





最近在做地标 POI 推荐相关的工作。survey 到一篇不错的文章,Paper from KDD 2020:

作者全部是百度高 T,二作是 CTO 王海峰。猜测本篇文章的可信度较高。不 fancy,却很实用。
方法简称 P^3AC,即标题中的 Personalized Prefix Embedding for POI Auto-Completion
Abstract
POI 自动补全(point of interest auto-completion, POI-AC)是地图搜索引擎里的一种常见功能。该功能会根据用户的每次输入,提示出一系列的动态 POI 列表,节约用户的输入成本。这里 POI 和绝对地理位置不完全相同,会根据用户个人习惯、兴趣有特定设置。
现有排序方法基本都是结合手工特征、历史 POI 信息,做个性化 learning to rank。本篇文章中提出一种端到端的神经网络框架,建立了用户、个人输入习惯、感兴趣 POI 之间的关系。
框架包括3个主要部分:多层 Bi-LSTM 网络建模个性化前缀、textCNN 建模多源 POI 信息、一个 triplet ranking loss 以同时优化 personalized prefix embedding 和 POI embedding。
Introduction
介绍了百度地图的基本情况,以及 POI-AC 的产品形式。同时说明目前工业界广泛实现的 POI-AC 方法与搜索引擎里的搜索词自动补全方法非常类似。
然而 POI 非常不同于用户产生的搜索词,因为 POI 是一个包含多源异质信息(例如 GPS 坐标、位置,甚至图片)的地理实体。此外,历史点击的搜索词、点击/未点击 POI 可以被用于生成个性化提示。因此,个性化 POI-AC 的关键目标是为了每个用户的喜好和输入习惯,展示独立不同的 POI list。
个人认为,本文更有价值的是提供了一种工业界实用的建模思路和特征工程,以及线上的实现细节。而不是具体使用的 Bi-LSTM、TextCNN 模型,这里可以尝试用 Transformer-based 的方法作为特征提取器替代。
前人工作
- 相关学术探索
- 分别介绍了:启发式搜索词自动补全、基于 learning to rank(LTR)的搜索词自动补全、个性化搜索词自动补全,三个方向的学术探索工作。这部分不是本文重点。
- 工业界实践
- 百度地图上个版本的 POI-AC 使用的是一个两阶段框架。一阶段生成 topN 的 POI 候选集,二阶段根据用户特征、POI 特征做排序。这种方法同时兼顾了效率和效果,也是工业界解决大规模排序问题的传统套路:召回-(粗排-)精排。

-
- 大量的学术工作聚焦于第二个阶段的精排步骤,面对经过第一个阶段筛选之后的数百个 POI 做排序。百度地图之前在这里使用的排序器是 GBRank,输出排序得分。
这里有 2 个问题
Q1:如何在第一阶段生成 topN 的 POI 候选集呢?
A1:通过查阅此团队之前的 paper[1],了解到是通过用户输入的 prefix 文字做倒排召回,缩小候选集。这里其实还有其他思路,例如使用 GPS 位置召回附近范围内 POI,对于抖音而言可以用视频内容作为召回,都是可行的。
Q2:如何替换 GBRank 的方法做精排呢?
A2:下文着重写向量化特征训练的过程,很自然想到得到向量化特征后,求 personalized prefix embedding 甚至是 user embedding,与 POI embedding 之间的向量距离。
本文框架
如果无视学术研究、工业实践这些目标,基于 LTR 模型的 POI-AC 会因为一些原因碰到效果瓶颈(这两个瓶颈都是基于百度地图之前的方案相较而言,看完实验部分就能理解了):
-
- 启发式特征选择
- 用户输入历史无法直接建模每个用户复杂的输入习惯
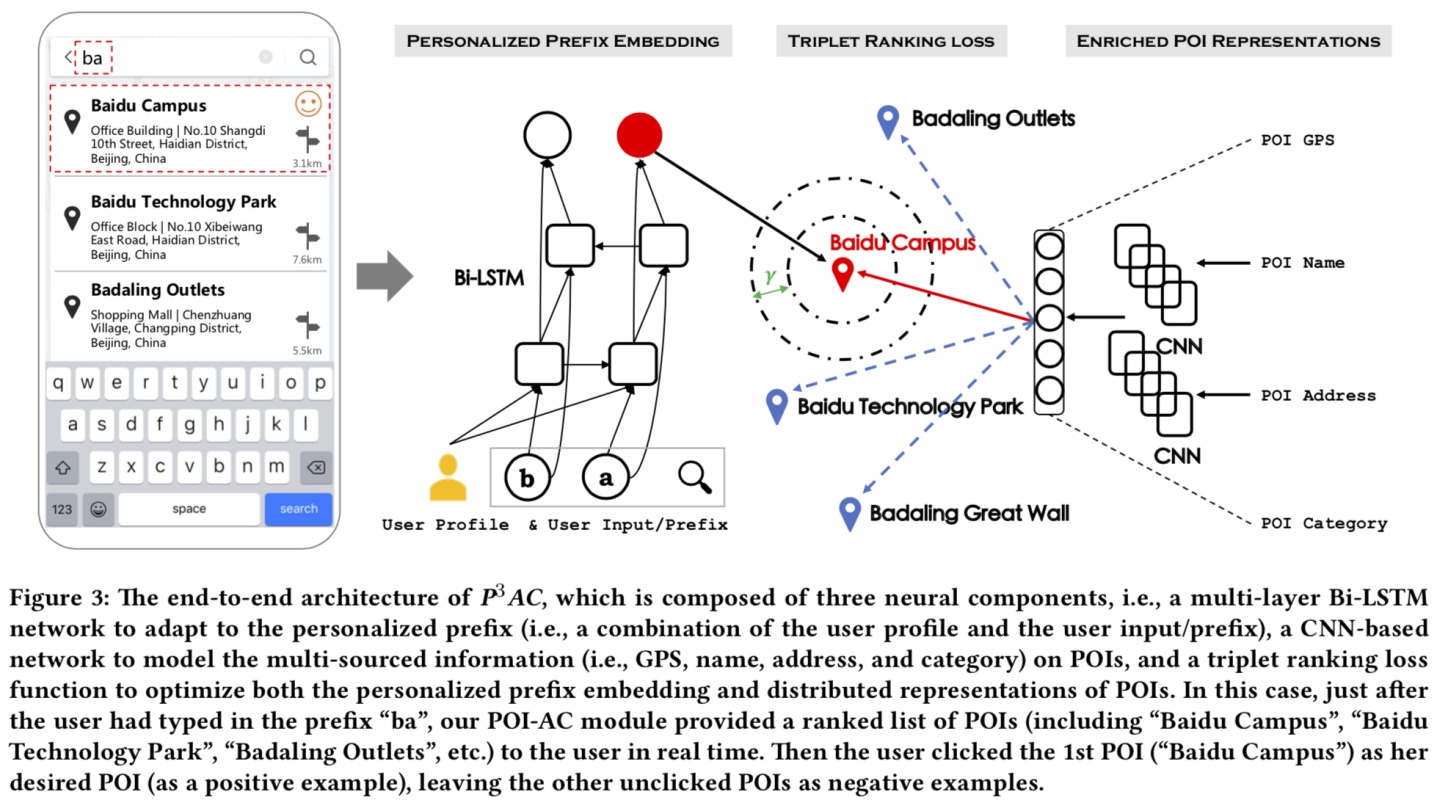
为解决以上问题,本文提出了端到端的神经网络框架(简称 P^3AC)。具体框架见图:
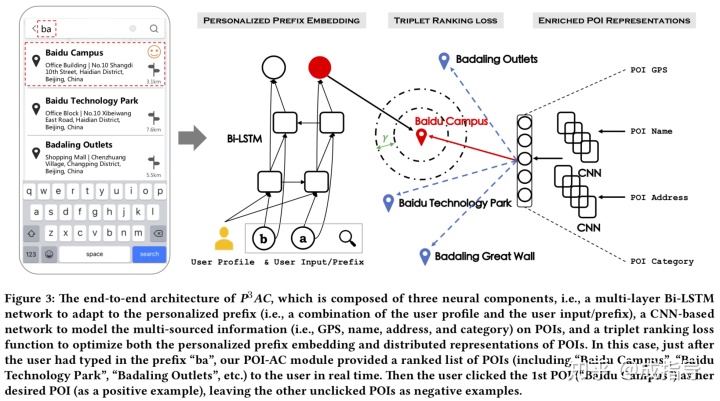
Personalized Prefix Embedding
当用户在百度地图的搜索框内首次输入拼音或汉字时会触发 POI-AC。换而言之,此处“用户意图”由两部分组成:用户特征、输入前缀文字。
给定用户输入前缀字符序列
这里有个 trick:建模时为保持用户的个性化,融入用户特征向量来表征这个前缀。
这里有 1 个问题
Q:用户特征向量哪里来呢?
A:可以从用户的人口特征,例如性别、年龄等融合。甚至可以考虑迁移使用其他用户行为更密集的场景(例如推荐、搜索等)迁移而来的用户特征刻画。
具体来说:
- 先建立一个 8000+汉字、10个阿拉伯数字、52类英文字母表组成的字符库,然后用随机向量初始化每个字符。此时给定前缀序列
,concat 每个字符 embedding
和用户特征向量
,同时一步步地给 Bi-LSTM 输入 concat 之后的变量得到每个字符的过去编码、未来编码:
和
;
- 综合 concat 过去编码、未来编码,能得到单个输入字符的个性化上下文 embedding:
;
- 对每个字符的上下文 embedding 的不同贡献度重新赋权重,使用单次 attention 机制:
,其中
,
是可学参数;
- 最后用
表示用户输入前缀的表征,即 Personalized Prefix Embedding
Enriched POI Embedding
一个完整的 POI 通常会包含多源异构信息例如 GPS 坐标(经纬度)、名称、种类和地址。
- 本文使用 TextCNN 方法将 POI 的名称文本、地址文本做句子级别的向量化,这个操作用
表示。通过对所有输入字符的 embedding 序列做
得到 POI 名称的向量化表达
和 POI 地址的向量化表达
。
- POI 种类特征则没有使用文字的向量化方法,百度地图的 POI 种类大约有 40+ 类,对这些类的类别 ID 直接做随机初始化得到种类向量
。
- POI 的 GPS 坐标是由数字构成,一种利用坐标的简单方法是转化成 2 维特征向量(经度、纬度)输入模型进行学习。另一种可行方案是使用 Geohash[2]:Geohash 通过将空间细分为网格形状的桶,它将地理位置编码为简短的字母和数字组成的字符串,为空间数据提供了层次结构,因此相邻的 POI 可以共享相同的 geo-embedding。GPS 向量化后得到
。
- POI 表征表示为:
。最终经过一次全连接层
,POI embedding 表示为
。
Triplet Ranking Loss
当得到了 Personalized Prefix Embedding 和 Enriched POI Embedding 之后,我们需要建立这两者之间的联系。POI-AC 功能在百度地图之前已经积累了大量的搜索日志,包括三元组:<用户输入文字、端上提示的 POI 列表、用户点击的 POI>。
训练 triplet ranking loss 的核心思想自然是将点击过的 POI 拉近,将展示而未点击的 POI 推远。这里定义 cosine 相似度作为两种 embedding 间的距离度量方法,即距离范围是 [-1,1]:
将单次 POI 搜索过程作为一个训练样本,第 i 个样本中 user prefix embedding 记为
实验
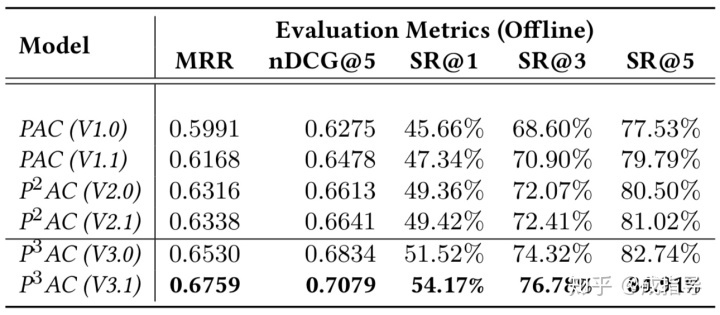
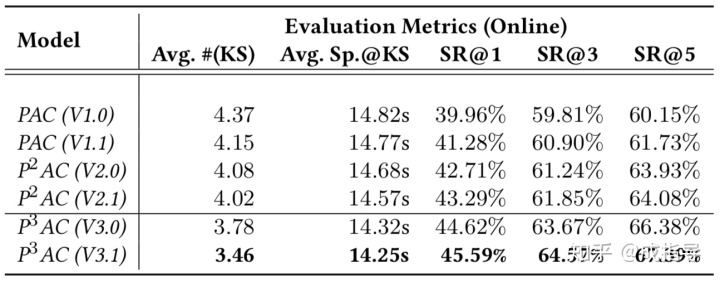
对比模型:比较了历史上三代百度地图的 POI-AC 方法。
- 第一代,PAC(V1.x)。V1.0 是 baseline 方法,完全使用 Query 补全的思路实现,综合考虑了 POI 的流行度、用户的人口特征(性别、年龄等)。V1.1 更多考虑了每个 POI 的时空特征,并且使用了一个额外的特征向量来表达在不同时间、不同地点搜索某个特定类型 POI 的频率。
- 第二代,P^2AC(V2.x)。第二代方法关注个性化的 POI-AC,尝试建立用户、POI 之间的联系。具体而言这里的联系特指用户历史点击过的 POI 之间的相似度。因此第二代方法的关键问题在于,如何度量 POI 之间的相似度作为特征,随后引出了 POI embedding 的概念。V2.0 里借鉴了 Word2Vec 的思路,训练 POI 的 ID 特征,但这里会引入类似“词表”之外的未知词(UNKNOWN)的问题,即不在“POI 表”中的 POI 表达未知的问题(这个问题会在两个场景下出现:新产生 POI 的冷启,长尾冷门 POI)。V2.1 方法里使用了本文类似的构建 POI embedding 的方案,从内容特征入手形成了 POI embedding,避免了 UNKNOWN POI 的问题。
这里有 1 个问题
Q:既然借鉴 Word2Vec 训练 POI embedding,那么 POI 的序列如何得到?
A:参考此团队之前的 paper[1],是将一个用户历史上搜索点击的 POI 序列根据搜索时间排序做为一条序列,类比 Word2Vec 中的文本序列做 skip-gram 或者 cbow 都可以。还听说过美团把用户打卡/种草的 POI 依次排序作为一条序列,这里都是生成序列的方法。至于为什么可以这么做,我想是因为代表了空间位置上的移动连续性,但我个人认为因为数据稀疏性,不是一个好的序列建模方案。
- 第三代,P^3AC(V3.x)。本文的方法,结合 Personalized Prefix Embedding,同时考虑了输入文本和个性化特征,用 triplet ranking loss 做训练。
利用百度地图的真实数据做训练,并使用 MRR/成功率(Success Rate, SR)/nDCG 作为指标进行离线度量。在线部署后,用户体验方面的指标包括平均按键(keystroke, KS)次数和速度都有显著下降。
离线评估:
在线评估:
未来工作
- 召回 POI 生成:召回 POI 的多样性、在召回阶段考虑到搜索的基本意图,会是下一步的改进方向。
- 个性化 POI 精排:更多特征应该被考虑到,本文只是这个方向的初步尝试。
引用
[1] Li Y, Huang J, Fan M, et al. Personalized query auto-completion for large-scale POI search at Baidu Maps[J]. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 2020, 19(5): 1-16.
[2] Morton G M. A computer oriented geodetic data base and a new technique in file sequencing[J]. 1966.















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









