





最近见识了大佬在代码中用"@"出了“一剑”,百思不得其解,甚至对“剑”本身都产生了怀疑······所幸在前辈的剑谱中找到答案,一起来见识一下吧。
欲练此功,必先~xx~理解基本功。
1.电路的两种延时
- 传输延时(Transport Delay)
电路的输入需要经过一段时间以后才能在输出端得到响应。
与此最相近的电路就是传输导线了,假如从线上A点到B点需要5ns,那么A点处信号可以随意变化且每次变化维持时间没有限制,在经过5ns以后这些变化可以完全的传递到B点。 - 惯性延时(Inertial Delay)
维持时间小于门电路自身传播延时的输入信号是不能引起电路的输出响应的。
对于组合电路其惯性延时的长度就等于其传播延时长度,而对于时序电路由于其具有“记忆功能”,所以传播延时被中间节点切开为若干段,此时每一小段组合电路的惯性延时长度就等于各自小段传播延时的长度,故而整体来看,时序电路的输入的惯性延时会比输入到输出的传播延时短。
对于组合电路我们可以先拿反相器来来理解,输入Vin使反相器的电容充放电才导致输出Vout的电位发生变化,电容充放电需要时间,这个时间也就是器件的传播延时,也即Vin需要维持至少传播延时的时间才能使电容充放电到位,才能在输出端得到一个稳定的Vout,若维持时间不够,电容充放电没完成则电路处于一个不稳定状态则会再逆向的充放电回到原来的稳态,也即输出不会发生变化;
对于更复杂的电路也是同理,可以把每一级电路等效为反相器,一级一级电容的充放电都需要时间,所以输入Vin需要维持至少传播延时的时间才能在输出端得到一个稳定的Vout;
时序电路具体就是锁存器和寄存器(由触发器组成),它们都可分为采样和维持两个阶段,只不过寄存器只在CLK边沿才采样,并对输入D有setup/hold要求;
而锁存器在整个CLK为高(或低)电平期间一直将输入采样到输出(此时对输入的持续时间也是要满足惯性延时的,只不过由于采用传输门电路结构这一段电路的惯性延时非常小,所以很容易满足),最后在CLK下降沿处进行最后一次采样(相当于寄存器的采样),并对最后一次的输入D有setup/hold要求,以保证采到的数据在关闭之前可以正确的传递到Q端。
2.setup/hold time
2.1 锁存器
锁存器在CLK控制锁存器导通期间即采样阶段,从输入到输出是完全透明的,输出会完全跟随输入变化(经过传播延时以后),也即所谓的(输入)电平敏感,此时输入D->Q的门电路延时就是D的惯性延时,也是传播延时,由于采用的是传输门结构所以它非常小,很容易满足;当CLK将要控制锁存器关闭时,由于关闭后需要在输出端维持最后一次采样的输入D,所以在这个CLK的边沿,就对D有了setup/hold要求,从输入D到中间节点X的tD->X(D->X的门延时一般比D->Q的门延时长)就是该锁存器的建立时间tsu,若CLK控制关断之后D还能影响X则D还需再保持一段时间,这段时间就是thold。
2.2 寄存器
setup/hold time是由寄存器本身的结构决定的,如下图,一个寄存器的工作分为两个阶段:
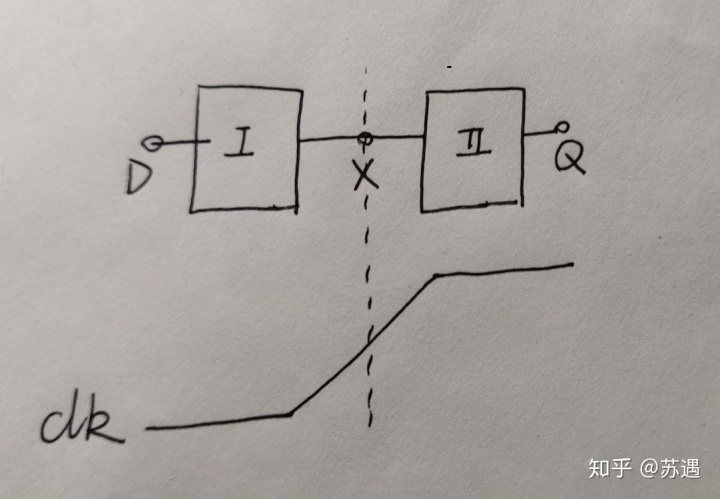
- 1.将数据D采样到中间节点X,记从D->X的门延时为tD->X,这一采样过程一般是在CLK上升沿之前,但也有的电路结构是在上升沿之后;
- 2.将数据从中间节点X传递到输出端Q,记从X->Q的门延时为tX->Q,有点电路结构会有两个中间节点(多个中间节点也可以等效为2个),分别记为X1和X2,此时采样过程是D->X1,传递过程又分为两部分:X1->X2、X2->Q;
- 3、因为这两个过程都是受到CLK控制的,所以再引入一个从上升沿到输出端口的延时tC->Q,C表示上升沿的正中间的时刻;
根据这两个阶段就可以划分setup/hold time了,分两种情况:
- 采样过程在CLK上升沿之前
这样C时刻在X点拿到的就是tD->X之前的时刻的D的数据(门电路传播延时),并且要求D在tD->X这段时间里维持不变(惯性延时),此时tD->X称为建立时间tsu;
C时刻以后即上升沿之后的高电平阶段,进入传输阶段,也分两种情况: - 若此时D还能影响到节点X一段时间(称为电路透明时间),这段时间的结束以D到X的通路关闭(如脉冲寄存器)或者在有多个中间节点的情况下已经从第一个中间节点X1传输到下一个中间节点(此时D已经通过X1正确的往后传了,如单相边沿触发寄存器)为结束时刻,那么上升沿以后的这段时间称为保持时间thold,即数据D在上升沿之后仍需保持不变的时间;这是由电路的结构决定的,如果在这段透明期间D发生变化,即数据D在上升沿之后仍需保持不变的时间小于thold,那么在经历固定的tD->X(传输延时)以后中间节点X保持不变的时间也小于thold(惯性延时),从而导致X处的值不能被后面电路采到,也就不能正确的传输到Q;
- 若C时刻以后D就不能影响到节点X,那thold自然等于0;
- 采样过程在CLK上升沿之后
此时由于D->X和X->Q都在CLK上升沿之后,所以可以省去中间节点X,直接记D->X + X->Q 为tD->Q,即从输入到输出的门延时;
这时,由于电路结构,此时数据D能直接影响Q一段时间(类似上面能影响中间节点X一样),且这段时间必然大于等于tD->Q,否则数据还没传到Q传输的通路就被关闭了; - 若这段透明时间刚好等于tD->Q,那数据D就要在C时刻准备好,然后保持tD->Q时间后刚好抵达Q,此时tsu=0,thold=tD->Q;
- 若这段透明时间大于tD->Q,那么D在C时刻甚至C时刻以后才准备好数据都是可以在透明时间结束前经历tD->Q传到Q的,上面定义从D准备好数据到C时刻为tsu,那这里tsu >= t透明时间-tD->Q,一般取极限值即tsu = t透明时间-tD->Q,因为tsu越小时钟周期T就可以越小,时钟频率就可以越大;
综上,我们可以对setup/hold time有一个更直观的理解:
由于寄存器的电路结构,使D->X和X->Q以CLK的上升沿C时刻为界分别有一段时间是导通的,根据电路的惯性延时D需保持tD->X才能传到X,这段时间就是建立时间tsu;而X在传到下一级节点(下一个中间节点或者直接是Q)时,根据惯性延时也需要保持一段时间tX->才能传过去,如果此时D还能影响X那tX->就会要求D再保持tX->时间,这个时间对于D而言就是thold,否则X自己会满足tX->延时,并不会要求D继续保持,即对于输入 thold=0;
如果D->X和X->Q都在CLK上升沿的同一边,那么考虑惯性延时和传播延时时D->Q就是一个整体,不必引入中间节点X,此时tD->Q与电路结构的从D->Q的透明时间就划分了tsu和thold,此时tsu和thold二者之一就有可能取负值了,但不会同时为负;
3. Verilog 仿真原理
首先Verilog所描述的硬件电路是并行的、输入驱动的,所以仿真器为了模拟这些硬件行为就有了仿真时间、事件和进程等概念。
- 仿真时间
同一个时刻会有很多事件需要执行,其优先级是由分层事件队列决定的;
仿真时间是根据时序模型与延时向前推进的; - 事件和进程
(更新)事件是指模型中数值发生了变化,这是模拟的电路的输入发生了变化;
更新事件会驱动进程的运算,进程的运算又会产生新的更新事件,更新事件和计算事件的执行顺序就是仿真器的调度;
进程也是一种事件,是计算事件,可以认为模拟的是电路的其中一级电路,进程包括原语、模块、Initial和always过程块、连续赋值语句、异步任务以及过程赋值语句(过程块中的assign和force语句)等;
进程在碰到时序控制(@、#、wait)时会被挂起,直到满足条件才被再次激活,这是模拟的电路的延时或者说是事件驱动;
进程被挂起的话就会忽略挂起期间所有敏感信号的变化; - 分层事件队列
仿真器先根据时间对时间排序,分为当前当前仿真时间事件和将来仿真时间事件;
然后同一时刻的事件再进行优先级排序,整个分层事件队列的优先级由高到低为:活跃事件、非活跃事件、非租塞赋值更新事件、监控事件和将来事件如下图:
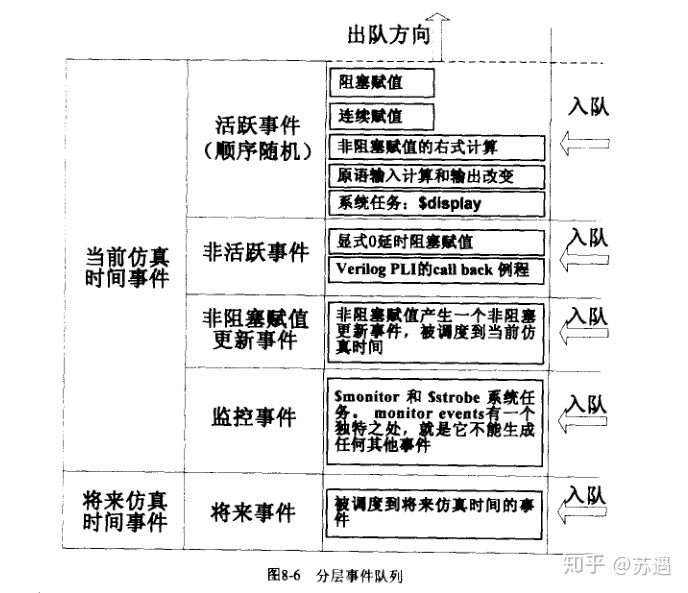
- 仿真时序模型
时序模型是仿真器的时间推进模型,分为门级时序模型和过程时序模型两种 - 门级时序模型
适用于分析连续赋值语句、过程连续赋值语句和原语等;
它对输入敏感,只要输入有变化就会重新计算该电路的输出,模拟的是组合逻辑电路;
新的更新事件来的时候如果还有之前的事件已被调度但还未执行,则会撤销旧事件只执行新事件,这个模拟的就是组合电路的惯性延时,输入变化太快则得不到输出响应; - 过程时序模型
适用于分析只对部分变量敏感的initial和always过程块;
它只对部分输入变量敏感,并不会对所有的变化都敏感,模拟的是时序逻辑电路,如对于锁存器在导通期间输出会跟随输入变化,即电平敏感;对于寄存器它只在时钟边沿采样输入;
在一个更新事件被调度但没完成,再次调度该寄存器的另一个更新事件,即使在同一个时刻,前一个更新事件也不会被取消,这模拟的是时序电路,因为其具有记忆性。
对于寄存器,它的工作可分为两个阶段采样和维持,采样由D->X,再有X->Q,也即从上升沿到Q是有延时tC->Q的,在这期间数据D或者clk都有可能变化的,所以仿真器就模拟寄存器也将这一过程分为2步,第一步采样D到X(计算右值),接着再把X更新到Q(更新),并将这两步放进两个不同的队列,也即允许这两步中间插入别的事件,比如D再次发生变化(违反hold条件)或者clk上升沿再次来临(违反setup条件),因为实际电路中是有可能违反setup/hold的所以仿真器这种模型也是可以允许违反出现的。
对于锁存器,在它导通期间由D到Q是透明的,Q完全跟随D变化也即只要输入D(电平敏感信号)变化,输出Q就要重新计算一遍,也即它的结果更新事件也应该是可以被打断的,所以它的计算和更新也应该分开,并且放进两个个不同的队列。所以对于寄存器和锁存器最好用非阻塞赋值,因为它的右值计算和左值更新就是分两步且可被打断的,而用阻塞赋值这两步连在一起不可打断就模拟不了锁存器输入快速变化以及寄存器违反setup/hold条件的情形。
关于上述两种仿真模型,这里照搬参数书上的例子来帮助理解:
- 门级时序模型的惯性延时:
assign #8ms Ck_delay = Ck;//Ck是周期为488ns的时钟信号
上述代码想将一个周期为488ns的时钟信号延时8ms后传给Ck_delay,门级时序模型的写法永远也传不过去,因为Ck每隔244ns就变化一次,即每隔244ns assign语句就会产生一个新的更新事件,并撤销未完成的上一个更新事件(因为它延时8ms,现在才过去244ns自然还未完成),这样Ck永远也没机会更新到Ck_delay;
这样就实现了过滤掉维持时间小于惯性延时8ms的输入;
- 过程时序模型:
错误写法:
always@(Ck)
begin
Ck_delay = #8ms Ck;
end
这种写法由于使用阻塞赋值所以计算右值Ck以及8ms后更新左值要连在一起,所以这8ms里会对Ck的新变化不敏感,换言之,这8ms里Ck每次的新变化都不会重新进入这个always块,更得到输出响应,所以这种写法不是过程时序模型;综合前的RTL代码会错过Ck的变化,而综合后的电路是一根导线,所以这种写法并没有使仿真器模拟出我们想要的电路(一根带8ms延时的传输导线),所以这种写法是错误的;
正确写法:
always@(Ck)
begin
Ck_delay <= #8ms Ck;
end
这种使用了阻塞赋值所以每次计算完右值就又可以对输入Ck敏感了,所以Ck的每一次变化都可以在8ms后传递到Ck_delay上;这种对应的电路就相当于一个锁存器后面接了一段传输延时为8ms的传输线,这里#8ms就完美的模拟了传输线的传输延时;
- 阻塞赋值与非阻塞赋值
在过程块中的过程赋值,操作符是=,就是阻塞赋值;操作符是<=,就是非阻塞赋值;(操作符=对线网的赋值称为连续赋值,不是阻塞赋值)
根据上面对过程时序模型的分析,我们可以看出在写时序逻辑(寄存器和锁存器)时最好使用非阻塞赋值,在使用always块写组合逻辑时最好用阻塞赋值。
这是由仿真器原理决定的,<=的设计就是过程时序模型,它分将右值计算和左值分两步并可被打断的设计模拟的就是寄存器和锁存器的工作原理,配合边沿触发或者部分敏感的always块实现时序逻辑是最合理的;
组合逻辑使用assign连续赋值和全敏感的always块结合阻塞赋值两种方式来实现,且两种方式是等价的,只不过放always块里可对reg型变量操作,位选可以更方便,这两种方式都体现出组合电路的并行和输入驱动的特点。
这只是根据仿真原理得到的描述电路的组合方式,至于其他的组合也有可能综合出正确的电路,但有可能前仿真和后仿真会不一致。并且代码看起来很没有硬件思维,还很容易仿真出错,如:
always@(posedge clk or negedge rstn)
begin
if(~rstn)
y1 = 'h0;
else
y1 = y2;
end
always@(posedge clk or negedge rstn)
begin
if(~rstn)
y2 = 'h1;
else
y2 = y1;
end
上述代码两个always块是并行的,谁先谁后仿真顺序随机,但是由于使用了阻塞赋值(赋值期间不允许被打断),所以两个always之间就存在竞争,而若使用非阻塞赋值就无此问题。
always@(posedge clk or negedge rstn)
begin
if(~rstn)
max = 'h0;
else
begin
tmp1 = a > b ? a : b;
tmp2 = c > d ? c : d;
max = tmp1 > tmp2 ? tmp1 : tmp2;
end
end
always@(*)
begin
tmp1 = a > b ? a : b;
tmp2 = c > d ? c : d;
end
always@(posedge clk or negedge rstn)
begin
if(~rstn)
max <= 'h0;
else
max <= tmp1 > tmp2 ? tmp1 : tmp2;
end
再比如上面两端代码实现的是同样的逻辑,但是第二段代码明显可以看出电路的思维:先3个组合电路比较器(tmp1 > tmp2 也算)输出线接到寄存器的输入,在时钟上升沿对其进行采样。
虽然也有将逻辑电路嵌入到寄存器的电路结构,但除非特殊需求,我们一般只描述逻辑,具体的电路由工具根据约束自动选择。而且主要第二种写法更能体现硬件思维。
- 时序控制
时序控制包括延时语句(#)、事件语句(@)和等待语句(wait),时序控制总是伴随着进程的挂起和激活。
执行一个进程时如果碰到时序控制语句(#、@、wait),该进程就会被挂起,直到该事件发生、已经过延时中的时间单位数或者等待语句的表达式变为真,该进程才会被再次激活。 - 延时语句
延时语句有正规延时和内定延时两种:
正规延时是立刻挂起进程等延时时间过了再拿那个时刻的输入信号做运算;
而内定延时是先拿当前时刻的信号做完运算,然后将结果存起来再将进程挂起,等过完延时后再更新结果。
延时语句与阻塞/非阻塞赋值语句是两个工具,组合在一起用来模拟组合电路中的惯性延时和电路中传输导线的传输延时,但是只有两种组合能正确的模拟出实际电路的的惯性延时和传输延时: - 惯性延时 :正规延时和阻塞赋值;
always@(a or b)
begin
#5 c = a + b;//过滤掉维持小于惯性延时5ms的所有输入
end
- 传输延时 :内定延时和非阻塞赋值;
always@(posedge clk)
begin
Ck_delay <= #8ms Ck;//模拟8ms的传输线延时
end
而其他组合虽不能用来模拟真实的电路延时,但根据语法也是可以存在的,一般可以在TestBench中巧妙运用,如:
always@(clk)
begin
#50 clk <= ~ clk;
end
always@(clk)
begin
#50;
clk <= ~ clk;
end
上述两条用来生成时钟,且是等价的因为从语法上遇到正规延时都会将进程挂起,而这些组合若使用不好也会达不到预期的功能,如:
always@(clk)
begin
#50 clk = ~ clk;
end
原因其实根据仿真器原理和语法显而易见--使用了阻塞赋值。进程会先因为#50而挂起,然后执行阻塞赋值,一直到左值更新完才恢复进程对输入clk的敏感,但此时clk已经更新完了,所以震荡不起来的。
注意到语法上内定延时也会挂起进程的,如:
always@(clk or a)
begin
clk <= #50 ~ clk;
a <= a + 1;
end
这段代码仿真逻辑如下,首先不管因为clk变化还是a变化而进来,都先计算~clk,存下结果后挂起,50个时间单位后执行非阻塞,此时右值算计算完成,丢一个更新事件到队列,这样begin块的第一条语句执行完毕,到第二条,计算右值a+1后丢一个更新事件到队列执行完毕,这样两条语句执行完以后再等同一时刻活跃队列其他事件都执行完毕后开始更新非阻塞赋值,这样~clk和a+1会在同一时刻更新到左值去,并立即再次出发进程并这样一直重复。
延时语句只有在仿真阶段其作用,在综合时会被忽略。
- 事件语句
@()里面可以放电平、边沿和命名的event。
@(···)和延时#的使用语法非常类似,只是把挂起结束的条件从延时改为事件发生,如@()也有外放和内放两种用法:
always@(b)
begin
@(posedge clk)a <= b + 1;//同样等价于 @(posedge clk);a <= b + 1;
end
每当b变化进来,然后遇到@直接挂起,直到clk上升沿才执行非阻塞赋值,计算b+1,丢更新事件到队列,等下一次b变化。
always@(b)
begin
a <= @(posedge clk)b + 1;
end
每当b变化进来,计算b+1并保存起来,然后遇到@挂起,直到clk上升沿才算完成右值计算,丢更新事件到队列,等下一次b变化。
上述两段乍一看貌似和下面代码实现的功能一样,但在b不变化的时候还是有区别的,且对于intra模式,它拿到是b刚发生变化时刻的b的值,与下面在上升沿处才拿b的值也有区别。
always@(posedge clk)
begin
a <= b + 1;
end
设计@这种事件操作是为了模拟锁存器和寄存器的触发条件,至于其他的用法我们只要根据语法分析就好了,像上面延时那样不一定就有对应的实际功能的电路的。如:
always@(posedge clk)
begin
@(posedge clk)a <= b + 1;
end
第一个上升沿进来,遇到@直接挂起,直到再来一个clk上升沿才执行非阻塞赋值,计算b+1,丢更新事件到队列,等下一次上升沿到来,这样这个进程总共需要两个clk上升沿才能执行完。
@还可以和repeat结合,在TB里很好用,如repeat (5)@(posedge clk)a <= b + 1;表示在第5个上升沿处进行操作。
好了,我们最后来分析大佬使出的那一招剑法吧:
always@(a or b)
begin
b[7:0] <= a;
@(posedge clk);
b[8 +:8] <= b[7:0];
b[16 +:8] <= a;
end
a或b变化进来,计算右值a并更新到b[7:0],丢一个更新事件到队列,begin块第一条语句执行完毕,向下遇到@挂起,此时等该时刻活跃队列事件执行完毕后更新事件执行,
于是b发生变化再次触发该进程,于是还是在该时刻第二个进程2计算右值a并更新到b[7:0],丢一个更新事件到队列,begin块第一条语句执行完毕,向下遇到@挂起,此时等该时刻活跃队列事件执行完毕后更新事件执行,但是这次b没变化所以不会触发新进程;
等到第一个上升沿来临时执行进程1下面两条阻塞赋值,由于b发生变化于是各自分别再触发新的进程3和4,并都遇到@挂起;
等到再来一个上升沿来临时执行进程1下面两条阻塞赋值,由于b发生变化于是各自分别再触发新的进程5和6,并都遇到@挂起;
···
这样一直重复就相当于与时钟上升沿同步起来了,再也不会因为a变化而触发进程进来了。
若将其中的非阻塞赋值换为阻塞赋值,则达不到这样的效果。
always@(a or b)
begin
b[7:0] = a;
@(posedge clk);
b[8 +:8] = b[7:0];
b[16 +:8]= a;
end
a或b变化进来,计算右值a并更新到b[7:0](由于是阻塞赋值所以b更新完以后才恢复敏感,故不会二次触发),begin块第一条语句执行完毕,向下遇到@挂起,等上升沿来临时执行下面两条阻塞赋值,且都不会二次触发进程,所以等待下一次a或b变化再进来。
参考文献:
1.《设计与验证--Verilog HDL》
2.《Verilog 编程艺术》
3.《IEEE Standard for Verilog HDL》
















 4665
4665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









