





各位小伙伴,google在2018年提出的NLP最强兵器Bert,目前也有提供可直接使用的预训练Model,下方链结就是我使用的Bert模型,详细的内容可以参考下面的链结
pytorch-pretrained-bertpypi.org
下面我开始测试这个bert模型有多好用吧!!
1. 新闻的分类
我准备的数据是新闻的标题、新闻的内容、以及新闻标题与内容的相关性(最不相关为0~最相关3)

首先先将新闻的数据整理,因为文本太长超过Bert的512个字符的长度,需要截取部份
df_train 2. 数据整理成Bert可读取的torch资料
将资料整理成三部份
- tokens_tensor:每一个单字的字符代号
- segments_tensor:两文本的分类(0代表第一个文本,1代表第二个文本)
- label_tensor:训练的文本产出(最不相关为0~最相关3)
from 3. Trainset整理成mini-batch
将资料整理成mini-batch,并且整理每个batch的数据
- 所有的序列都变成同一个长度,不足的部份将补0
- 增加masks_tensors,让有文本的部份的数据为1,让补0的部份设定为0,避免模型训练时将过多文本补0的值考虑进去计算
- 因为我的GTX 1080 Ti 测试后BATCH_SIZE最多只能放7个训练样本(因为我设定的文本约500个字符),需要自行逐步测试才知道自己的显卡能塞多少数据进去
"""
4. 文本分类的种类设定
因为我的文本有4种种类(0~3),所以设定为4种分类
# 載入一個可以做中文多分類任務的模型,n_class = 4
5. 取得初始化模型預測結果以及分類準確度
因为我有两张显卡(骄傲抬头),所以我把这个模型训练放在cuda:1中,若小伙伴只有一张显卡,要调整成cuda:0才能进行训练
"""
可以看一下最初使用Bert预测的结果,.......恩@@, 还没训练前的效很差,准确率只有28.88%
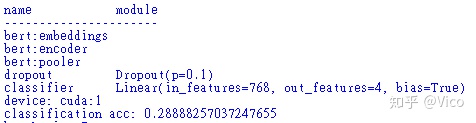
因为我们还没有针对这个文本进行二次训练,让Bert了解我想要的文本分类需求,下面就进行模型的再次训练吧
6. 设定模型参数
设定Adam的模型分类参数
def 7. 模型开始训练
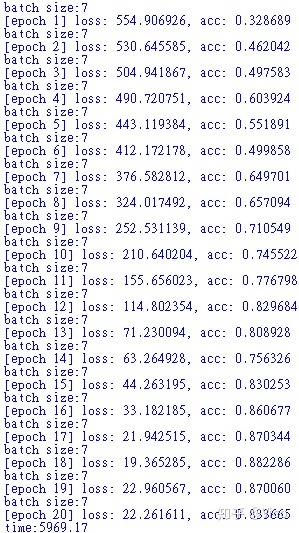
设定模型训练20次
import 下面开始训练的20次的情况,准确率有明显的提升83.36% (撒花!!)
8. 画图来看一下准确率
# 绘制训练的准确率图形
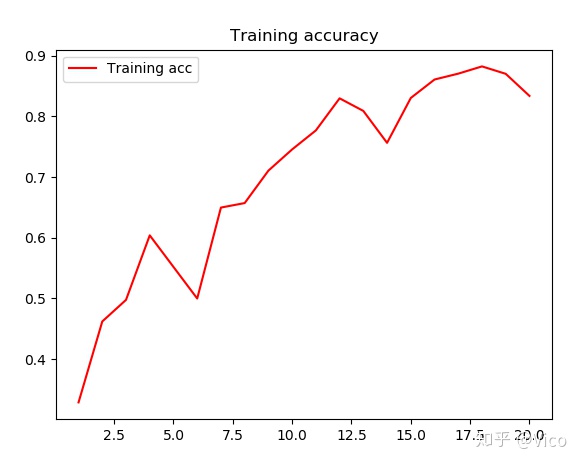
可以看出Bert做文本分类效果有显著的提升, Bert其实还可以做情感分析,只需要将分类的类别调整成2种即可,有兴趣的小伙伴可以自己测试看!!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









