







1.char(n) 定长类型:无论够不够长度,实际都只占据n个长度,不够的话用空格补齐至n个长度,取出时将空格删掉,利用率i/N
varchart(n) 变长类型:不用空格补齐,但在列内容前有1-2个字符来标志该列的内容长度,利用率 i/i+(1-2)
n代表字符,不代表字节,char适合字符长度稳定在一定范围的变量,创建表时,优先考虑常用和定长的信息,不常用信息和比较占空间的信息单独建表
2.key_lens , utf-8编码下 1个字符代表3个字节 ,null占据1个字节,varchar数据类型多2个字节,如索引列数据格式为varchar(20) 则对应63(20*3+3)个字节
3.避免索引失效的原则:复合索引避免跨列或无序使用/尽量使用全索引匹配/不要在索引上进行任何操作(计算/函数/类型转换)/复合索引如果左边失效 则右边全部失效/复合索引不能使用(<> !=)或is null(is not null)否则自身及右侧全部失效/复合索引如果有>符号,自身及右侧索引全部失效/索引优化存在一个概率问题,一般而言,范围查询(< > in)后的索引失效
4.like尽量以常量开头,避免以%开头,否则索引失效;如果无法避免可以使用索引覆盖挽救/尽量不要使用类型转换,否则索引失效/尽量不要使用or,否则索引失效
5.如果主查询数据集大,则使用in/如果子查询的数据集大,则使用exists(将查询结果放到子查询进行校验)
6.查询出2门及2门以上不及格者的平均成绩
count() 返回的结果是总行数,不论是否满足条件,因此count(socre)和count(score < 60)得到结果是一样的
sum()和score< 60 结合的理解:sum( score < 60) >=2 ==>计算出至少挂了2门课的人
select name,sum(score < 60) as gk ,avg(score) as pj
from stu
group by name having gk >=2;7.where子查询系列:

先查询在排序”==>group by cat_id ,但goods_name, shop_price,我们应该取谁的呢?
select good_id, goods_name, shop_price
from goods
where goods_id in (select max(goods_id) from goods group by cat_id);
count(col)返回指定列中非null值的个数
8.将A、B表中id值相同的两个num值相加,分组
select id,sum(num)
from (select * from ta union all select * from tb
) as tmp
group by id;更新和删除操作要注意:where条件记得要加
select * from user where 1;--从user表中查找所有列,当条件恒真--【输出所有】
9.把num值处于[20,29]之间,改为20:update main set num=20 where num between 20 and 29; num值处于[30,39]之间的,改为30
update mian set num=( floor(num/10)*10 ) where num between 20 and 39;10.把good表中商品名为'诺基亚xxxx'的商品,改为'HTCxxxx',SUBSTRING(name,3),从第三个字符开始,之后的所有个字符
select goods_id, concat('HTC', substring(goods_name,4)) ,shop_price
from goods
where goods_name like '诺基亚%';10.对于数据表中,null不利于数据表优化操作,所以数据表中一般都对字段设置not null
11.例题:select goods_id, goods_name,(market_price-shop_price) as 'min' from goods where min > 200
报错:不识别min这个列!
【where子句针对的对象是磁盘上的数据表文件去select的,而select出来后的数据是存放在内存中的一个零时"结果集"】
12.例题:用exists型子查询,查出所有商品的栏目下有商品的栏目
select *
from category
where exists (
select * from goods where goods.cat_id = category.cat_id);13. 相关子查询,查询每个部门工资前三名的员工信息
select deptno, ename, sal from emp e1
where (select count(1) from emp e2 where e2.deptno=e1.deptno and e2.sal>e1.sal) <3
/*这里的数值表示你想取前几名*/
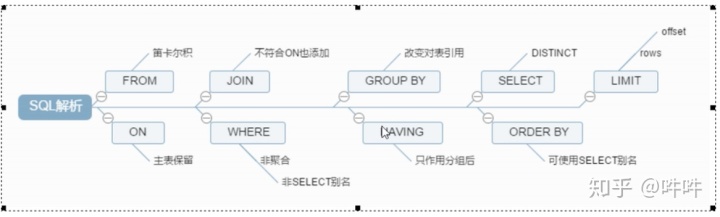
order by deptno, sal desc; 14.SQL执行顺序:
关于sql和MySQL的语句执行顺序(必看!!!) - New.Young - 博客园www.cnblogs.com(1)from (2) on (3) join (4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum.... (7)having (8) select (9) distinct (10) order by
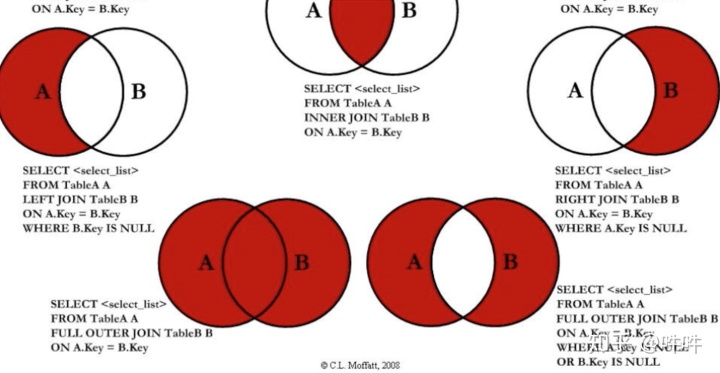
MySQL不支持 full out join 转而采用union
15.索引是一种排好序的快速查找数据结构
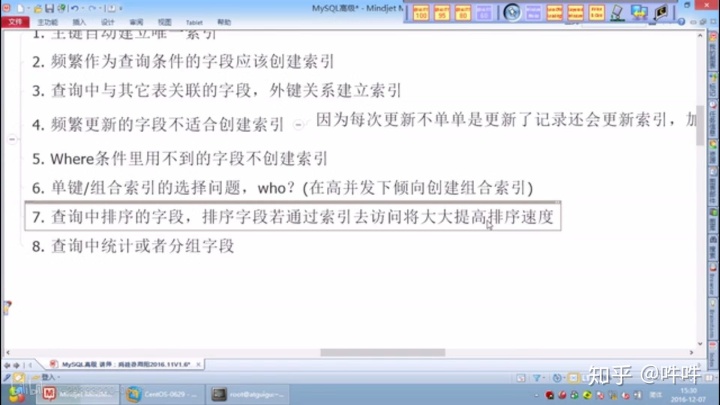
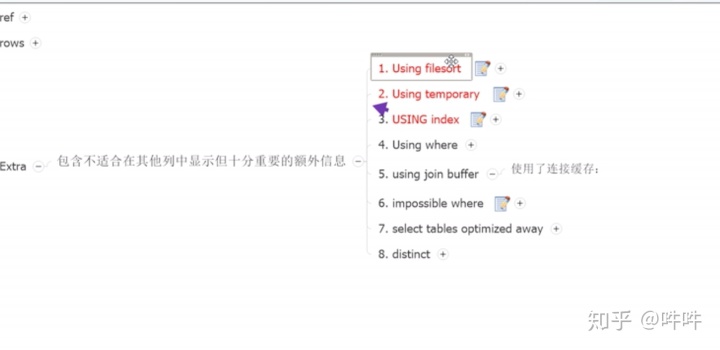
最左前缀原则,避免范围查询

双表:left join建在右表,right join建在左表


索引失效:
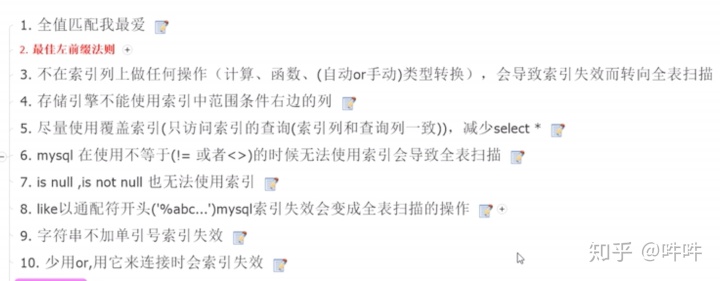
最佳左前缀法则:

Group by查询优化:

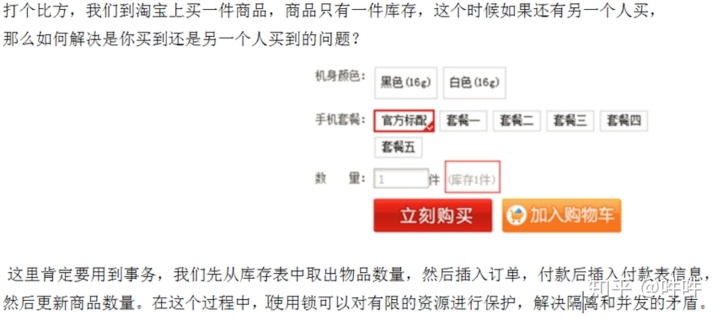
16.锁:行级锁,表级锁,页面锁
MyISAM表锁,InnoDB 行锁















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









