





引言
- 非线性假设:
引入神经网络一定是现学的linear regression & logistic regression 解决不了的问题。建模太过复杂,(Polynomial terms increase the dimension [features] and complexity)
a. too much features (complexity); b. overfitting.
之前的Linear & Logistic 本质都还是建立在线性可加的理论基础上延伸出来的回归和分类建模。
神经网络可以进行非线性转化。(activate function transform)
2. pixel and data.
利用像素点来学习图片内容,进而泛化学习能力用来识别图像。
要点: 像素信息pixel (data form), 定位location (grid, scatter, point, vector)
- data capacity and learning (efficiency) time consuming.
grayscale (directly production of pixel metrics) & RGB (Red, Green, Blue 编程可视化显色常用) times 3:
灰度图像直接长×宽 获得整体像素,彩色图像需要乘以三。
# of features = combinations of pixel number = n*m C 2 (整体像素点选2, 2 代表i 横向维度和j纵向维度)
神经网络的仿生学:
详见另一个笔记:
whylovemyself:【机器学习】【期末复习】扯扯人工神经网络ANNzhuanlan.zhihu.com概括一下就是用一个算法集成并行解决网络性质的问题。
视觉,听觉,嗅觉,触觉等被触发,对应了解决不同环境情景下的不同问题。
感知系统可以公用(i.e. 用舌头"看")
在体内就是电流信息的传导,在数据模型中,传到的信息是解释变量。
以一个逻辑(神经)单位为例:
输入值(input layers):也就是解释变量。x0: bias unit (neuron)
中间隐藏层(hidden layers):就是解释变量试图去解释的逻辑关系。Activate Function: sigmoid
输入值(output layers):
最简化的就是三层: 输入层,中间隐藏层,输出层。
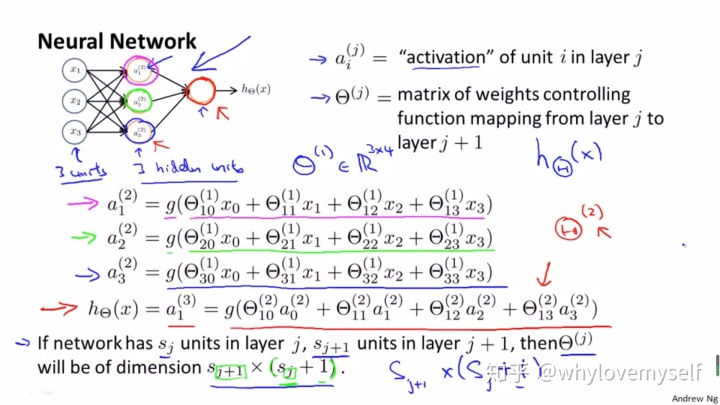
要搞清神经网络的框架维度: unit (i) & layers (j)
一个隐藏层的一个神经元单位的结构: 外壳是一个激活函数框架。内部构成是线性可加的以θ为权重矩阵的函数
比如说一共有三个输入神经元
也就是每个输入值(包括基础偏差)都对这个
一个输出层的最终结果结构:外壳还是激活函数。内核是第二层的线性可加函数。
对于系数矩阵的维度:
S: number of units; j: layer index
+1: 多加了一个Xo 也就是bias。
向量化表达:
- 将上述的激活函数内含Θ线性公式统一定义为
Z向量应该和激活单元的个数一致。Z 是还未被激活但是是神经元的线性组合。
, j 为layers index, n 为activate units index.
-
【有时候input 也可以用a表示:
】
-
【如果激活函数是sigmoid, 神经元的隐藏层到输出层的结构就等价于逻辑回归】
- 有关bias, 相当于回归里的截距。第二层的
architectures 在神经网络中的含义类似于不同神经元之间连接的结构。
一些实例:
- 二元环境分类问题: 利用非线性边界进行区分。
y的取值 {0,1} 两个维度 (features) x1, x2
XOR: x1 or x2 有且仅有一个值为1. y=0
XNOR: not (x1 or x2) 两者取值相同. y=1
boolean function: hθ(x) = (0[x1=x2=0],1[x1=1,x2=0],1[x1=0,x2=1],1[x1=x2=1]) 说明x1 or x2 ; hθ(x) =(0,0,0,1) 说明 x1 and x2. (最好画一个truth table 来列举不同组合下的x1,x2情况)
negation (means NOT)
Not X1 : x1=0 时hθ(x)=g(θx)=1 所以不是x1.
引用Boolean function & truth table 的目的是用来给neuron unit 赋予权重。
如果是NOT 那就赋予绝对值很大的负数权重。
e.g. 逻辑语言翻译(NOT x1)AND (NOT x2) ; hθ(x)=1 if and only if x1=x2=0.
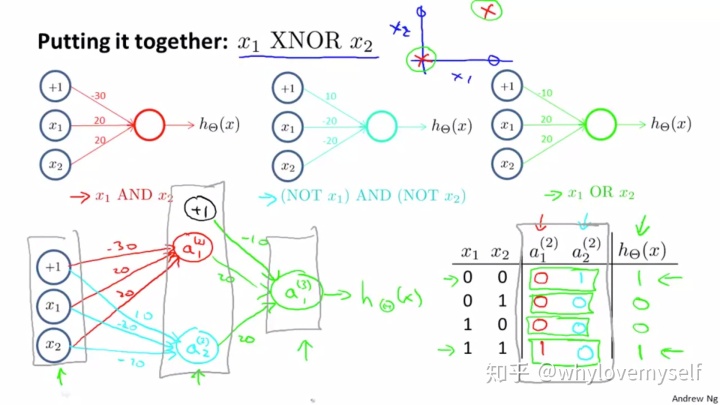
上图解释了一个嵌套组合式的三层简单神经网络。 输入层有两个神经元,加一个取值为+1的偏差值。 唯一的隐藏层有两个连接神经元,分别为输入层两者兼是(AND, 权重分配bias weight negative abs larger) 和 两者均不是的情况(NOR bias weights positive higher)加一个隐藏层的+1偏差。结果输入层与隐藏层的结构(注意区别于与输入层的OR结构,特别容易混淆)是(OR bias weights negative abs lower). 最终组合出来的效果是XNOR 即为x1 x2 取值为一致时的情况。
summary:
- parameter Θ 的三种可能组合情况:And (bias weights negative and lower abs value, other two are both large and positive); NOR (bias positive but abs value smaller. Other two units weights negative but abs value larger); OR (bias weights negative, but other two are positive with larger abs value)
- identify the index number. 上标注(j) 反映了layers. 下角标对应unites index
- nested structure:
上面所述的内容还都在二元分类的环境,以下要延伸至Y可以取多个类别的multiclass (output index should be same as the class number)。
one-vs-all
以往的线性分类是1,2,3... series. 延伸到多分类环境构建哑变量dummy variable --> vectors (column = 1) --> matrix of Y
比如图像识别:X image, Y labels.
total number of elements in a hidden layers = #units × #classes 不包含bias unit !















 8161
8161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









