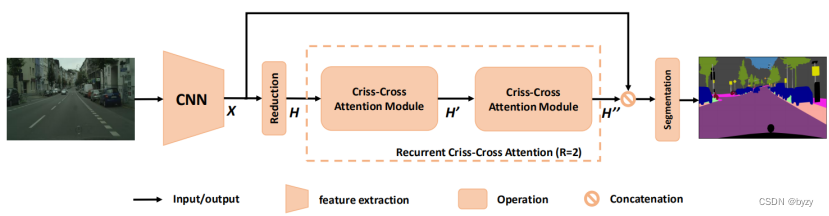
1.Criss-Cross模块结构
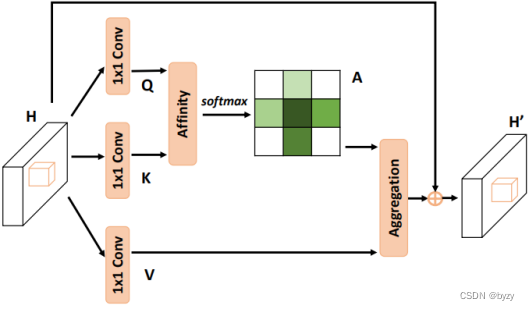
图中softmax在通道维度做。
2.Affinity操作
对于中每个位置
,可以得到其特征
;同时可以得到
中对应位置所在行和列的所有向量集合
。设
为
的第
个元素,则Affinity操作定义为
记为Affinity操作的输出矩阵(或
在softmax前的矩阵;其位置
处的第
个元素为
),则
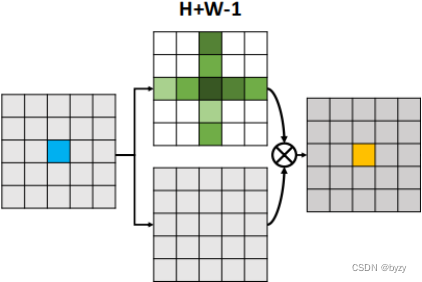
上图中,左边的矩阵为,上边的矩阵为
,下边的矩阵为
,右边的矩阵为
;
表示Affinity操作。
3.Aggregation操作
对于中每个位置
,可以得到其特征
和集合
(所在行和列的所有向量集合)。则Aggregation操作为
实际上就是线性组合(以
的
位置向量(
维)的每个元素作为系数/权重,作用于
中每一个位置的向量(
维),相乘相加,作为
的
三、Squeeze and Excitation(SE)
原文链接:Squeeze-and-Excitation Networks | IEEE Journals & Magazine | IEEE Xplore
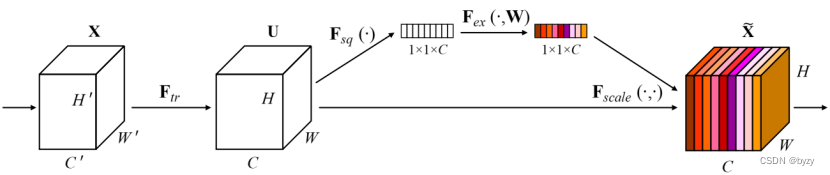
上图中:
为卷积、特征提取操作(不属于SE模块);
为均值池化操作,输出为
维向量;
为2层全连接层加sigmoid操作:
即
的每个元素作为权重乘上
的对应通道得到输出的每个通道:
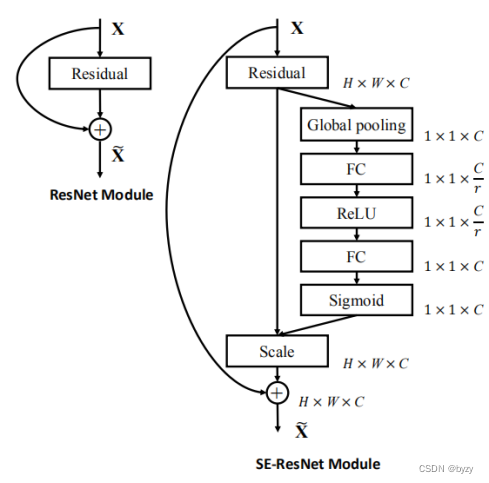
将SE嵌入到ResNet中:
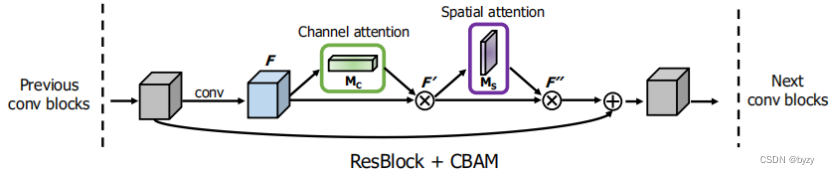
四、CBAM
原文链接:https://arxiv.org/pdf/1807.06521.pdf
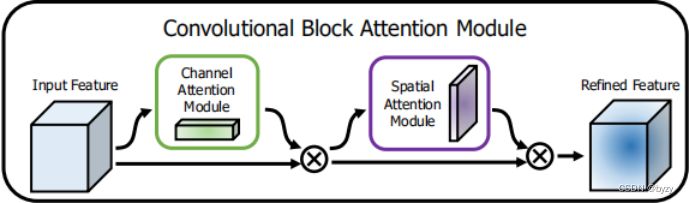
CBAM模块结构:
1.通道注意力模块结构
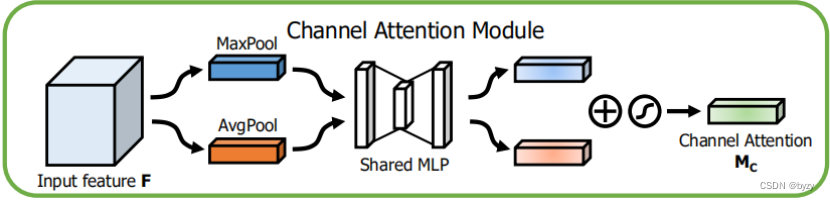
其中表示sigmoid函数,
,
;
后有ReLU激活函数。
2.空间注意力模块结构
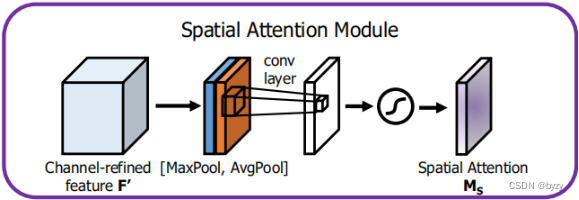
其中表示核为
的卷积操作。
将CBAM嵌入ResNet中:
五、Dual-Attention
原文链接:Dual Attention Network for Scene Segmentation | IEEE Conference Publication | IEEE Xplore
网络结构:
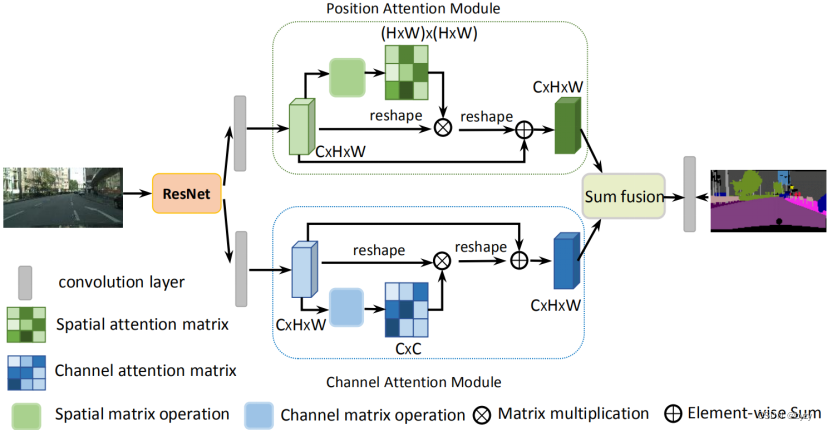
1.位置注意力模块结构
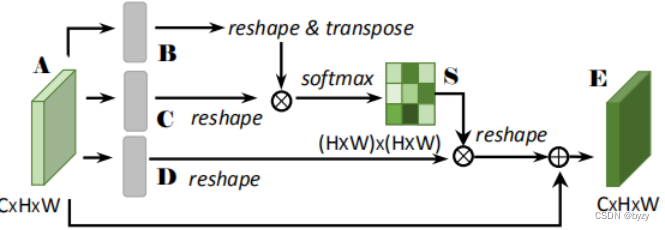
图中的维度与
相同;
的reshape表示将
的矩阵变为
(其中
);
为attention map;
表示矩阵乘法;最后的reshape表示将
的矩阵变为
。最终
其中为缩放因子,初始化为0,然后逐渐学习到更大的值;可知
的每个位置是所有位置特征和原始特征的加权和。
2.通道注意力模块结构
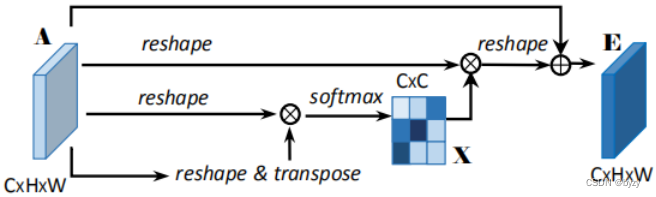
图中A的reshape表示将的矩阵变为
;
表示矩阵乘法; 最后的reshape表示将
的矩阵变为
。最终
其中缩放参数从0开始逐渐学习;可知
的每个通道是所有特征通道和原始通道的加权和。
3.Sum Fusion操作
使用卷积层变换两个注意力模块的输出,然后进行矩阵求和。
注:self attention的permutation equivalent
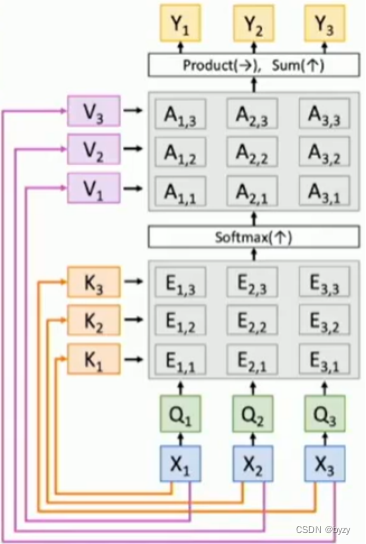
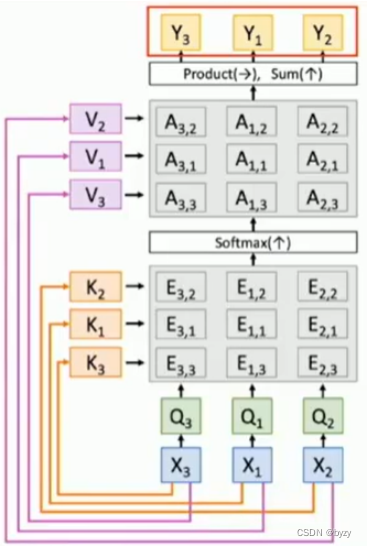
如上图所示,输入交换次序,输出也会相应交换次序。
















 5876
5876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











