






在进行神经网络训练时,很多同学都不太注重损失函数图和损失函数的优化算法的理解,造成的结果就是:看起来效果不错,但是不知道训练的参数是否合理,也不知道有没有进一步优化的空间,也不知道初始点的选择是否恰当。本篇文章着重介绍神经网络损失函数最小化过程中使用的优化算法,前面先对梯度下降法进行介绍,后面介绍梯度下降法中使用的几种优化算法,中间穿插着自变量的更新轨迹和损失函数图像的讲解,以期同学们对损失函数相关的知识有清晰明确的认识,这是学好神经网络的基础。
梯度下降法
梯度下降法是最原始的对模型的参数向量进行更新的方法,它的目标函数是训练数据集中有关各个样本的损失函数的平均。设
目标函数在
模型的参数向量更新:
例如,对于目标函数
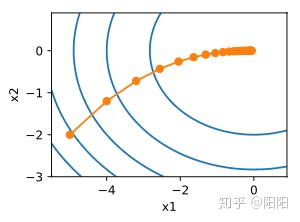
可以看到自变量的迭代轨迹与等高线是垂直的,说明迭代一直朝着梯度的反方向进行(直达目的地)。但是梯度下降法每次更新模型参数需要对所有样本计算梯度,所以每次自变量迭代的计算开销为
随机梯度下降法
为了减少计算的开销,采用了随机梯度下降(SGD)方法。在随机梯度下降的每次迭代中,我们随机均匀采样的一个样本索引
我们的目标是把所有样本的损失降到一个极小值,但是这种方式只能把一个样本的损失给降低,那么这样能达到我们的目标吗?可以证明:经过很多次的迭代之后随机梯度下降能达到梯度下降相同的效果,也就是说随机梯度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









