






数据科学中的异常检测技术之初学者指南。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩

本文将简要介绍一下异常检测,并指导你通过不同的技术来识别异常。
如果你正在处理数据,那么无论是现在还是将来,都可能会遇到一项非常重要的任务 —— 异常检测。它在许多领域中都有很大的应用,如制造业、金融和网络安全。
首先,异常检测涉及识别值与其余数据点明显偏离的罕见观察结果。这些异常值通常被称为离群值,是少数,而大多数项目属于正常类别。这意味着我们正在处理一个不平衡的数据集。
另一个挑战是,在行业内工作时,大多数情况下没有标记的数据,在没有任何目标的情况下解释预测结果是很有挑战性的。这意味着你不能使用通常用于分类模型的评估指标,并且需要采取其他方法来解释和信任模型的输出。接下来跟随本文一起开始了解吧!
什么是异常检测?
异常检测是指找到不符合预期行为的数据模式的问题。这些不符合预期行为的模式通常被称为异常、离群值、不协调观察结果、例外、反常、意外、奇怪之处或不同应用领域中的污染物。
Anomaly Detection: A Survey(https://dl.acm.org/doi/10.1145/1541880.1541882)
这是一篇简短的关于异常检测的定义。异常通常与在数据收集过程中获得的错误相关联,然后它们最终被消除。但也有一些情况,新项目与其余数据完全不同,并且需要适当的方法来识别这种类型的观察结果。识别这些观察结果对于在许多领域经营的公司做出决策非常有用,例如金融和制造业。
异常的类型有哪些?
主要有三种类型的异常:点状异常、背景异常和集体异常。
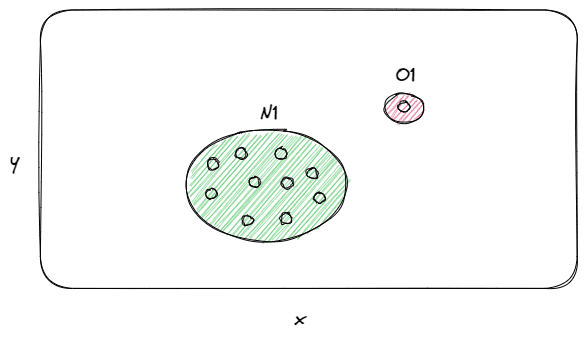
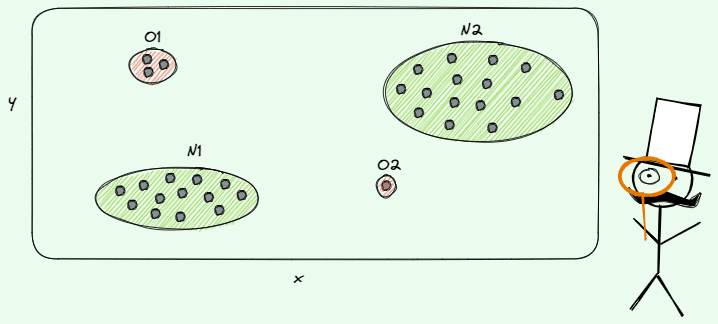
点状异常的例子。
正如你可能推断的那样,点状异常构成了最简单的情况。当单个观察结果与其余数据相比是异常时,它被识别为离群值/异常。例如,假设我们想在银行客户的交易中进行信用卡欺诈检测。在这种情况下,一个点的异常可以被认为是一个客户的欺诈活动。
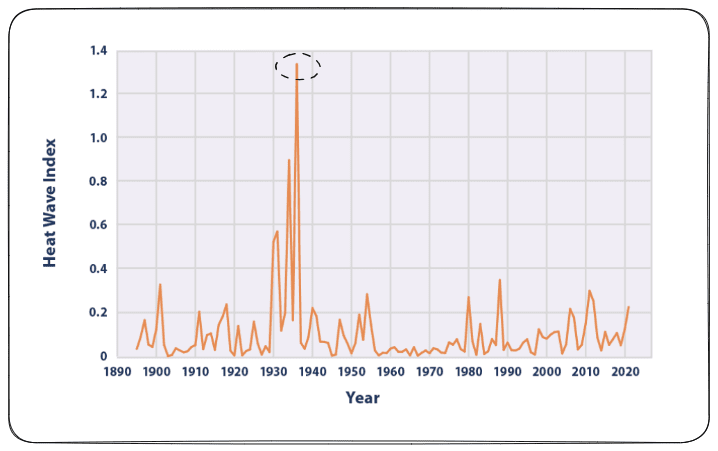
背景异常的例子。Credit EPA。
另一种异常情况是背景异常。你只有在特定的背景下才能遇到这种类型的异常情况。例如,美国的夏季热浪。你可以注意到在1930年有一个巨大的“沙尘暴”峰值,这代表了发生在美国的一个极端事件。之所以这样称呼它,是因为这是一个破坏了美国中南部环境的尘暴时期。
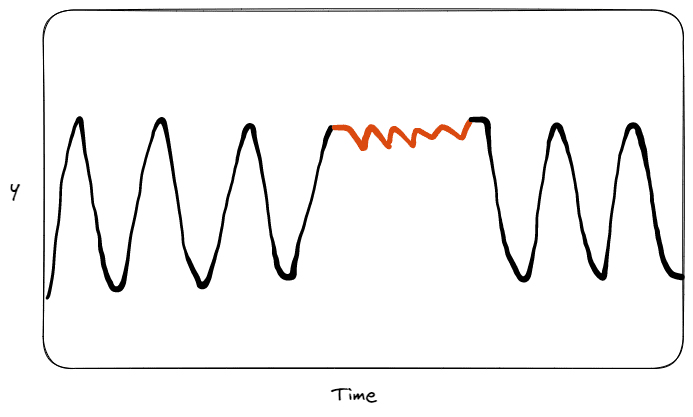
集体异常的例子。
第三种也是最后一种类型的异常是集体异常。最直观的例子是想象一下今年在意大利几个月内没有降水的情况。如果我们将过去50年的数据进行比较,就会发现从未出现过类似行为。在一个异常集合中,单个数据实例本身可能不会被识别为离群值,但所有这些数据点一起表明了集体异常。在这种情况下,单独一天没有降水并不是本身就是异常的,而许多天没有降水与前几年的数据相比可以被视为异常。
哪些机器学习模型可以用于异常检测?
有几种方法可以应用于异常检测:
-
孤立森林是一种无监督和非参数技术,由Fey Tony Liu于2012年引入。与随机森林类似,它是一种集成学习方法,可以并行训练决策树。但与其他集成方法不同的是,它专门用于将离群值与其余项目隔离开来。这种方法背后的假设构成了该方法有效性的原因:(1)与数量更多的正常数据相比,离群值属于少数类别;(2)离群值往往能以最短的平均路径被很快找到。
-
局部离群因子是由Markus M. Breuningin于2000年提出的基于密度的聚类算法,它通过计算特定项与其邻居之间的局部密度偏差来检测异常值。它假设离群值周围的密度应该与它的邻居周围的密度有着显著不同。此外,离群值应具有较低的密度。
-
自动编码器是由两个神经网络组成的无监督模型:一个编码器和一个解码器。在训练期间,只传递正常数据给模型。通过这种方式,它学习了正常数据的压缩表示形式,该表示形式应该与离群值的表示形式不同。还有一个假设是由于异于正常数据且完全不同,因此无法对异常数据进行良好重构,那么,它应具有一个更高的重构误差。
如何在无监督的环境下评估异常检测模型?
在无监督环境下,没有评估指标可以帮助你了解正确的正面预测比率(精度)或实际的正面比率(召回率)。
由于没有任何评估模型性能的可能性,提供模型预测的解释是比以往任何时候都更重要的。这可以通过使用可解释性方法(例如SHAP和LIME)来实现。
有两种可能的解释:全局和局部。全局可解释性的目的是提供对模型整体的解释,而局部可解释性的目的是解释单个实例的模型预测。
总结
希望这篇关于异常检测技术的快速概述对你有所帮助。正如你所注意到的那样,这是一个具有挑战性的问题,需要根据不同的环境而更改为合适的技术。我还应该强调,在应用任何异常检测模型之前进行一些探索性分析是非常重要的,例如使用PCA将数据可视化到较低维空间和箱线图。如果你想深入了解,请查看下面的资源。
资源
-
Anomaly Detection: A Survey by V. Chandola(https://dl.acm.org/doi/10.1145/1541880.1541882)
-
Isolation Forest’s paper(https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf)
-
Paper Review: Reconstruction by inpainting for visual anomaly detection(https://towardsdatascience.com/paper-review-reconstruction-by-inpainting-for-visual-anomaly-detection-70dcf3063c07)
-
SHAP’s paper(https://arxiv.org/pdf/1705.07874v2.pdf)
-
LIME’s paper(https://arxiv.org/abs/1602.04938)
推荐书单
《Python无监督机器学习最佳实践》
《Python无监督机器学习最佳实践》详细阐述了与无监督机器学习开发相关的基本解决方案,主要包括聚类、分层聚类、邻域聚类方法和DBSCAN、降维和PCA、自动编码器、t分布随机邻域嵌入算法、主题建模、购物篮分析、热点分析等内容。此外,《Python无监督机器学习最佳实践》还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
京东安全 https://item.jd.com/12961802.html
https://item.jd.com/12961802.html

精彩回顾
《快来体验PandasAI数据分析,将Pandas和ChatGPT结合起来》
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









