






时间序列分析:Python中的ARIMA模型,ARIMA模型是一种常用的时间序列预测工具,可以使用
statsmodels库在Python中实现。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩

时间序列分析广泛用于预测和预报时间序列中的未来数据点。ARIMA模型被广泛用于时间序列预测,并被认为是最流行的方法之一。在本教程中,我们将学习如何在Python中搭建和评估用于时间序列预测的ARIMA模型。
一、什么是ARIMA模型?
ARIMA模型是一种用于分析和预测时间序列数据的统计模型。ARIMA方法明确适用于时间序列中的常见结构,为进行精确的时间序列预测提供了简单而强大的方法。
ARIMA是AutoRegressive Integrated Moving Average的缩写。它结合了三个关键方面:
-
自回归(AR):使用当前观测值与滞后观测值之间的相关性建立的模型。滞后观测值的数量称为滞后阶数或p。
-
积分(I):通过对原始观测值进行差分来使时间序列平稳。差分操作的次数称为d。
-
移动平均(MA):模型考虑了当前观测值与应用于过去观测值的移动平均模型的残差错误之间的关系。移动平均窗口的大小为阶数或q。
ARIMA模型的表示为ARIMA(p,d,q),其中p、d和q用整数值替代以指定所使用的确切模型。
采用ARIMA模型时的关键假设:
-
时间序列是由基础的ARIMA过程生成的。
-
参数p、d和q必须根据原始观测值进行适当的指定。
-
在拟合ARIMA模型之前,时间序列数据必须通过差分使其平稳。
-
如果模型拟合良好,残差应该是不相关且服从正态分布的。
总而言之,ARIMA模型为建模时间序列数据提供了结构化和可配置的方法,用于预测等目的。接下来,本文将介绍如何在Python中拟合ARIMA模型。
二、Python代码示例
在本教程中,我们将使用Kaggle上提供的Netflix股票数据来使用ARIMA模型预测Netflix股票价格。
【Netflix股票数据】:https://www.kaggle.com/datasets/kalilurrahman/netflix-stock-data-live-and-latest
2.1 数据加载
本示例将加载带有“日期”列作为索引的股票价格数据集。
import pandas as pd
net_df = pd.read_csv("Netflix_stock_history.csv", index_col="Date", parse_dates=True)
net_df.head(3)

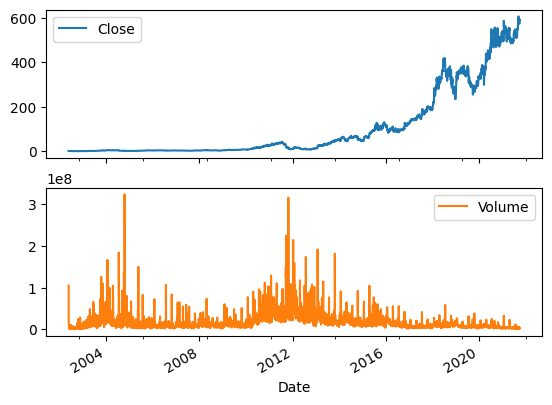
2.2 数据可视化
可以使用pandas的plot函数来可视化股票价格和成交量随时间的变化。很明显,股票价格呈指数增长。
net_df[["Close","Volume"]].plot(subplots=True, layout=(2,1));
2.3 滚动预测ARIMA模型
本示例的数据集已经被分成训练集和测试集,并且开始训练ARIMA模型。然后进行了第一次预测。
使用通用的ARIMA模型得到了一个糟糕的结果,生成了一条平直的线。因此,本示例决定尝试滚动预测方法。
注意:代码示例是BOGDAN IVANYUK的notebook的修改版本。
【notebook】:https://www.kaggle.com/code/bogdanbaraban/ar-arima-lstm#ARIMA-model
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
train_data, test_data = net_df[0:int(len(net_df)*0.9)], net_df[int(len(net_df)*0.9):]
train_arima = train_data['Open']
test_arima = test_data['Open']
history = [x for x in train_arima]
y = test_arima
# 进行第一次预测
predictions = list()
model = ARIMA(history, order=(1,1,0))
model_fit = model.fit()
yhat = model_fit.forecast()[0]
predictions.append(yhat)
history.append(y[0])
在处理时间序列数据时,由于依赖于先前的观察结果,通常需要进行滚动预测。一种方法是在收到每个新观察结果后重新创建模型。
为了跟踪所有观察结果,可以手动维护一个名为history的列表,该列表最初包含训练数据,并在每次迭代时将新的观察结果追加到其中。这种方法可以帮助我们获得准确的预测模型。
# 滚动预测
for i in range(1, len(y)):
# 预测
model = ARIMA(history, order=(1,1,0))
model_fit = model.fit()
yhat = model_fit.forecast()[0]
# 反转转换预测值
predictions.append(yhat)
# 观察结果
obs = y[i]
history.append(obs)
2.4 模型评估
本示例的滚动预测ARIMA模型在简单实现的基础上显示出了100%的改进,产生了令人印象深刻的结果。
# 报告性能
mse = mean_squared_error(y, predictions)
print('MSE: '+str(mse))
mae = mean_absolute_error(y, predictions)
print('MAE: '+str(mae))
rmse = math.sqrt(mean_squared_error(y, predictions))
print('RMSE: '+str(rmse))
MSE: 116.89611817706545
MAE: 7.690948135967959
RMSE: 10.811850821069696
接下来将实际结果与预测结果进行可视化和比较。很明显,本示例的模型进行了高度准确的预测。
import matplotlib.pyplot as plt
plt.figure(figsize=(16,8))
plt.plot(net_df.index[-600:], net_df['Open'].tail(600), color='green', label = 'Train Stock Price')
plt.plot(test_data.index, y, color = 'red', label = 'Real Stock Price')
plt.plot(test_data.index, predictions, color = 'blue', label = 'Predicted Stock Price')
plt.title('Netflix Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Netflix Stock Price')
plt.legend()
plt.grid(True)
plt.savefig('arima_model.pdf')
plt.show()

三、结论
在这个简短的教程中,我们提供了ARIMA模型的概述以及如何在Python中实现时间序列预测。ARIMA方法提供了一种灵活而结构化的方式进行时间序列数据建模,它依赖于先前的观察结果和过去的预测误差。
如对时间序列分析和预测感兴趣,可以阅读此文《50行代码探索金融数据,使用Python进行时间序列分析和预测》。
推荐书单

IT BOOK 多得(点击查看5折活动书单) https://u.jd.com/psx2y1M
https://u.jd.com/psx2y1M
《Python从入门到精通(第3版)》
《Python从入门到精通(第3版)》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python进行程序开发应该掌握的各方面技术。全书共分27章,包括初识Python、Python语言基础、运算符与表达式、流程控制语句、列表和元组、字典和集合、字符串、Python中使用正则表达式、函数、面向对象程序设计、模块、文件及目录操作、操作数据库、使用进程和线程、网络编程、异常处理及程序调试、Pygame游戏编程、推箱子游戏、网络爬虫开发、火车票分析助手、数据可视化、京东电商销售数据分析与预测、Web编程、Flask框架、e起去旅行网站、Python自动化办公、AI图像识别工具等内容。书中所有知识都结合具体实例进行介绍,涉及的程序代码都给出了详细的注释,读者可轻松领会Python程序开发的精髓,快速提升开发技能。
《Python从入门到精通(第3版)》https://item.jd.com/14055900.html

精彩回顾
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点

















 9370
9370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









