







本文主要面向的读者是使用过评分卡模型建模,希望学习或者已经在使用更先进算法如GBDT类和神经网络类模型的风控建模人员。也欢迎所有对机器学习有兴趣的读者一起研讨。本文会详细分析各个算法之间的异同,帮助大家打通这些模型算法之间的联系,并在工作中逐步转移到更先进的算法当中去。
这一篇,我们会讨论多重共线性、正则化和过拟合。帮助大家从处理数据噪音的角度理解抗过拟合手段背后含义。
先从多重共线性讲起
在评分卡建模中,对于共线性高的变量,我们会选择一个留下,把剩余的剔除,并美其名曰增加模型稳定性。然而这对于机器学习背景的人而言是难以理解的。因为我们把特征看做是事物原本属性在经过一些噪音影响之后所采集到的信息,一个特征就对应于一个信道。而高共线性的特征往往来自相同的上游信息,并受到了不同噪音的影响。综合多条信道得到的信号应该比仅仅依赖于一条信道得到的信号更好。一些实际完全共线性的重复变量的确可以去除,但更多的是不完全重复的变量,仅仅因为共线性高就去除就没有充分利用其中的信息。
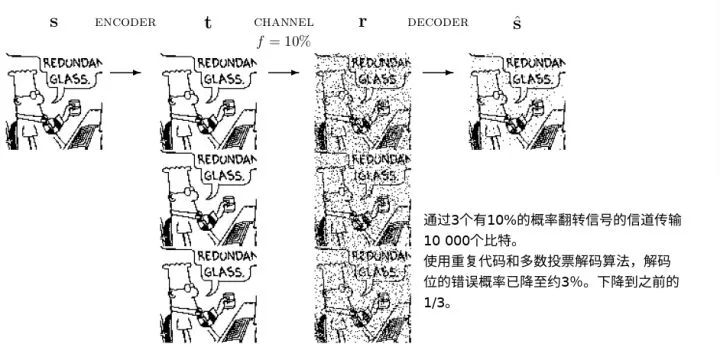
然后问题来了,评分卡建模方法说需要去掉有多重共线性的特征。而信息论说更多的信道总是好的,可以帮助降噪。(在机器学习中该理论的一个重要实现就是adaboost。)那么听谁的呢?听信息论的!和评分卡建模方法比起来,信息论作为一个广泛应用的基础理论拥有更高的普适性。当评分卡和信息论起冲突的时候,首先应该考虑,评分卡做错了什么。
正则项才是更好的选择
评分卡需要丢弃共线性高的变量的一个主要原因
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









