






本文我将基于源码的角度,来分析BufferReader与FileReader的区别。
首先在构造函数上
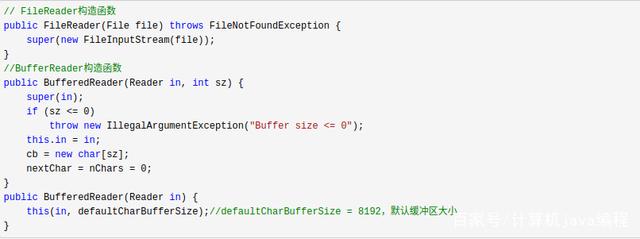
因为BufferedReader是对FileReader或者InputStreamReader进行包装,而FileReader的父类是InputStreamReader,所以两者的交集就是InputStreamReader,换句话说二者在构造时,都调用了InputStreamReader的构造函数:
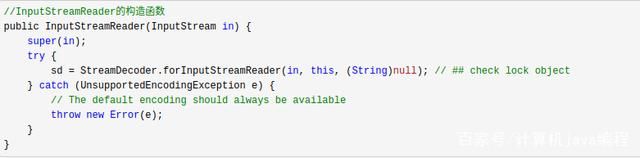
InputStreamReader还有其它几个重载构造函数,但是它们有一个共性,全都调用了sd = StreamDecoder.forInputStreamReader()方法。用它可以获得一个StreamDecoder对象。
再看后面的源码:

可见InputStreamReader中的read()和read(cbuf, offset, length)操作,实际上都是在StreamDecoder中进行。下面分析一下read()和read(cbuf, offset, length)两种情况下FileReader和BufferReader的区别。
read()
逐个读入字符
FileReader没有重写read()方法,所以相当于直接调用StreamDecoder中的read()。
而BufferReader重写了read(),如下:
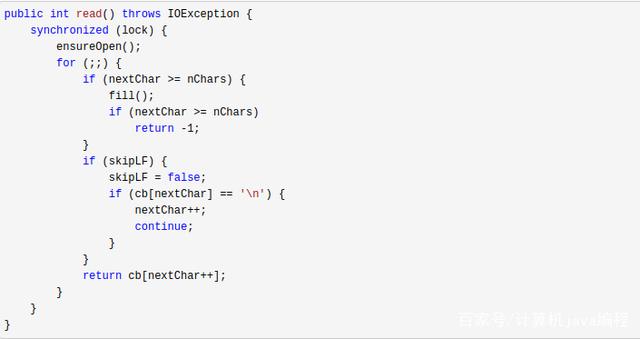
可以看到read()调用了一个fill()函数。其实精髓地方就在这个fill(),它的作用就是填充输入缓冲区。代码如下:


fill()在循环中调用了in.read(cb, dst, cb.length - dst),这实际上就是调用InputStreamReader中的read(cbuf, offset, length),即调用StreamDecoder中的read(cbuf, offset, length)。
所以,即便是一次读入一个字符,BufferReader依然是走char[]模式,性能比直接调用read()要好。
read(cbuf, offset, length)
一次读入一个char数组
注意我前一个博客中的代码是这样写的:read(cbuf),没有后面两个参数,这不用惊讶,实际上就是调用了read(cbuf, offset, length),因为在顶级父类Reader中,有如下代码:

但是注意,read(cbuf, offset, length)方法在Reader中是抽象方法,这个方法在StreamDecoder中实现。
根据源码,FileReader没有重写read(cbuf, offset, length)方法,所以相当于调用StreamDecoder中的read(cbuf, offset, length);BufferReader重写了,但也使用了fill()方法进行填充,实质上也是使用了StreamDecoder中的read(cbuf, offset, length)。
所以,使用FileReader一次读入一个char数组时,只要字符数组的大小设置合理,可以达到BufferReader的缓冲区效果。这样就解释了上篇博客测试结果。
简单总结:
InputStreamReader构造函数会创建StreamDecoder对象,在该对象中进行输入操作;BufferReader,不管是一次读入一个字符,还是一次一个数组,都会调用StreamDecoder中的read(cbuf, offset, length),即都使用了缓冲区;FileReader,逐个读取就调用read(),一次一个数组就调用read(cbuf, offset, length)。其它
StreamDecoder
StreamDecoder的源码分析可参见这个博客,分析得很好:
JAVA基础知识之StreamDecoder流
我这里就不再赘述,只提StreamDecoder中几个关键的方法:
read0():逐个读入字符的方法;read(char cbuf[], int offset, int length):调用implRead(cbuf, off, off + len);readBytes():读入底层输入的字节流;implRead():将char[]包装成字符缓冲区,调用readBytes()将数据写入字节缓冲区,然后将字节缓冲区中的字节转码成字符存入字符缓冲区。为啥都说OutputStreamWriter和InputStreamReader是字节流和字符流的桥梁,这里貌似能窥见一斑。
FileWriter与BufferWriter
输出流的分析我这里就不深入写了,跟输入流大同小异,总结成以下三点:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









