







python在性能上,该说不说,一定不是后端服务的第一选择。
本系列文章将由几个好玩实用的例子开始,手把手帮助java程序员构建基于开源llm的ai应用。
主要技术栈:java\sql\langchain
后期手把手实现的产品:1、基于本地数据的个人ai助理 2、数据清理 3、数据抓取 4、LLM数据处理综合应用等。
起步
1、你需要自行安装ollama,并且下载对应模型,本系列文章基于qwen2:7b模型。
2、你的主机最好有显卡,更新驱动并安装对应cuda。
以上是基础要求,站内有很多教程。
第一个由java调用llm的例子
pom: 引入内容针对第一阶段需求,不针对每个实例,最好直接复制导入(如果有梯子,可以删除阿里镜像配置)。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.lion</groupId>
<artifactId>LangChainDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!-- 配置阿里云仓库 -->
<repositories>
<repository>
<id>aliyun-repos</id>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>aliyun-repos</id>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.31.0</version>
</dependency>
<!-- rag-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>0.31.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.31.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.12</version>
</dependency>
<!-- tavily--搜索引擎-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-tavily</artifactId>
<version>0.31.0</version>
</dependency>
</dependencies>
</project>package Done;
import dev.langchain4j.model.openai.OpenAiChatModel;
import static java.time.Duration.ofSeconds;
public class MyModel {
/**
* 此类方法返回一个model对象
* */
public static OpenAiChatModel getModel(){
OpenAiChatModel model = OpenAiChatModel.builder()
//你模型地址的url,注意后方/v1
.baseUrl("http://192.168.10.12:11434/v1")
//apikey ollama自动忽略此参数,但是为必填
.apiKey("ollama")
//模型名称,这个必须要和服务器中的一致
.modelName("qwen2:7b")
// 生成内容:保守->创造性。正像分布。
.temperature(0.3)
.timeout(ofSeconds(60000))/超时,主机性能和时间逆分布
.logRequests(true)
.logResponses(true)
.build();
return model;
}
/*
* 让我们试一试
* */
public static void main(String[] args) {
String answer = getModel().generate("你好?");
System.out.println(answer);
}
}
这里,我们构建了第一个模型对象,并且使用它调用了部署ollama主机的模型。
注意:
ollama默认无apikey,ollama会自动忽略,但是model对象必备apikey,所以随便写一个。
modelName必须和ollama中运行的模型名称一致,查看模型名称可在模型部署机控制台输入: ollama list
url后缀“/v1”别忘记了
temperature参数可以理解为:针对模型创造力进行了约束,可以自己试一试。
超时这个见仁见智。
后期这个类作为配置类使用,在本地尝试的过程中注意保存。
prompt模板
现在开始,坐稳了,我们正式开始构建你的个人llm应用!
先看代码:
package Done;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import java.util.HashMap;
import java.util.Map;
/**
* 模版的使用
* 既:提问的参数是key,调用时候为value的结构
* */
public class L01_PromptTemplate {
//获取模型对象
static ChatLanguageModel model = MyModel.getModel();
//模板的本质就是字符串的拼接,官方推荐使用{{}}
//{{name}}为表达式变量
static String template = "请介绍{{zlr}}";
//构建模板对象
static PromptTemplate promptTemplate = PromptTemplate.from(template);
//让我们试一试
public static void main(String[] args) {
//构建{{name}}数据,既模板变量设置
Map map = new HashMap();
map.put("zlr","赵丽蓉");
map.put("zs","大香蕉");
//生成prompt对象,并向模板内添加数据
Prompt prompt = promptTemplate.apply(map);
System.out.println(prompt); //=>Prompt { text = "请介绍赵丽蓉" }
System.out.println(prompt.text()); //=>"请介绍赵丽蓉"}
//试一下~
String answer = model.generate(prompt.text());
System.out.println(answer);
//不好的回答,所以这个模板需要调整
// 赵丽蓉(1928年3月4日-2000年7月17日),是中国著名的小品演员、国家一级演员。原名赵湘亭,出生于河南省开封县(现为兰考县)。她因在电视剧《红楼梦》中扮演刘姥姥而广为人知,并以幽默风趣的表演风格和深厚的艺术造诣赢得了观众的喜爱。
//
// 赵丽蓉于1953年加入中国广播说唱团,从事曲艺表演。1987年,她在电影《喜事》中的精彩演出获得了第6届中国电影金鸡奖最佳女配角奖。她最知名的角色之一是1990年代与巩汉林合作的小品《打工奇遇》,在这部小品中,她扮演了一位精明的老人,以其独特的幽默感和精湛演技赢得了广大观众的喜爱,并因此获得了第7届中国电视金鹰奖最佳女主角。
//
// 赵丽蓉在艺术生涯中多次获得奖项认可,包括1986年和1994年的中国电视剧飞天奖、1992年中国电影百花奖最佳女配角等。她以其独特的表演风格和对角色的深刻理解,在观众心中留下了深刻的印记。
//
// 2000年7月17日,赵丽蓉因心脏病在北京逝世,享年72岁,她的去世是中国影视界的一大损失。
}
}
首先,官方DEMO给出的prompt模板,使用双花阔的形式,双花阔号包裹着变量。
其次,我们构建模板对象可以是多个,可以提前构建分支语句,进行功能上的丰满。
代码中map对象kv结构代表着实际应用中,模板参数的存储和调用。
好了,试一下!
通过格式化prompt模板,构建llm输出内容的格式化(此章节比较重要,后期机器间通信需求此技术内容)
惯例,我们先看代码:
package Done;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.structured.StructuredPrompt;
import dev.langchain4j.model.input.structured.StructuredPromptProcessor;
import java.util.HashMap;
import java.util.Map;
/**
* prompt 结构体
*
* */
public class L02_StructuredPrompt {
@StructuredPrompt({ //结构体注解,往往用于格式化回复
"""
请查询演员{{name}} 的有关信息,
回答格式如下:
{
姓名:...,
作品:...,
简介:...
}
"""
})
static class CreatActorPrompt{
//这个类后期可以根据不同的需求去写,多场景化满足
String name;
public CreatActorPrompt(String name) {
this.name = name;
}
}
public static void main(String[] args) {
ChatLanguageModel model = MyModel.getModel();
//实例化模板对象,
CreatActorPrompt prompt_ = new CreatActorPrompt("赵丽蓉");
//prompt调用
Prompt prompt = StructuredPromptProcessor.toPrompt(prompt_);
//让我们试一试
String answer = model.generate(prompt.text());
System.out.println(answer);
//后续可以使用正则表达式对内容进行切割,获取想要的格式
// {
// "姓名":"赵丽蓉",
// "作品":"《西游记》、《还珠格格》、《武林外传》等",
// "简介":"赵丽蓉,中国著名女演员。1930年生于山东省济南市,是20世纪末至21世纪初中国大陆著名的喜剧表演艺术家。她以出演电视剧和小品著称,在演艺界有着广泛的影响力。赵丽蓉在《西游记》中扮演的“车迟国皇后”、《还珠格格》中的“李天霸”和《武林外传》里的“佟湘玉”的母亲等角色,深受观众喜爱。她以其独特的喜剧风格和精湛的演技赢得了广大粉丝的喜爱与尊敬。2000年1月17日,赵丽蓉因病逝世,享年69岁。"
// }
}
}
首先,这里出现了langchain的注解使用,这里使用注解,生成了一个prompt结构体,这个结构体中定义了问题的补全和回复的格式。
其次,此注解需要配合自定义类进行使用,如果为多个自定义参数,则构建多参数的类构造函数。为了避免后期使用bug,请避免无参构造的使用。
这里使用了ChatLanguageModel,本质上和第一节的modle一致,有不一致的地方,我们在后期详解中再说。
prompt实例化,这里使用了结构体静态方法去调用.toPrompt函数。
好了,试一下:
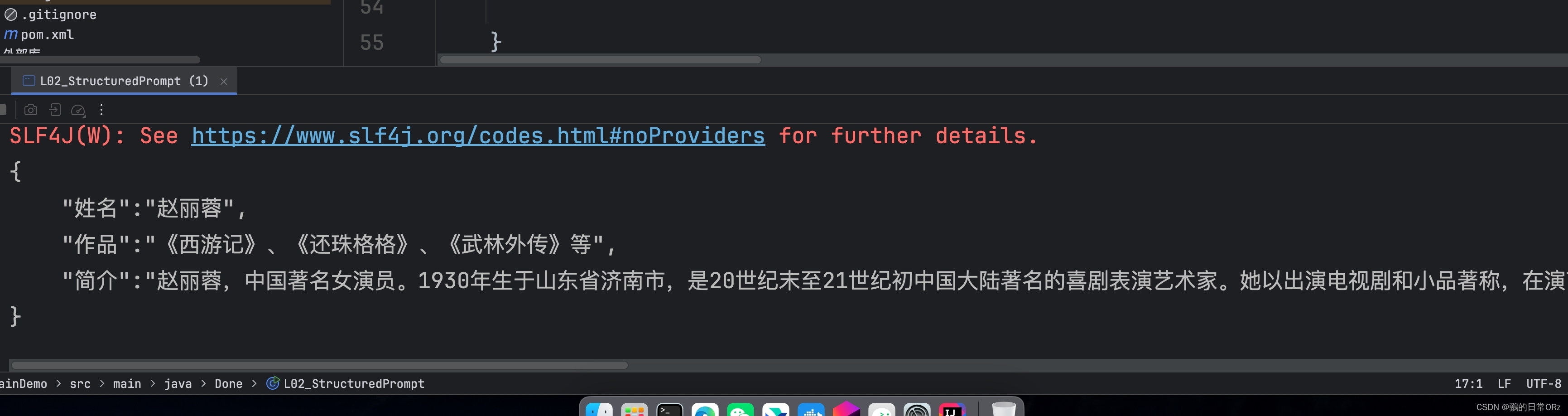
好了,很简单,我们格式化了数据,这样,数据就可以为我所用咯。
以上就是起步章节内容,下一章节,我们将开启本地文档、sql内容的使用。
i人,话少,见谅。
















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











